1.编码器—解码器(seq2seq)
编码器的作用是把一个不定长的输入序列变换成一个定长的背景变量c,并在该背景变量中编码输入序列信息。常用的编码器是循环神经网络。
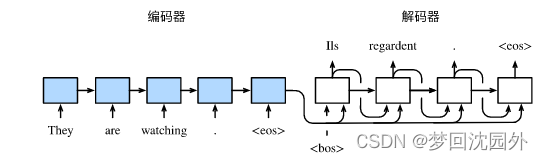
编码器可以是一个单向的循环神经网络,每个时间步的隐藏状态只取决于该时间步及之前的输入子序列。我们也可以使用双向循环神经网络构造编码器。在这种情况下,编码器每个时间步的隐藏状态同时取决于该时间步之前和之后的子序列(包括当前时间步的输入),并编码了整个序列的信息。
编码器是没有输出的RNN,编码器最后时间状态的隐状态用于解码器的初始隐状态。
编码器输出的背景变量$\boldsymbol{c}$编码了整个输入序列x1,……,xT的信息。给定训练样本中的输出序列y1, y2, ……, yT,对每个时间步t(符号与输入序列或编码器的时间步t有区别),解码器输出的条件概率将基于之前的输出序列
和背景变量c,即
。
为此,我们可以使用另一个循环神经网络作为解码器。在输出序列的时间步,解码器将上一时间步的输出
以及背景变量
作为输入,并将它们与上一时间步的隐藏状态
变换为当前时间步的隐藏状态
。因此,我们可以用函数g表达解码器隐藏层的变换:
有了解码器的隐藏状态后,我们可以使用自定义的输出层和softmax运算来计算$),例如,基于当前时间步的解码器隐藏状态
、上一时间步的输出
以及背景变量c来计算当前时间步输出
的概率分布。
解码器的输入:
训练:真正的句子
推理:上一个时段的输出
编码器和解码器常用BLUE作为衡量生成序列的好坏。
2.集束搜索
在准备训练数据集时,我们通常会在样本的输入序列和输出序列后面分别附上一个特殊符号"<eos>"表示序列的终止。,假设解码器的输出是一段文本序列。设输出文本词典(包含特殊符号"<eos>")的大小为
,输出序列的最大长度为T'。所有可能的输出序列一共有
种。这些输出序列中所有特殊符号"<eos>"后面的子序列将被舍弃。
(1)贪婪搜索
对于输出序列任一时间步$t'$,我们从$|\mathcal{Y}|$个词中搜索出条件概率最大的词作为输出。一旦搜索出"<eos>"符号,或者输出序列长度已经达到了最大长度$T'$,便完成输出。
(2)穷举搜索
穷举所有可能的输出序列,输出条件概率最大的序列。
计算开销很容易过大
(3)束搜索
每次选取当前时间步条件概率最大的k个词,最终,我们从各个时间步的候选输出序列中筛选出包含特殊符号“<eos>”的序列,并将它们中所有特殊符号“<eos>”后面的子序列舍弃,得到最终候选输出序列的集合。
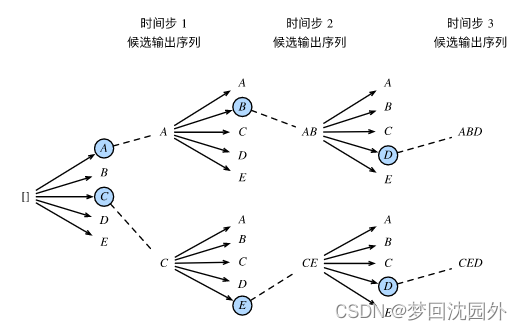
在最终候选输出序列的集合中,我们取以下分数最高的序列作为输出序列:
其中L为最终候选序列长度,一般可选为0.75。分母上的
是为了惩罚较长序列在以上分数中较多的对数相加项。分析可知,束搜索的计算开销为
。这介于贪婪搜索和穷举搜索的计算开销之间。此外,贪婪搜索可看作是束宽为1的束搜索。束搜索通过灵活的束宽$k$来权衡计算开销和搜索质量。