1.1 什么是聚类分析
聚类(Clustering):
- 聚类是一个将数据集划分为若干组 (class)或类
(cluster)的过程,并使得同一个组内的数据对象具有较高的相似度:而不同组中的数据对象是不相似的。 - 相似或不相似是基于数据描述属性的取值来确定的,通常利用各数据对象间的距离来进行表示。
- 聚类分析尤其适合用来探讨样本间的相互关联关系从而对一个样本结构做一个初步的评价。
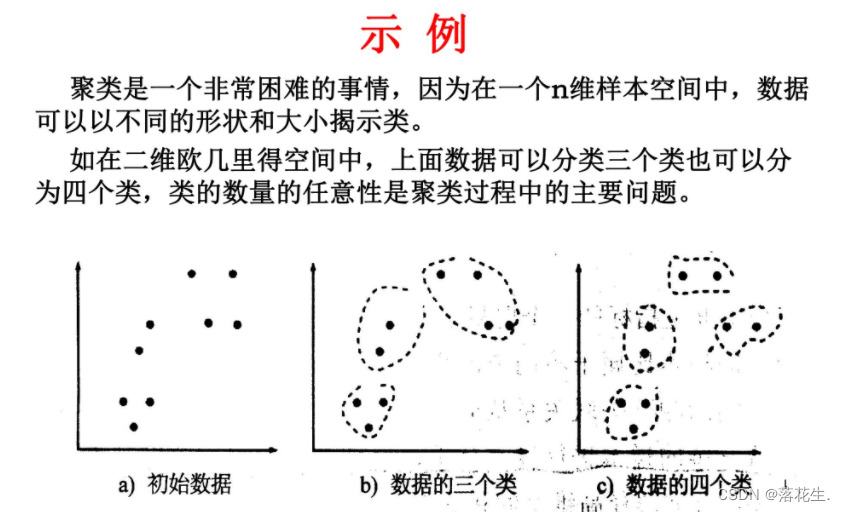
聚类与分类的区别:
聚类是一 种无(教师)监督的学习方法。与分类不同,其不依赖于事先确定的数据类别,以及标有数据类别的学习训练样本集合
因此,聚类是观察式学习,而不是示例式学习。
聚类分析的应用:
市场分析:帮助市场分析人员从客户基本库中发现不同的客户群,并用购买模式刻画不同的客户群的特征;
万维网:对WEB日志的数据进行聚类, 以发现相同的用户访问模式;
图像处理;
模式识别;
孤立点检测等。


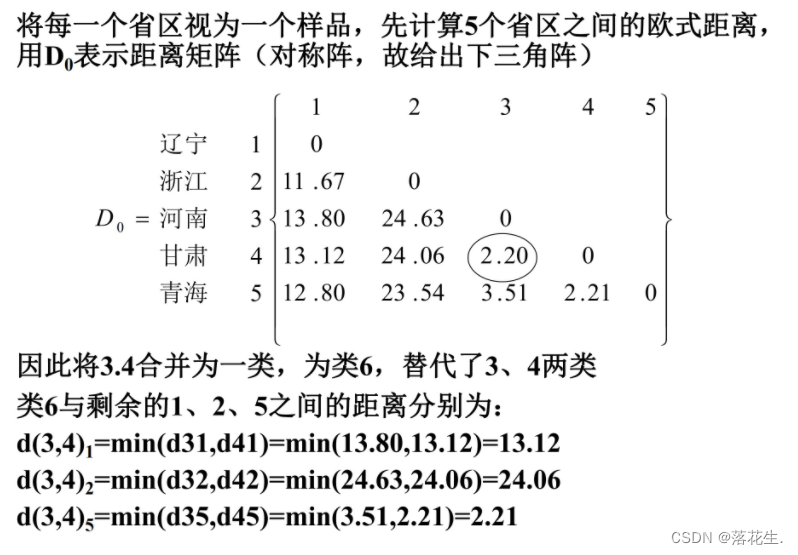
1.2 样品间的相似度量—距离


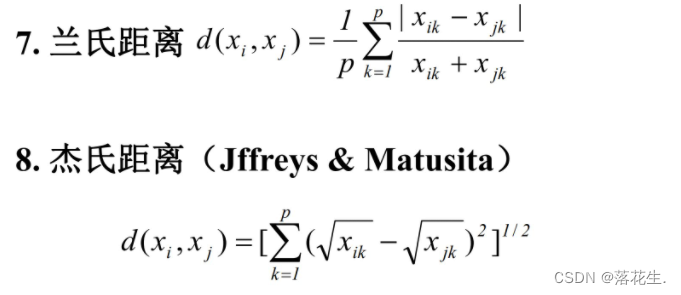
欧氏距离使用最多
按照不同的距离公式,会造成不同的分类结果
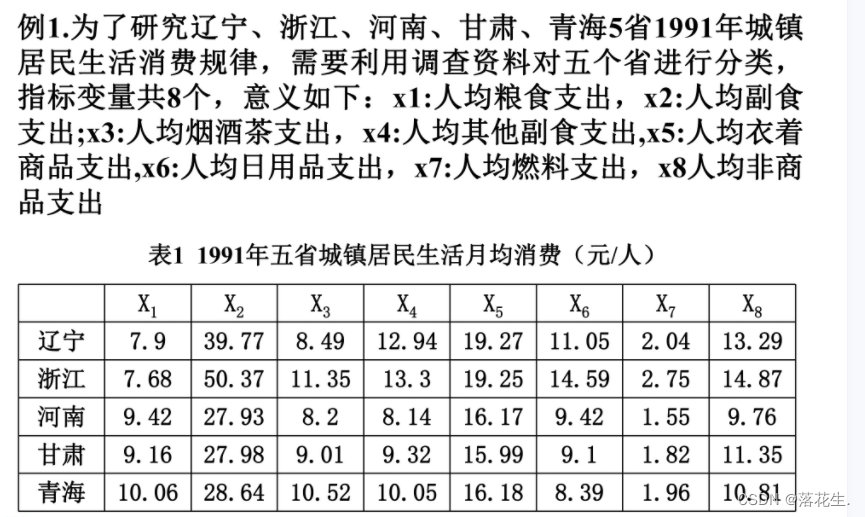
1.3变量间的相似度量——相似系数

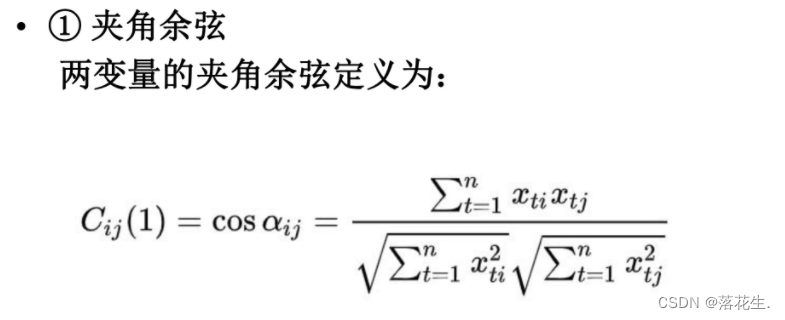

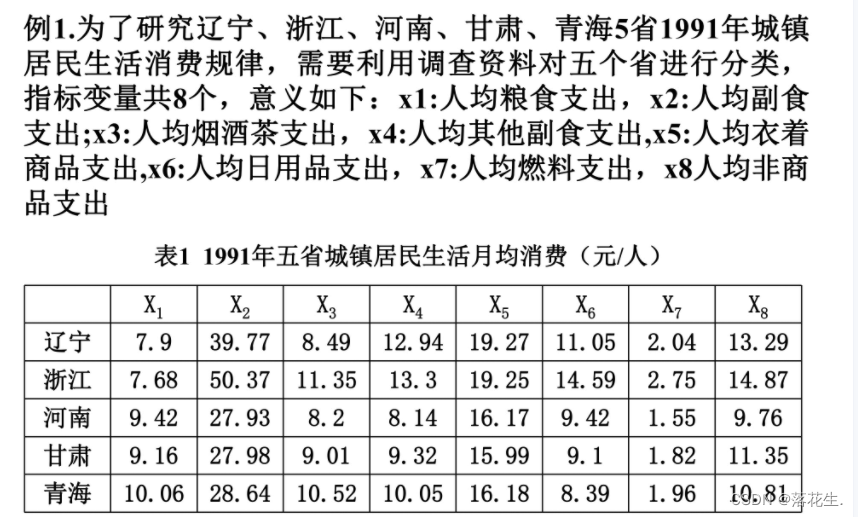
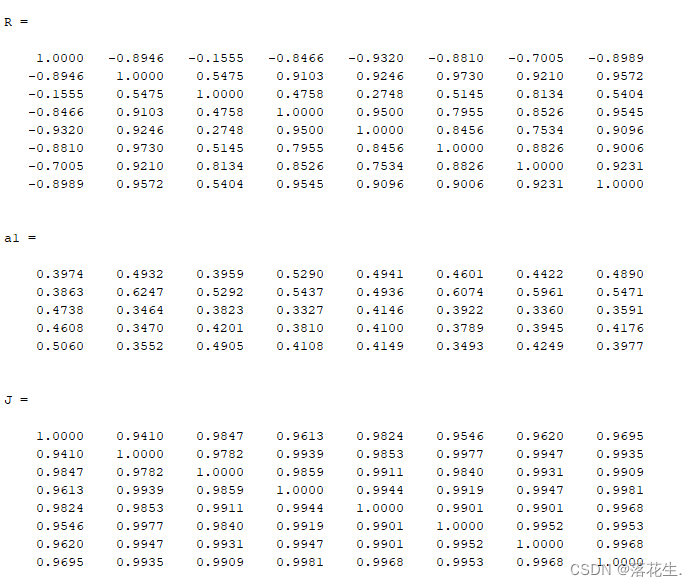
以例一的数据为例计算出各指标之间的相关系数与夹角余弦
a=[7.9 39.77 8.49 12.94 19.27 11.05 2.04 13.29
7.68 50.37 11.35 13.3 19.25 14.59 2.75 14.87
9.42 27.93 8.2 8.14 16.17 9.42 1.55 9.76
9.16 27.98 9.01 9.32 15.99 9.1 1.82 11.35
10.06 28.64 10.52 10.05 16.18 8.39 1.96 10.81];
R=corrcoef(a)%指标之间的相关系数
a1=normc(a)%将a的各列化为单位向量
J=a1'*a1%计算各列的夹角余弦
运行结果展示
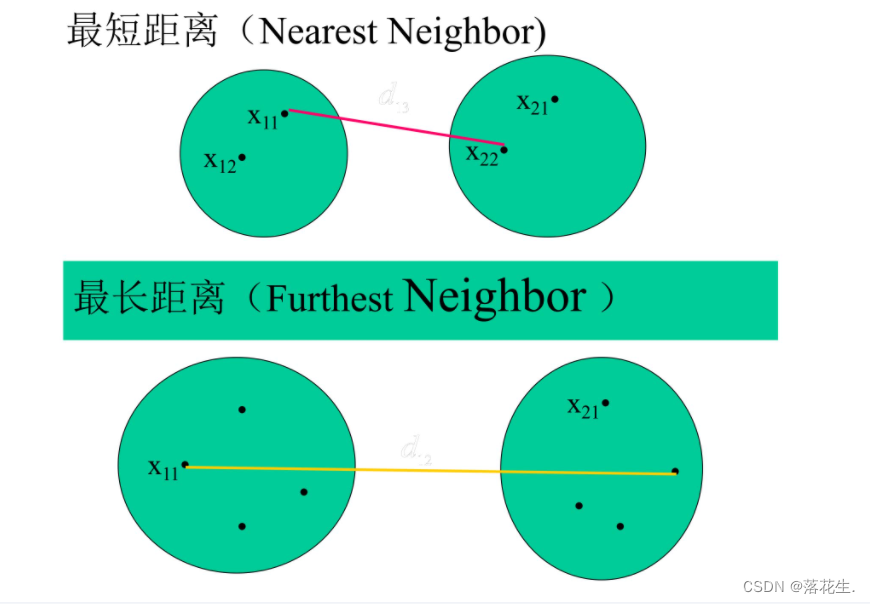
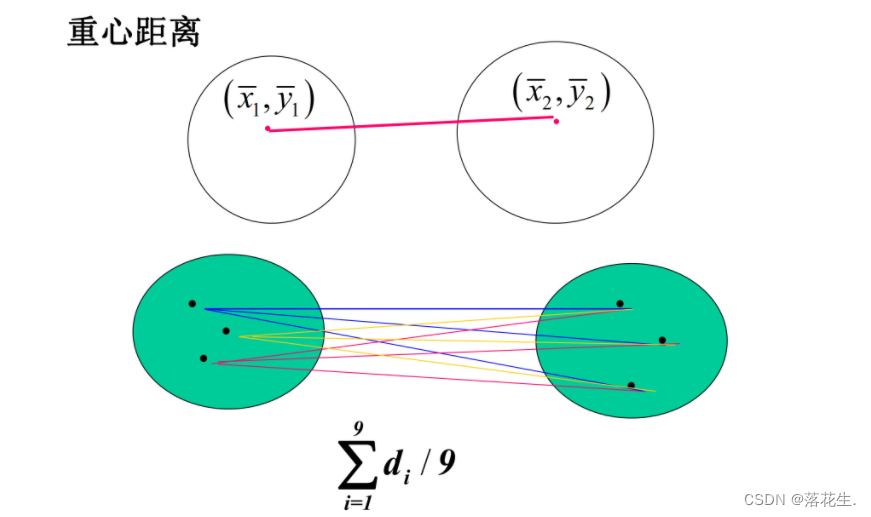
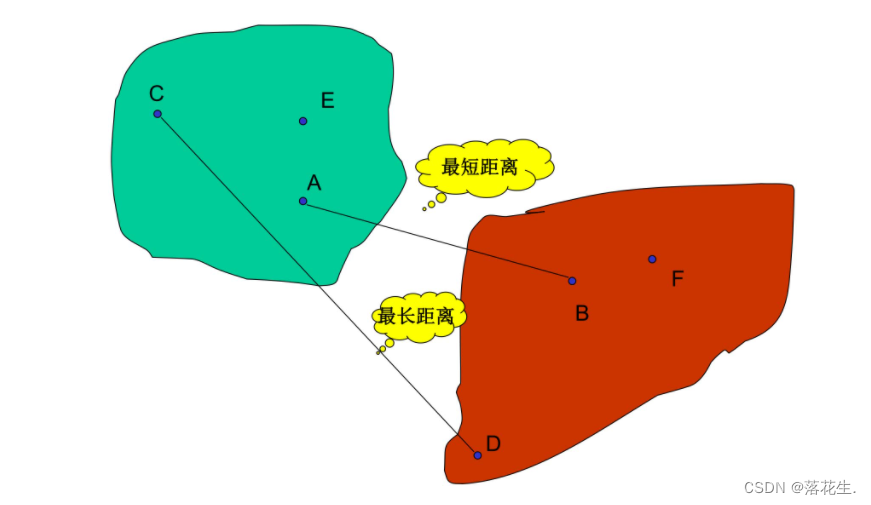
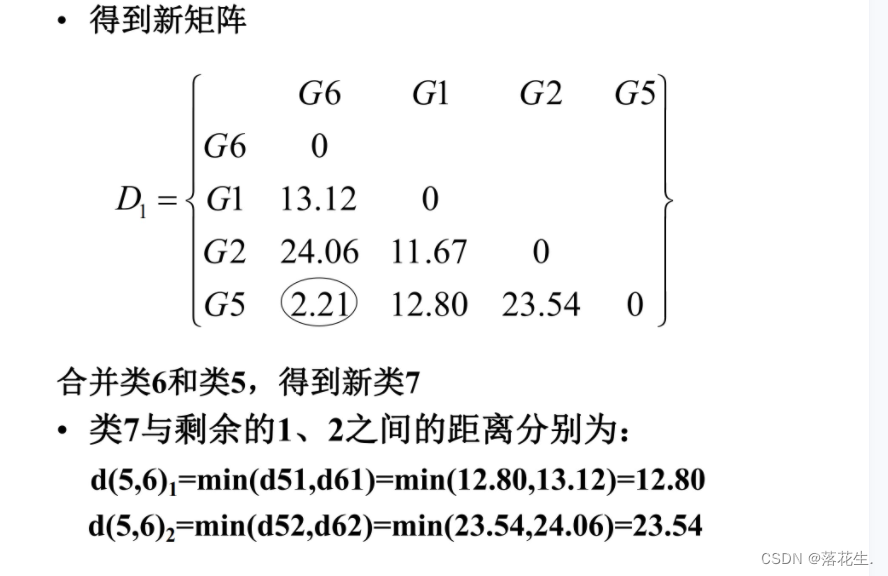
1.4类间距离


1.5 谱系聚类法的步骤



以分析例一为例


聚类分析实例
b=[7.9 39.77 8.49 12.94 19.27 11.05 2.04 13.29
7.68 50.37 11.35 13.3 19.25 14.59 2.75 14.87
9.42 27.93 8.2 8.14 16.17 9.42 1.55 9.76
9.16 27.98 9.01 9.32 15.99 9.1 1.82 11.35
10.06 28.64 10.52 10.05 16.18 8.39 1.96 10.81];
d1=pdist(b);%计算b中每行之间欧氏距离,输出为行向量
% D=squareform(d1)%以矩阵的形式展示欧氏距离,结果是实对称矩阵
D=tril(squareform(d1))%以下三角矩阵的方式展示不同行的欧氏距离数据。
% 以上两行代码可以省略
z1=linkage(d1)%将数据按照不同的距离进行聚类,直到聚类为同一类
% z2=linkage(d1,'complete');%最长距离
% z3=linkage(d1,'average');%重心距离
% z4=linkage(d1,'centroid');%中间距离
% z5=linkage(d1,'ward');%离差平方和
H=dendrogram(z1)%画出谱系聚类图
T=cluster(z1,3)%将z1分成三组,并输出分类结果
运行结果展示


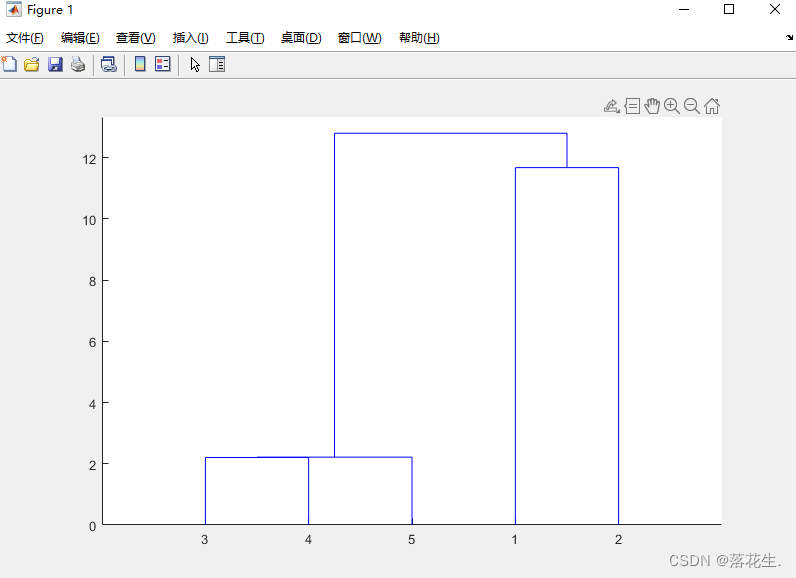
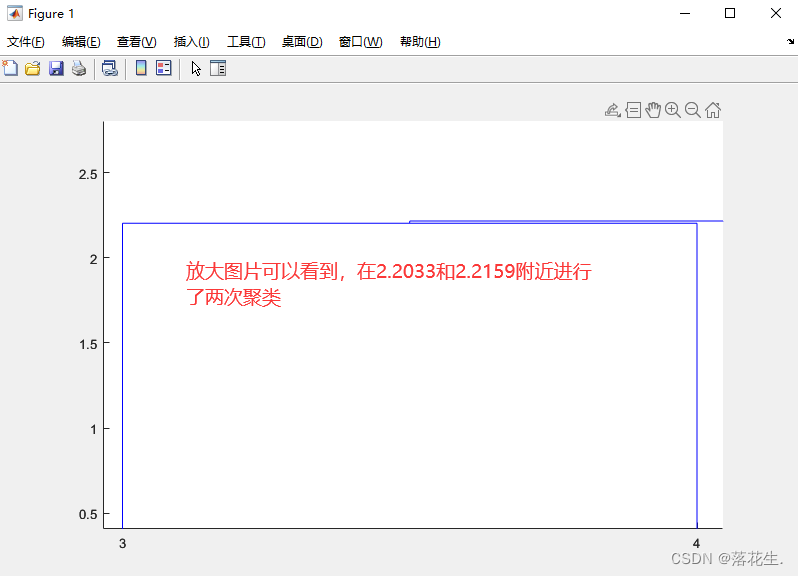
当让结果分成三类时的输出。下图表示第一行是一组,第二行分为一组,第三四五行分为一组

当让结果分成两类时的输出。下图表示第一行和第二行分为一组,第三四五行分为一组

K-平均聚类算法
K-平均(k-means)算法以k为参数,把n个对象分为k个簇,以使簇内对象具有较高的相似度,而簇间的相似度较低。
相似度的计算根据一个簇中对象的平均值(被看作簇的重心)来进行。




下图是三次迭代,每次迭代的结果
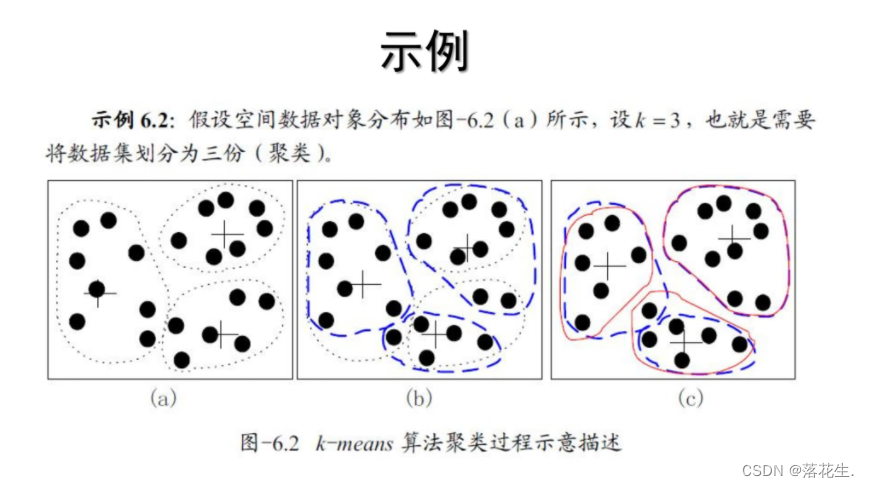
求出下例的K-平均聚类
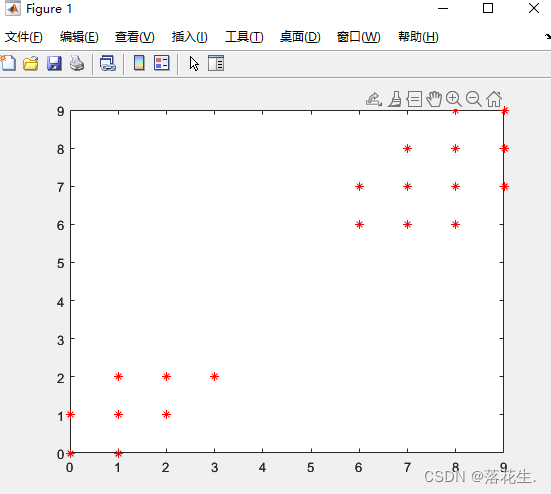
代码
x=[0 1 0 1 2 1 2 3 6 7 8 6 7 8 9 7 8 9 8 9;
0 0 1 1 1 2 2 2 6 6 6 7 7 7 7 8 8 8 9 9];
figure(1)
plot(x(1,:),x(2,:),'r*')%横轴为第一行所有列,纵轴为第二行所有列
%第一步,选取聚类中心,令K=2
Z1=[x(1,1);x(2,1)];
Z2=[x(1,2);x(2,2)];%聚类中心z1(0,0) z2(1,0)
R1=[];
R2=[];%分成两个聚类,用于存储成员
t=1;
K=1;% 记录迭代次数
dif1=inf;
dif2=inf;
%第二步计算各点,与聚类中心的距离
while (dif1>eps&&dif2>eps)%esp为最小值
for i=1:20
dist1=sqrt((x(1,i)-Z1(1)).^2+(x(2,i)-Z1(2)).^2);
dist2=sqrt((x(1,i)-Z2(1)).^2+(x(2,i)-Z2(2)).^2);
temp=[x(1,i),x(2,i)]';
if dist1<dist2
R1=[R1,temp];%将正在计算的点归类到R1
else
R2=[R2,temp];%将正在计算的点归类到R2
end
end
Z11=mean(R1,2);%mean(A,2)表示包含每一行的平均值的列向量(对行求平均)
Z22=mean(R2,2);%得到聚类中心
t1=Z1-Z11;%测试两次是不是相等,方法有很多种,这里只是简单的一种
t2=Z2-Z22;
dif1=sqrt(dot(t1,t1));
dif2=sqrt(dot(t2,t2));%dot两个向量的点积
Z1=Z11;
Z2=Z22;%将新的聚类中心赋予原来的变量
K=K+1;%迭代次数加1
R1=[];%
R2=[];
end
hold on
plot ([Z1(1);Z2(1)],[Z1(2),Z2(2)],'g+')%最终的聚类中心绿色加号表示