输入和输出都可以是不定长序列,例如机器翻译、图像描述
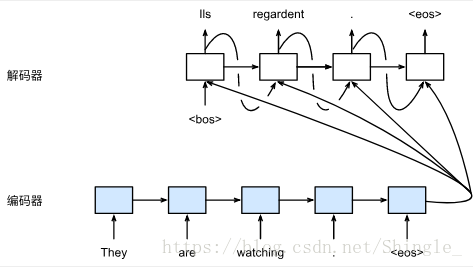
在训练数据集中,我们可以在每个句子后附上特殊符号“”(end of sequence)表示序列的终止。
编码器
编码器的作用是把一个不定长的输入序列变换成一个定长的背景变量 c,并在该背景变量中编码输入序列信息。常用的编码器是循环神经网络。
循环神经网络隐藏层的变换:
通过自定义函数 q 将各个时间步的隐藏状态变换为背景变量:
例如,当选择 时,背景变量是输入序列最终时间步的隐藏状态
编码器也可以时双向RNN,需要注意的是,编码器和解码器通常需要使用多层循环神经网络。(可以是多种多样的,网络结构以及自定义函数q)
class Encoder(nn.Block):
def __init__(self, num_inputs, embed_size, num_hiddens, num_layers,
drop_prob, **kwargs):
super(Encoder, self).__init__(**kwargs)
self.embedding = nn.Embedding(num_inputs, embed_size)
self.dropout = nn.Dropout(drop_prob)
self.rnn = rnn.GRU(num_hiddens, num_layers, dropout=drop_prob,
input_size=embed_size)
def forward(self, inputs, state):
embedding = self.embedding(inputs).swapaxes(0, 1)
embedding = self.dropout(embedding)
output, state = self.rnn(embedding, state)
return output, state
def begin_state(self, *args, **kwargs):
return self.rnn.begin_state(*args, **kwargs)解码器
解码器的最初时间步输入来自“”符号。对于一个输出中的序列,当解码器在某一时间步搜索出“”符号时,即完成该输出序列。

编码器输出的背景变量 编码了整个输入序列 的信息。给定训练样本中的输出序列 ,对每个时间步 ,解码器输出 的条件概率将基于之前的输出序列 和背景变量 ,即
我们可以使用另一个循环神经网络作为解码器。 在输出序列的时间步 ,解码器将上一时间步的输出 以及背景变量 作为输入,并将它们与上一时间步的隐藏状态 变换为当前时间步的隐藏状态 。因此,我们可以用函数 g (循环神经网络单元)表达解码器隐藏层的变换:
注意力机制(Attention)
上述的seq2seq解码器设计中,输出序列的各个时间步使用了相同的背景变量。如果解码器的不同时间步可以使用不同的背景变量呢?
在时间步 ,设解码器的背景变量为 ,输出 的特征向量为 。 和输入的特征向量一样,这里每个输出的特征向量也是模型参数。解码器在时间步 的隐藏状态
class Decoder(nn.Block):
def __init__(self, num_hiddens, num_outputs, num_layers, max_seq_len,
drop_prob, alignment_size, encoder_num_hiddens, **kwargs):
super(Decoder, self).__init__(**kwargs)
self.max_seq_len = max_seq_len
self.encoder_num_hiddens = encoder_num_hiddens
self.hidden_size = num_hiddens
self.num_layers = num_layers
self.embedding = nn.Embedding(num_outputs, num_hiddens)
self.dropout = nn.Dropout(drop_prob)
# 注意力机制。
self.attention = nn.Sequential()
self.attention.add(
nn.Dense(alignment_size,
in_units=num_hiddens + encoder_num_hiddens,
activation='tanh', flatten=False))
self.attention.add(nn.Dense(1, in_units=alignment_size,
flatten=False))
self.rnn = rnn.GRU(num_hiddens, num_layers, dropout=drop_prob,
input_size=num_hiddens)
self.out = nn.Dense(num_outputs, in_units=num_hiddens,
flatten=False)
self.rnn_concat_input = nn.Dense(
num_hiddens, in_units=num_hiddens + encoder_num_hiddens,
flatten=False)
def forward(self, cur_input, state, encoder_outputs):
# 当循环神经网络有多个隐藏层时,取最靠近输出层的单层隐藏状态。
single_layer_state = [state[0][-1].expand_dims(0)]
encoder_outputs = encoder_outputs.reshape((self.max_seq_len, -1,
self.encoder_num_hiddens))
hidden_broadcast = nd.broadcast_axis(single_layer_state[0], axis=0,
size=self.max_seq_len)
encoder_outputs_and_hiddens = nd.concat(encoder_outputs,
hidden_broadcast, dim=2)
energy = self.attention(encoder_outputs_and_hiddens)
batch_attention = nd.softmax(energy, axis=0).transpose((1, 2, 0))
batch_encoder_outputs = encoder_outputs.swapaxes(0, 1)
decoder_context = nd.batch_dot(batch_attention, batch_encoder_outputs)
input_and_context = nd.concat(
nd.expand_dims(self.embedding(cur_input), axis=1),
decoder_context, dim=2)
concat_input = self.rnn_concat_input(input_and_context).reshape(
(1, -1, 0))
concat_input = self.dropout(concat_input)
state = [nd.broadcast_axis(single_layer_state[0], axis=0,
size=self.num_layers)]
output, state = self.rnn(concat_input, state)
output = self.dropout(output)
output = self.out(output).reshape((-3, -1))
return output, state
def begin_state(self, *args, **kwargs):
return self.rnn.begin_state(*args, **kwargs)trick:可以用编码器的隐藏状态(h)初始化解码器的隐藏状态(s)。
class DecoderInitState(nn.Block):
def __init__(self, encoder_num_hiddens, decoder_num_hiddens, **kwargs):
super(DecoderInitState, self).__init__(**kwargs)
self.dense = nn.Dense(decoder_num_hiddens,
in_units=encoder_num_hiddens,
activation="tanh", flatten=False)
def forward(self, encoder_state):
return [self.dense(encoder_state)]分别实例化编码器、解码器和解码器初始隐藏状态网络
encoder = Encoder(len(input_vocab), encoder_embed_size, encoder_num_hiddens,
encoder_num_layers, encoder_drop_prob)
decoder = Decoder(decoder_num_hiddens, len(output_vocab),
decoder_num_layers, max_seq_len, decoder_drop_prob,
alignment_size, encoder_num_hiddens)
decoder_init_state = DecoderInitState(encoder_num_hiddens,
decoder_num_hiddens)模型训练
根据最大似然估计,我们可以最大化输出序列基于输入序列的条件概率
并得到该输出序列的 损失
预测不定长序列的方法包括穷举搜索、贪婪搜索和束搜索。
束搜索(Beam Search)
设输出文本词典 (包含特殊符号“”)的大小为 ,输出序列的最大长度为 。所有可能的输出序列一共有 种。这些输出序列中所有特殊符号“”后面的子序列将被舍弃。
为了找到生成概率最大的输出序列,一种方法是计算所有可能序列的生成概率,并输出概率最大的序列(最优序列),但是这种方法计算开销太大。这也称为 穷举搜索(exhaustive search) 。
贪婪搜索(greedy search):对于输出序列任一时间步 ,从 个词中搜索出输出词
且一旦搜索出“”符号即完成输出序列。贪婪搜索的计算开销是 O(|Y|T′)。它比起穷举搜索的计算开销显著下降。 贪婪搜索也无法保证找出条件概率最大的最优序列
束搜索(beam search) 是比贪婪搜索更加广义的搜索算法。它有一个束宽(beam size)超参数。我们将它设为 k。在时间步 1 时,选取当前时间步生成条件概率最大的 k 个词,分别组成 k 个候选输出序列的首词。在之后的每个时间步,基于上个时间步的 k 个候选输出序列,从 k|Y| 个可能的输出序列中选取生成条件概率最大的 k 个,作为该时间步的候选输出序列。
最终,我们在各个时间步的候选输出序列中筛选出包含特殊符号“”的序列,并将它们中所有特殊符号“”后面的子序列舍弃,得到最终候选输出序列。在这些最终候选输出序列中,取以下分数最高的序列作为输出序列:
其中 L 为最终候选序列长度,α 一般可选为 0.75。分母上的 是为了惩罚较长序列在以上分数中较多的对数相加项。分析可得,束搜索的计算开销为 O(k|Y|T′) 。这介于穷举搜索和贪婪搜索的计算开销之间。
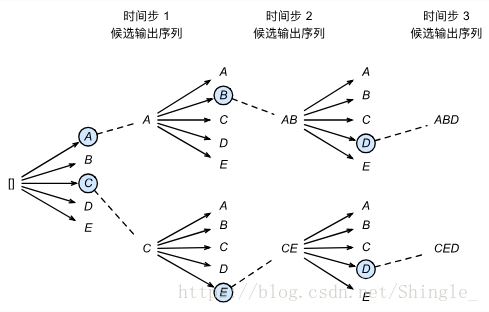
贪婪搜索可看作是束宽为 1 的束搜索。束搜索通过更灵活的束宽 k 来权衡计算开销和搜索质量
[1] Cho, K., Van Merri ë nboer, B., Gulcehre, C., Bahdanau, D., Bougares, F., Schwenk, H., & Bengio, Y. (2014). Learning phrase representations using RNN encoder-decoder for statistical machine translation. arXiv preprint arXiv:1406.1078.
[2] Sutskever, I., Vinyals, O., & Le, Q. V. (2014). Sequence to sequence learning with neural networks. In Advances in neural information processing systems (pp. 3104-3112).
[3] Bahdanau, D., Cho, K., & Bengio, Y. (2014). Neural machine translation by jointly learning to align and translate. arXiv preprint arXiv:1409.0473.
https://zh.gluon.ai/chapter_natural-language-processing/index.html