- Encoder:
- 本身其实就是一连串的卷积网络。该网络主要由卷积层,池化层和BatchNormalization层组成。
- 卷积层负责获取图像局域特征,池化层对图像进行下采样并且将尺度不变特征传送到下一层,而BN主要对训练图像的分布归一化,加速学习。
- 概括地说,encoder对图像的低级局域像素值进行归类与分析,从而获得高阶语义信息(“汽车”, “马路”,“行人”),Decoder收集这些语义信息,并将同一物体对应到相应的像素点上,每个物体都用不同的颜色表示。
- Decoder:
- 既然Encoder已经获取了所有的物体信息与大致的位置信息,那么下一步就需要将这些物体对应到具体的像素点上
- Decoder对缩小后的特征图像进行上采样,然后对上采样后的图像进行卷积处理,目的是完善物体的几何形状,弥补Encoder当中池化层将物体缩小造成的细节损失。

一些网络架构明确旨在利用神经网络的这种能力来学习有效的表示。他们使用编码器网络将原始输入映射到特征表示,使用解码器网络将此特征表示作为输入,处理它以做出决定,并产生输出。这称为编码器 - 解码器网络。
理论上,编码器和解码器部件可以彼此独立地使用。例如,编码器RNN可用于将传入电子邮件的特征编码为“特征向量”,然后将其用于预测电子邮件是否是垃圾邮件。然而,由于在各种任务上的良好性能,神经编码器和解码器经常一起使用。
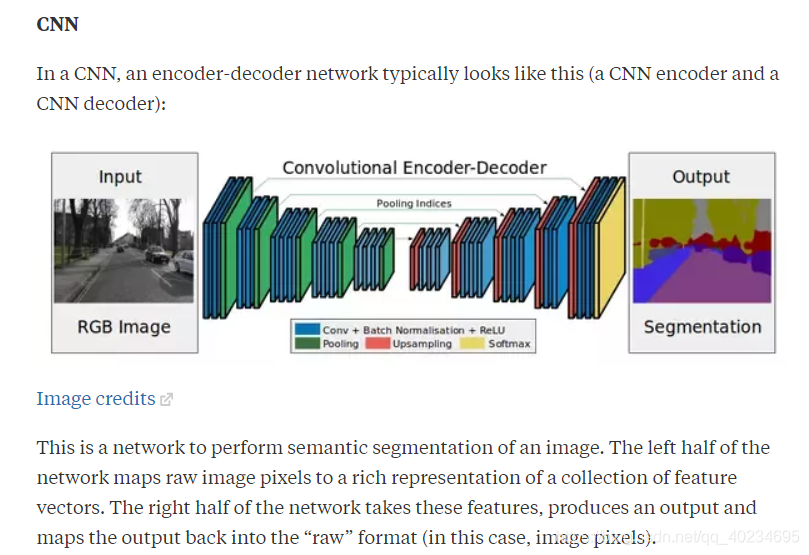
在CNN中,编码器 - 解码器网络通常看起来像这样(CNN编码器和CNN解码器):
这是执行图像的语义分割的网络。网络的左半部分将原始图像像素映射到特征向量集合的丰富表示。网络的右半部分采用这些功能,产生输出并将输出映射回“原始”格式(在本例中为图像像素)。
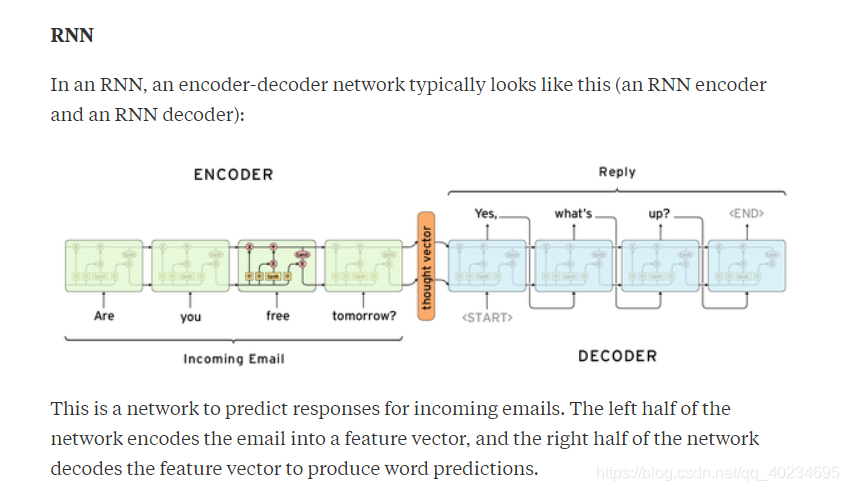
在RNN中,编码器 - 解码器网络通常看起来像这样(RNN编码器和RNN解码器):
这是一个预测传入电子邮件响应的网络。网络的左半部分将电子邮件编码为特征向量,网络的右半部分对特征向量进行解码以产生字预测
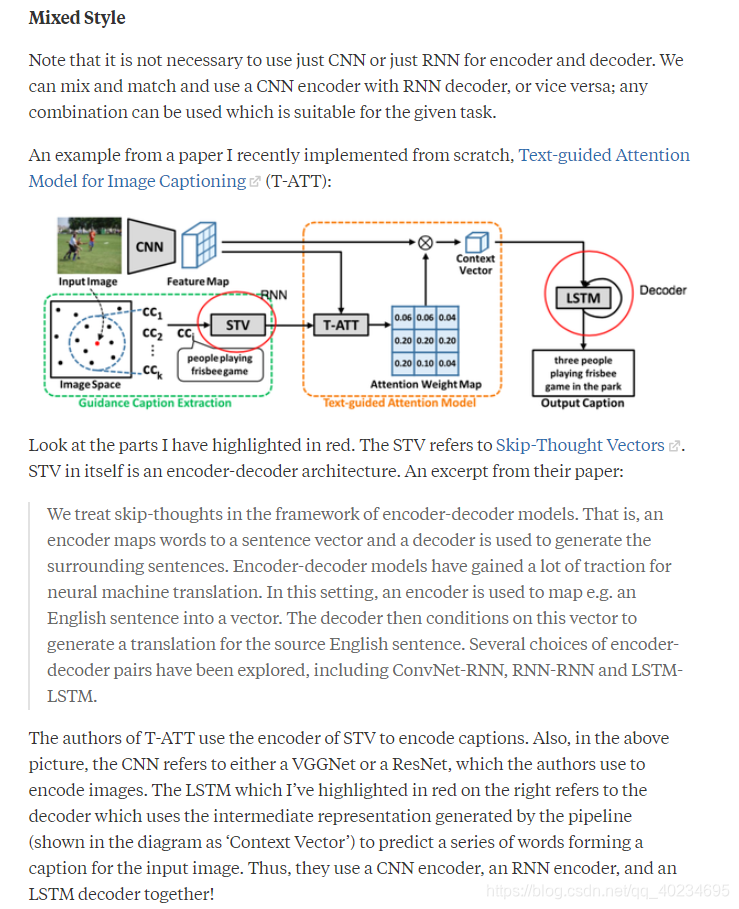
混合风格:
注意,没有必要仅使用CNN或仅使用RNN作为编码器和解码器。我们可以将CNN编码器与RNN解码器混合搭配使用,反之亦然; 可以使用适合于给定任务的任何组合。
看看我用红色突出显示的部分。STV指的是Skip-Thought Vectors。STV本身就是编码器 - 解码器架构。摘自他们的论文:
我们在编码器 - 解码器模型的框架中处理跳过思想。也就是说,编码器将单词映射到句子向量,并且解码器用于生成周围的句子。编码器 - 解码器模型已经为神经机器翻译获得了很多牵引力。在该设置中,编码器用于将例如英语句子映射到矢量中。然后,解码器对该向量进行调节以生成源英语句子的翻译。已经探索了编码器 - 解码器对的若干选择,包括ConvNet-RNN,RNN-RNN和LSTM-LSTM。
T-ATT的作者使用STV的编码器来编码字幕。此外,在上图中,CNN指的是VGGNet或ResNet,作者用它们来编码图像。我在右边以红色突出显示的LSTM指的是使用由管道生成的中间表示的解码器(在图中显示为“上下文矢量”)来预测形成输入图像的字幕的一系列单词。因此,他们一起使用CNN编码器,RNN编码器和LSTM解码器!
