Attention的结构
Seq2seq是一个非常强大的框架,应用面很广,这里我们将介绍进一步强化seq2seq的注意力机制,基于attention机制,seq2seq可以像我们人类一样,将注意力集中在必要的信息上,
seq2seq存在的问题,
Seq2seq中使用编码器对时序数据进行编码,然后将编码信息传递给解码器,此时,解码器的输出是在固定长度的向量,实际上,固定长度的向量存在很大的问题,因为固定长度的向量意味着,无论输出语句的长度如何(无论多长),都会被转换为长度相同的向量,
无论多长文本你,当前的编码器都会将其转换为固定长度的向量,就像把一大推西装塞到衣柜里一样,编码器会强行把信息塞入固定长度的向量中,但是,这样做早晚会遇到瓶颈,将像是最终西装会从衣柜中掉出来一样,有用的而信息也会从向量中溢出,
现在我们就来改进seq2seq,首先改进编码器,然后改进解码器
编码器的改进
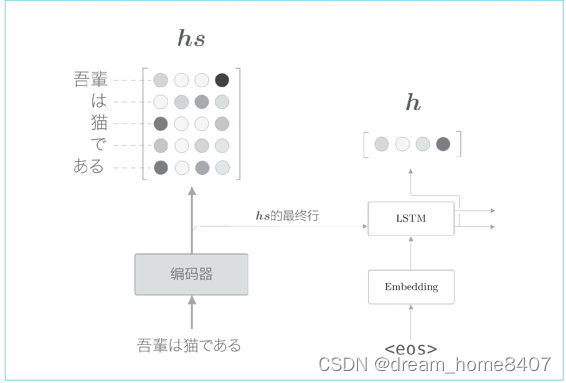
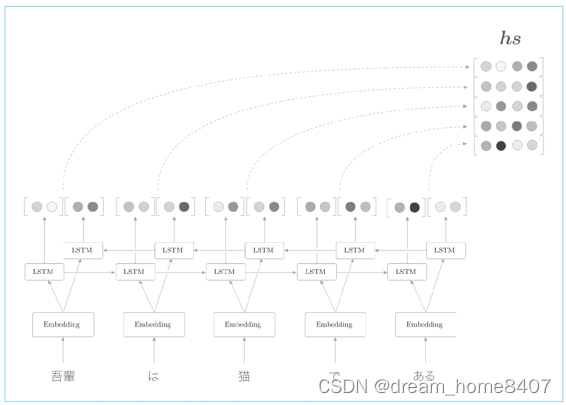
到目前为止,我们都只将lstm层的最后隐藏状态传给解码器,但是编码器的输出的长度应该根据输入文本的长度相应地改变,这是编码器的一个可以改进的地方,具体而言,使用各个时刻的lstm层的隐藏状态
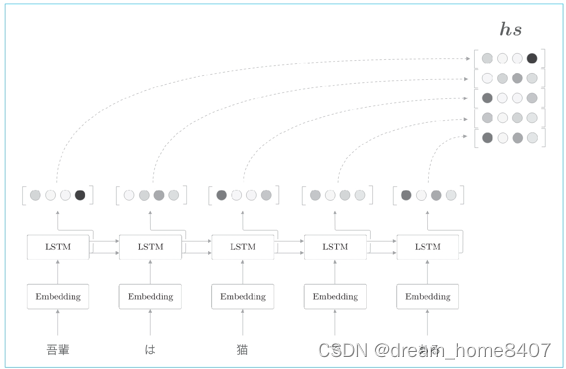
使用各个时刻的lstm层的隐藏状态这里表示为hs,可以获得输入单词相同数量的向量,输入了5个单词,此时编码器输出5个向量,这样一来,编码器就拜托了一个固定长度向量的机制,在许多深度学习框架中,在初始化RNN层时,可以选择是返回全部时刻隐藏状态向量,还是返回最后时刻的隐藏状态向量,
各个时刻的lstm层的隐藏状态都充满了什么信息,有一点可以确定的是,各个时刻的隐藏状态中包含了大量当前时刻输入单词的信息,比如输入猫时的lstm层的输出受此时输入的单词猫的影响最大,因此可以认为这个隐藏状态向量蕴含许多猫的成分,按照这样理解,编码器输出的hs矩阵就可以视为各个单词对应的向量集合
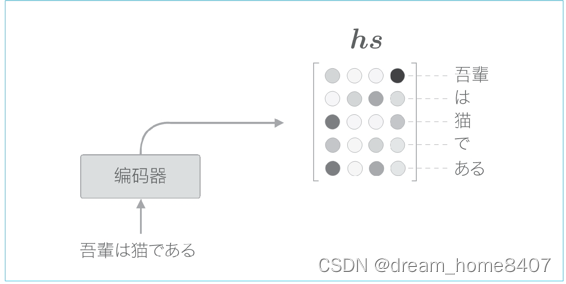
编码器是从左向右处理的,当前单词向量中包含有到当前时刻前几个单词的信息,考虑整体的平衡性,从两个方向处理时序数据的双向RNN或者双向的LSTM比较有效,
总结:对编码器的改进,只是将编码器的全部时刻隐藏状态取出来而已,通过这个小的改动,解码器可以根据输入语句的长度,成比例地编码信息
解码器的改进
编码器整体输出各个单词对应的lstm层的隐藏状态向量hs,然后这个hs被传递给解码器,以进行时间序列的转换,
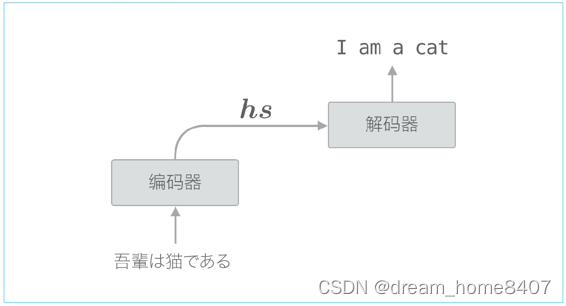
仅将编码器的最后隐藏状态向量传递给解码器,具体来说是将编码器lstm层的最后隐藏状态放入了解码器的lstm层最初的隐藏状态,
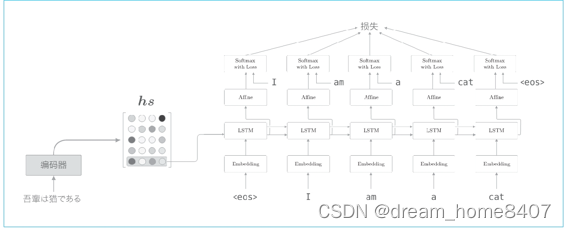
我们改进解码器,以便能够使用全部的hs
在机器翻译的历史中,怎么处理输入和输出中哪些单词与哪些单词有关,很多研究都利用猫=cat这样的单词对应关系的知识,这样的表示单词对应关系的信息成为对齐,最早之前的对齐多是手工完成的,接下来介绍attention技术则成功地嫁给你对齐思想自动以内到seq2seq中,这也是手工操作到机械自动化的演变,
我们的目标是找出与翻译目标词有对应关系的翻译源词信息,然后利用这个信息进行翻译,这就是说,我们的目标是仅关注必要的信息,并根据这个信息进行时序转换,这种机制称之为attention
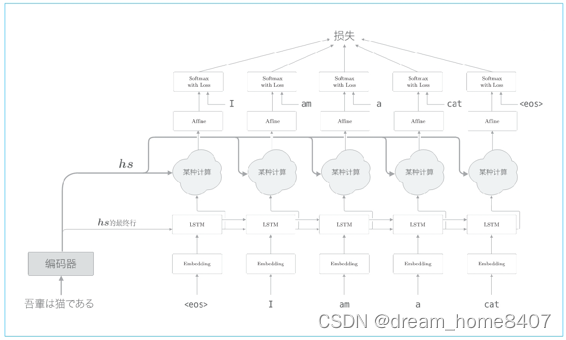
我们新增一个进行某种计算的层,这个某种计算接收解码器各个时刻lstm层隐藏状态和编码器的hs,然后从中选出必要的信息,并输出到affine全连接层,与之前一样,编码器的最后的隐藏状态向量传递给解码器最初的lstm层

如上图网络所作的工作是提取单词对齐信息,具体来说,就是从hs中选出与各个时刻解码器输出单词有对应关系的单词向量,比如当解码器输出I时,从hs中选出吾的对应向量,也就是说我们希望通过某种计算来实现这种选择操作,不过这里有个问题,就是选择(从多个事物中选取若干个)这一操作是无法进行微分计算的
神经网络的学习一般通过误差反向传播算法,因此,如果可以微分地运算结构网络,就可以在误差反向传播的框架中进行学习,而如果不使用可微分的运算,基本上也没办法进行使用误差反向传播法,
可否将选择这一操作换成可微分运算呢,实际上,解决这个问题的思路很简单,就像哥伦布蛋一样,第一个想到是很难的,要打破常规,这个思路就是,与其单选,不如多选,我们惊醒计算表示各个单词重要度的权重
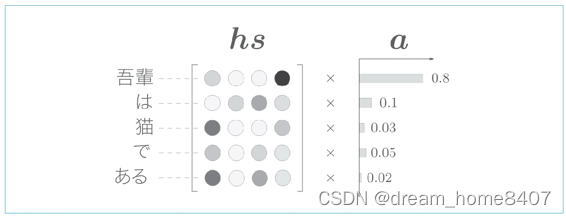
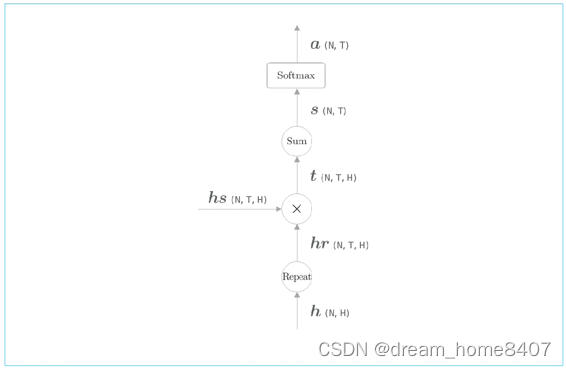
则行里使用表示各个单词重要度的权重(记作a),此时a像的概率分布一样,各个元素是0.0~1.0的标量,总和是1,然后,计算这个表示各个单词重要度的权重hs的加权和,可以获得目标向量,
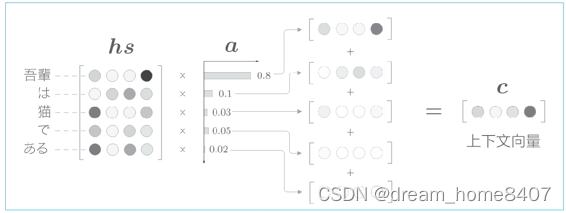
计算单词向量的加权和,这里将结果称为上下文向量,记作符号c表示,顺便说一下,如果我们仔细观察,就可以发现吾对应权重为0.8,这就意味着上下文向量c中含有很多吾向量的成分,可以说这个加权和基本代替了选择向量这个操作,加色和吾对应的权重是1,那么其他单词对应的权重是0,这就相当于选择了吾向量,上下文向量c中包含了当前时刻进行变换所需的信息,更确切的说,模型要从数据中学习到这种能力,
解码器的改进
表示个各个单词重要度的权重a,就可以通过加权和获得上下文向量,那么怎么求这个a呢,当然不需要我们手动指定,我们只需要做好让模型从数据中自动学习它的准备工作
各个单词的权重a的求解方法,首先从编码器的处理开始到解码器第一个lstm层输出隐藏状态向量的处理为止的流程图
用h表示解码器中lstm层隐藏状态向量,此时,我们的目标是用数值表示这个h在多大程度上和hs的的各个单词向量相似有几种方法可以做到这一点,我们使用最简单的向量内积,计算向量相似度的方法有好几种,除了内积外,还有使用小型神经网络输出得分的做法
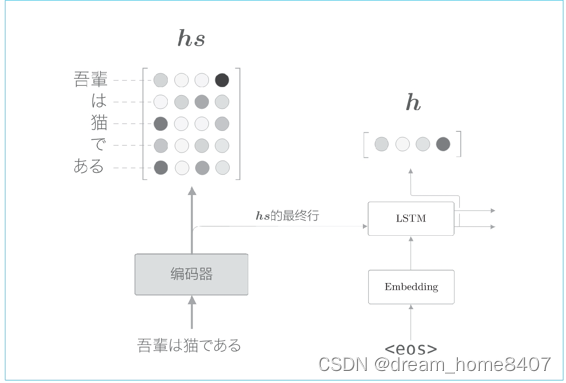
这里通过内积计算hs的各行与h的相似度
这里通过向量内积算出h和hs的各个单词向量之间的相似度,并将其结果表示为s,不过,这个s是正则化之前的值,也称为得分,接下来使用老一套的softmax函数对s进行正则化
这里的计算图由repeat节点,表示对应元素乘积的X节点,sum节点和softmax层构成
解码器的改进3
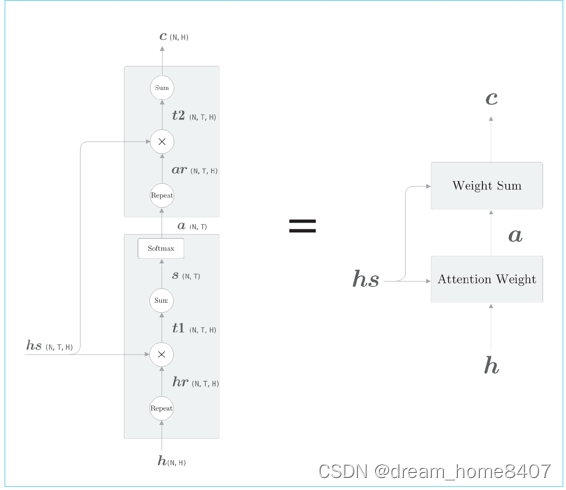
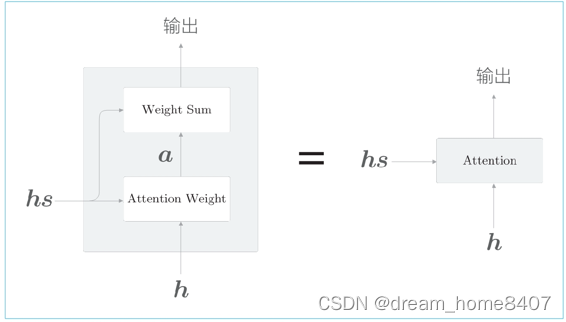
计算上下文向量的计算图
上如显示了用于获取上下文向量c的计算图全貌,我们已经分为weight sum层和attention weight层进行实现,重申一i西安,这里进行的计算是attention weight层仅关注编码器输出的各个单词向量hs,并九三各个单词的权重a,然后weight sum层计算a和hs的加权和,并输出上下文向量c,我们将一系列计算的层称为attention层
在这里插入图片描述
整体的结构如下图
如上图所示,解码器的输出hs被输入到各个时刻的attention层,另外这里将lstm层的隐藏状态向量输入affine层,再将解码器进行改进,我们将attention信息添加到上一章的解码器上
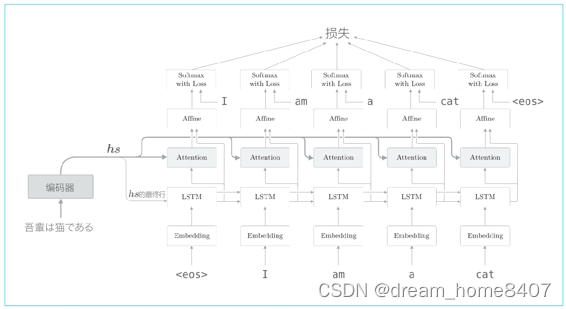
带attention的seq2seq的实现
双向LSTM
双向lstm在之前的lstm层添加了一个反方向处理的lstm层,然后拼接各个时刻的两个lstm层的隐藏状态,最后将其作为最后的隐藏状态向量
通过这样的双向处理,各个单词对应的隐藏状态向量可以从两个方向聚合信息,这样一来,这些向量就编码了更加均衡的信息
双向lstm的实现非常简单,一种实现方式是准备两个lstm层,并调整输出各个层的单词的排列,具体而言,其中一个层的输入语句与之前相同,另一个lstm层的输入语句则按照从右到左顺序输入,之后拼接两个lstm层的输出,就可以创建双向的lstm层
Seq2seq的深层化
需要解决的问题更加复杂,这种情况下,我么希望待attenton的seq2seq具有更强的表现力,此时考虑到的是加深RNN层,lstm层,通过加深层,可以创建表现力更强的模型,
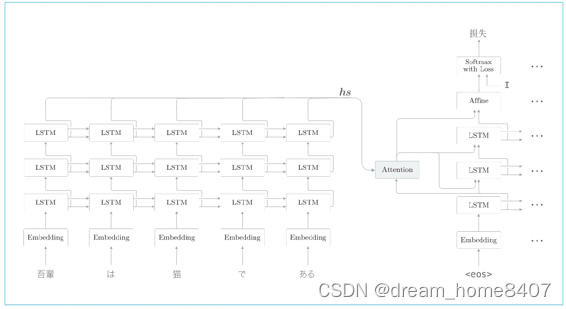
如图使用了3层lstm层带attention的seq2seq,解码器和编码器中通常使用层数相同的lstm层,另外,attention层使用方法由许多种变体,这里将解码器lstm层的隐藏状态输入到attention层,然后将上下文向量attention层的输出,传给解码器的多个层(lstm层和affine层)
另外,加深层使用到另一个额中啊哟技巧是残差链接这是一种跨层链接的简单技巧
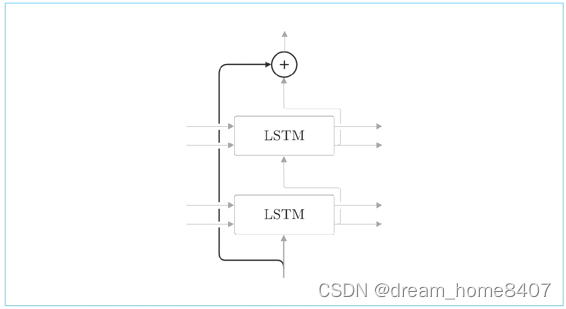
所谓残差链接,就是跨层来凝结,在残差链接的链接处,在两个残差链接处有两个输出被相加,,请注意这个加法,确切来说,是对应元素加法,这个加法很重要,因为加法在反向传播时,会按照原样传播梯度,所以残差链接中的梯度可以不搜任何影响地传播到前一层,这样一来,即便加深了层,梯度也能正常传播,而不会发生梯度消失或者梯度爆炸,学习可以顺利进行
在时间方向上,RNN层的反向传播会出现梯度消失或者梯度爆炸问题,梯度消失可以通过lstm,gru等应对,梯度爆照可以通过梯度裁剪应对,而对于深度方向上的梯度消失,这里介绍残差连接很有效
transformer
到目前为止,我们使用RNN,从语言模型到文本生产,从seq2seq到带Attention的seq2seq及组成部分,使用RNN都可以很好地处理可变长序列的时序数据,但是RNN也有缺点,比如并行处理问题,
RNN需要基于上一时刻的计算结果逐步及进行计算的,因此基本不可能在时间方向上并行计算RNN,使用GPU的并行计算进行深度学习时,这一点会成为很大的瓶颈,于是我们就有避开RNN的动机
Transformer是在Attention is all you need 这篇论文中提出的方法,如论文标题所示,Transformer不用 RNN ,而是用attention进行处理,这里我们简单看一下这个transformer
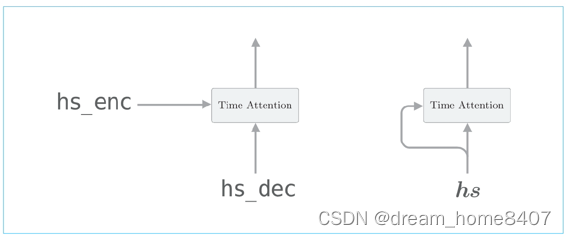
左图是常规的attention,右图是self attention
在此之前,我们用attention求解了翻译这两种时序数据之间的对应关系,左图情况attention层的两个输入中输入的是不同的时序数据,与之相对,右图self-attention的两个输入中输入的是同一个时序数据,像这样,可以求得一个时序数据内各个元素之间的对应关系,
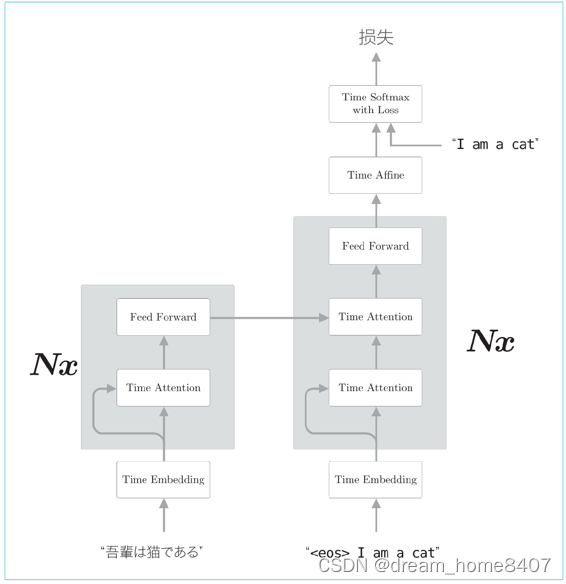
Transformer的层结构
Transformer中用attention代替RNN,实际上,编码器和解码器两者都使用self attention,上图中feed-forward层表示前馈神经网络,激活函数为Relu的全连接的神经网络,另外,图中Nx表示灰色部分背景包围的元素被堆叠N次,
上图简化了Transformer,实际上,处理这个架构外,残差连接,layer normalization等技巧也会被用到,其他常见的技巧还有,并行使用多个attention,编码时序数据的位置信息等
使用transformer可以控制计算量,充分利用gpu并行计算带来的好处,
总结
在翻译,语音识别等将一个时序数据转换为另一个时序数据的任务中,时序数据之间常常存在对应关系,
Attention从数据中学习两个时序数据之间的对应关系
Attention使用向量内积计算向量之间的相似度,并输出这个相似度的加权向量
因为attention中使用的运算是可微分的,因此可以基于误差反向传播法进行学习,
通过将attention计算处的权重可视化,可以观察输入与输出之间的对应关系,