聚类分析
顾名思义,“物以类聚”,简单来说就是将具有相似个性的事物聚合分类。对样本进行分类称为Q型聚类,对指标进行分类称为R型聚类分析。更详细的内容可参考《数学建模算法与应用》(司守奎)这本书。
实例分析
Q型聚类分析(From the book)
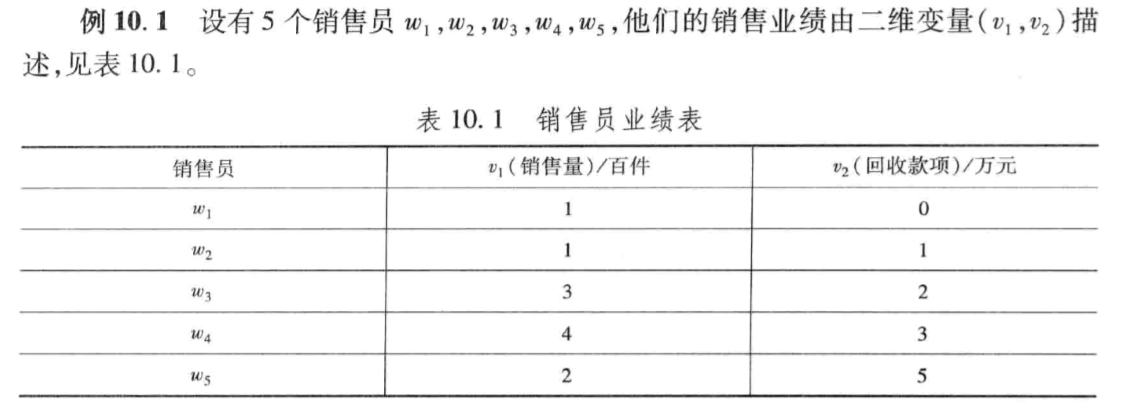
如上,销售员\(w_i(i=1,2,3,4,5)\)的销售业绩为\((v_{i1},v_{i2})\)。通过绝对值距离来测量点和点之间的距离,使用最短距离法类测量类与类之间的距离,即:
\[ d(w_i,w_j)=\sum_{k=1}^{2}|v_{ik}-v_{jk}|,D(G_p,G_q)=\min\limits_{w_i \in G_p,w_j\in G_q} \{d(w_i,w_j)\} \]
由距离公式算出距离矩阵:

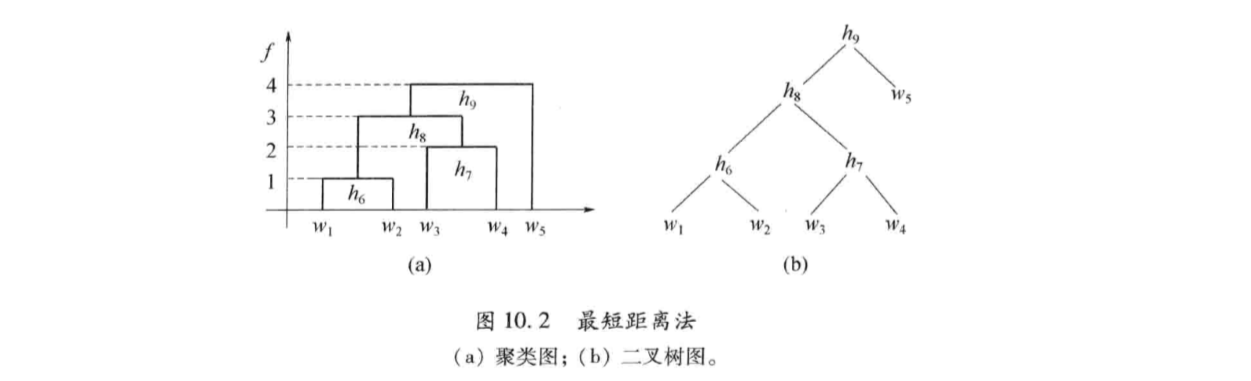
将所有的元素作为一个类\(H_1=\\{w_1,w_2,w_3,w_4,w_5\\}\)。每个类的平台高度为0,即:\(f(w_i)=0,i=1,2,3,4,5\)。这时候\(D(G_p,G_q)=d(w_p,w_q)\)
分别取平台高度为1,2,3,4得到不同的分类情况,画聚类图:
matlab求解代码:
%代码1
clc,clear
a=[1,0;1,1;3,2;4,3;2,5];
[m,n]=size(a);
d=zeros(m);
d=mandist(a'); % mandist:求矩阵列向量组之间的两两绝对值距离
d=tril(d); % 截取下三角元素
nd=nonzeros(d); %去除d中的零元素,非零元素按列排序
nd=union([],nd) % 去掉重复的非零元素
for i = 1:m-1
nd_min=min(nd);
[row,col]=find(d==nd_min);
tm=union(row,col); %row和col归为一类
tm=reshape(tm,1,length(tm));%将数组tm变为行向量
fprintf('第%d次合成,平台高度为%d时的分类结果为:%s\n',i,nd_min,int2str(tm));
nd(nd==nd_min)=[];%删除已经归类的元素
if length(nd)==0
break
end
end运行结果:
nd =
1
2
3
4
5
6
第1次合成,平台高度为1时的分类结果为:1 2
第2次合成,平台高度为2时的分类结果为:3 4
第3次合成,平台高度为3时的分类结果为:2 3
第4次合成,平台高度为4时的分类结果为:1 3 4 5%代码2
clc,clear
a=[1,0;1,1;3,2;4,3;2,5];
y=pdist(a,'cityblock'); % 求a得两两行向量之间得绝对距离
yc=squareform(y) %变换成距离方阵
z=linkage(y) %产生等级聚类树
dendrogram(z) %画聚类图
T=cluster(z,'maxclust',3) %把对象划分成3类
for i=1:3
tm=find(T==i); %求第i类的对象
tm=reshape(tm,1,length(tm)); %变成行向量
fprintf('第%d类的有%s\n',i,int2str(tm)); %显示分类结果
end运行结果:
yc =
0 1 4 6 6
1 0 3 5 5
4 3 0 2 4
6 5 2 0 4
6 5 4 4 0
z =
1 2 1
3 4 2
6 7 3
5 8 4
T =
1
1
2
2
3
第1类的有1 2
第2类的有3 4
第3类的有5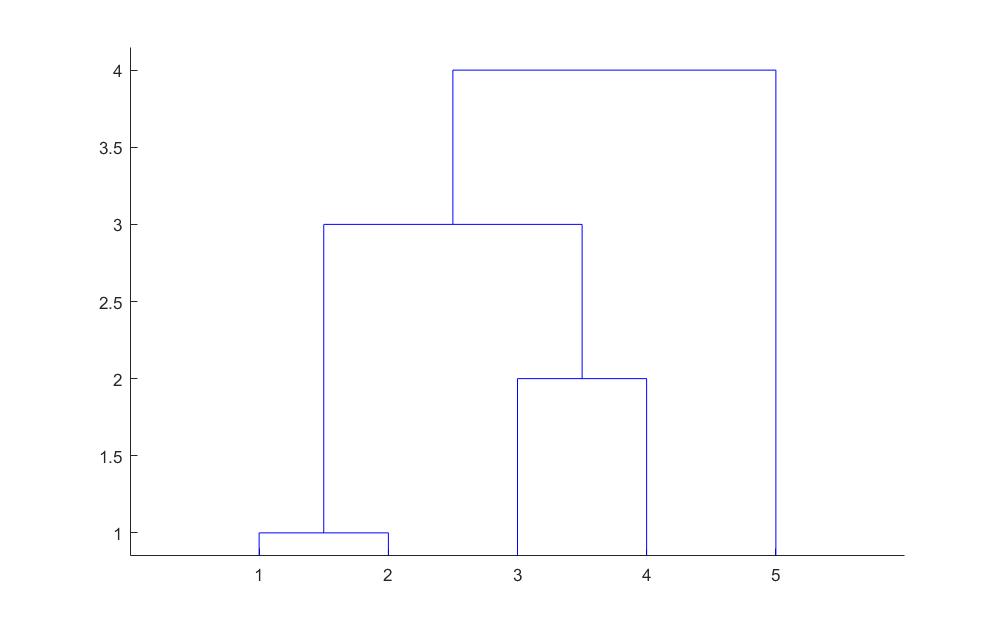
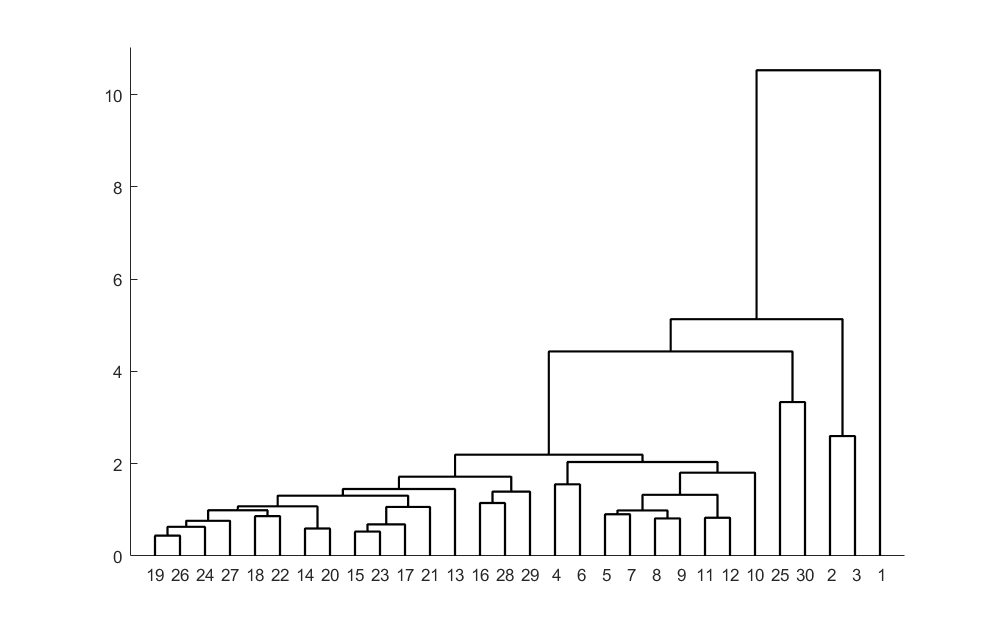
R型聚类分析
我国各地区普通高等教育发展状况分析
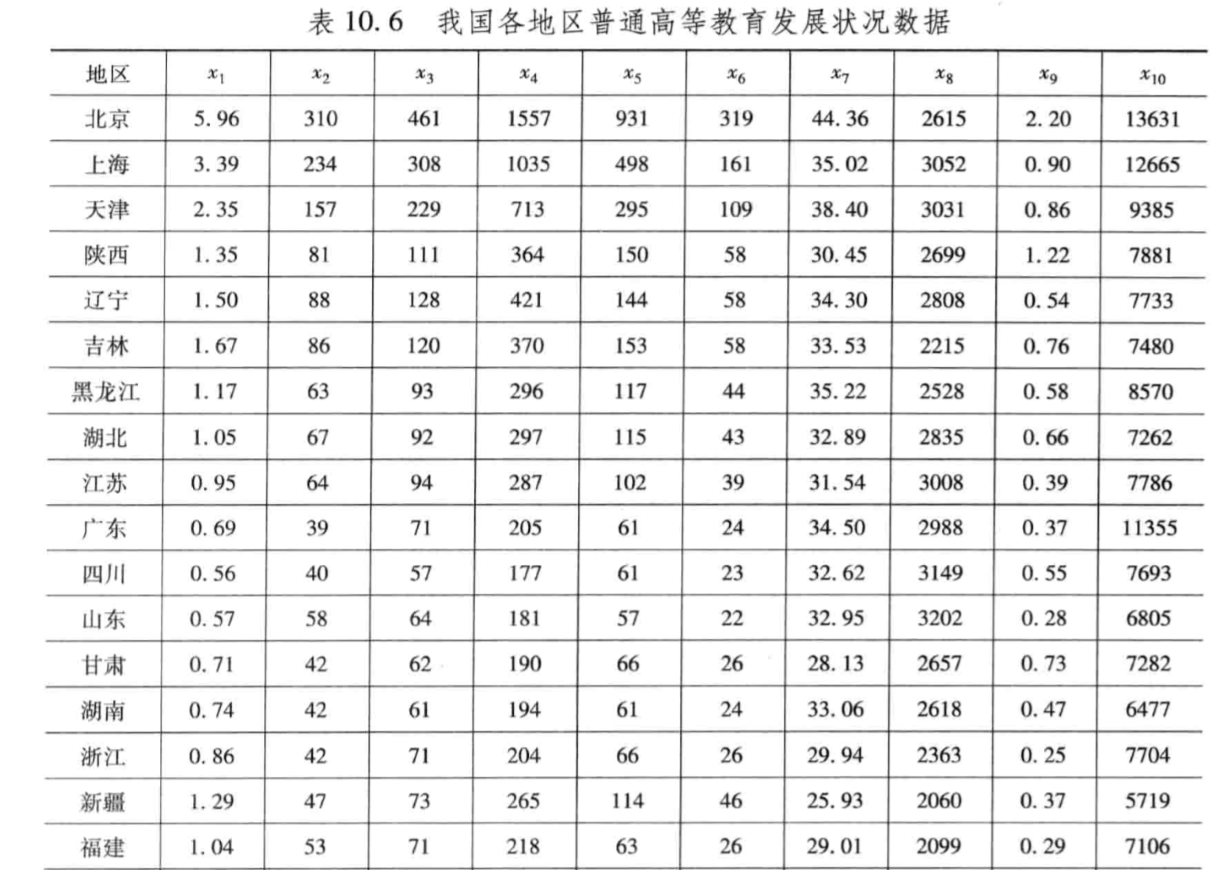
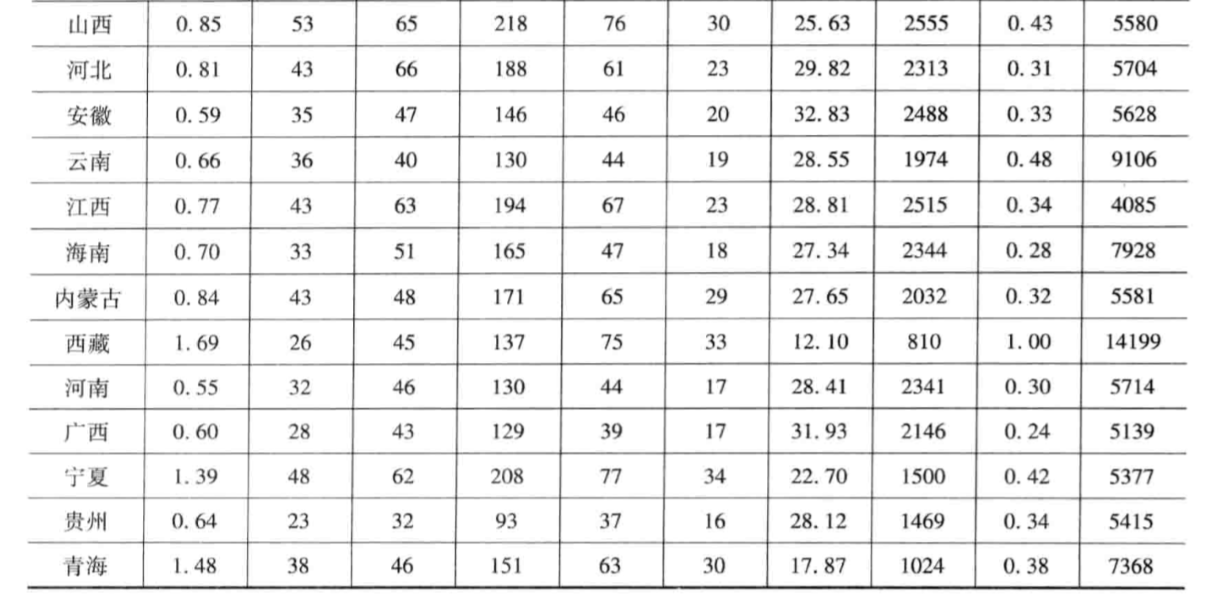
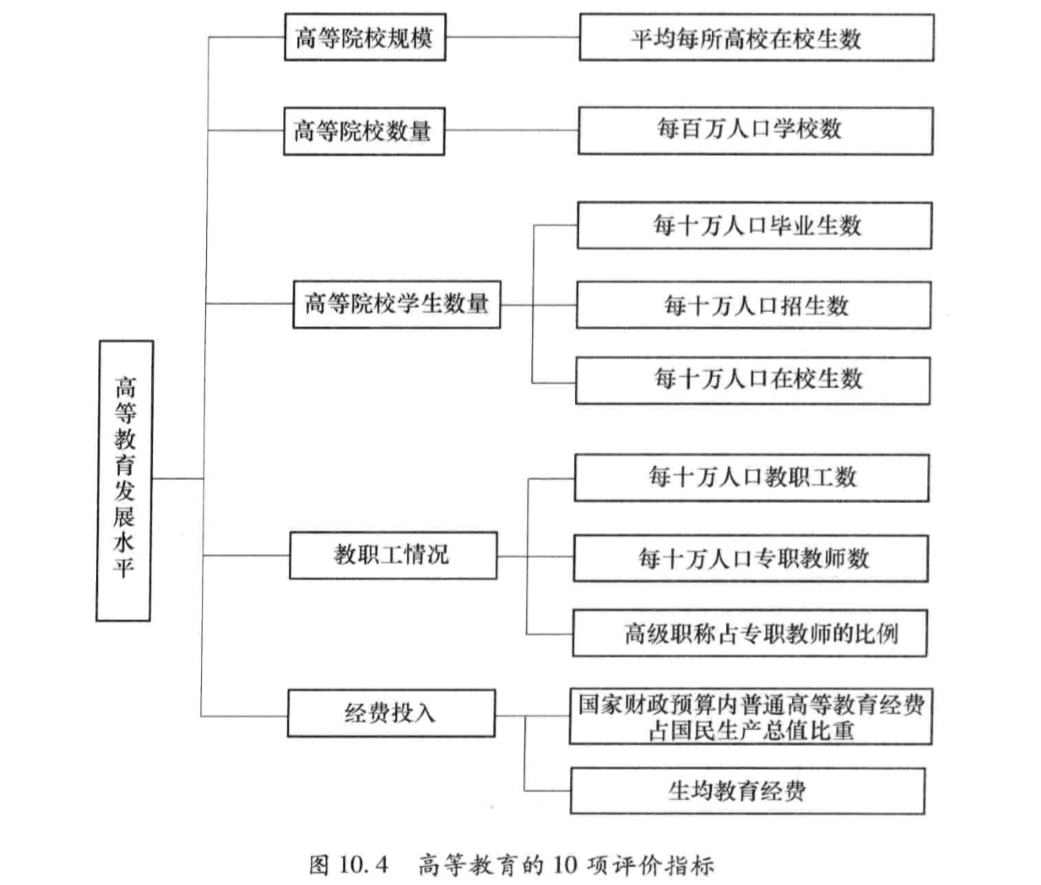
x1:每百万人口高等院校数
x2:每10万人口高等院校毕业生数
x3:每10万人口高等院校招生数
x4:每10万人口高等院校在校生数
x5:每10万人口高等院校教职工数
x6:每10万人口高等院校专职教师数
x7:高级职称占专职教师的比例
x8:平均每所高等院校的在校生数
x9:国家财政预算内普通高教经费占国内生产总值的比例
x10:生均教育经费Matlab程序求解
clc,clear
data=load('raw_data.txt'); % 加载原始数据
b=zscore(data); %数据标准化
r=corrcoef(b); %计算相关系数矩阵
d=pdist(b','correlation'); %计算相关系数d导出的距离
z=linkage(d,'average') %按类平均法聚类
h=dendrogram(z); %画聚类图
set(h,'Color','k','LineWidth',1.3) %把聚类图的颜色改成黑色,线宽加粗
T=cluster(z,'maxclust',6) %把变量划分成6类
for i=1:6
tm=find(T==i); %求第i类的对象
tm=reshape(tm,1,length(tm)); %变成行向量
fprintf('第%d类的有:%s\n',i,int2str(tm)); %显示分类结果
end运行结果
z =
3.0000 4.0000 0.0013
5.0000 6.0000 0.0014
2.0000 11.0000 0.0054
12.0000 13.0000 0.0197
1.0000 14.0000 0.0381
9.0000 15.0000 0.1582
7.0000 8.0000 0.2211
10.0000 16.0000 0.3685
17.0000 18.0000 0.6501
T =
1
2
2
2
2
2
4
5
3
6
第1类的有:1
第2类的有:2 3 4 5 6
第3类的有:9
第4类的有:7
第5类的有:8
第6类的有:10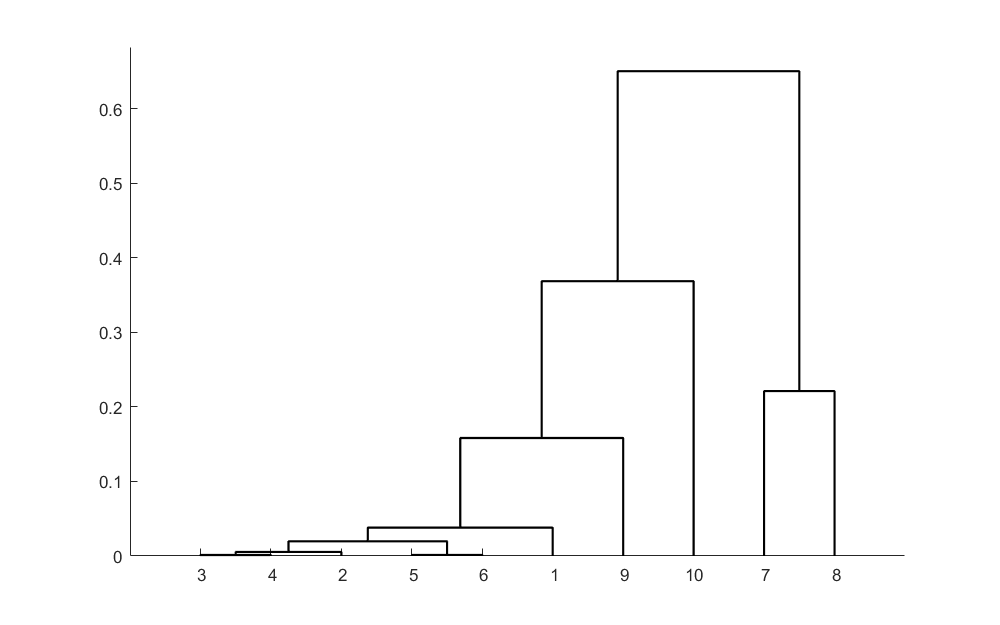
可以从上得出结论:x2、x3、x4、x5、x6这5个指标具有较大相关性,被先聚集到一起,这样就从10个指标中选中6个分析指标,然后通过这6个指标再对这30个地区进行Q型聚类分析。
Matalb求解代码
clc,clear
load raw_data.txt
raw_data(:,[3,6])=[ ];
raw_data=zscore(raw_data);
y=pdist(raw_data);
z=linkage(y,'average');
h=dendrogram(z);
set(h,'Color','k','LineWidth',1.3)
for k=3:5
fprintf('划分成%d类的结果如下:\n',k)
T=cluster(z,'maxclust',k);
for i=1:k
tm=find(T==i);
tm=reshape(tm,1,length(tm));
fprintf('第%d类的有%s\n',i,int2str(tm));
end
if k==5
break
end
fprintf('=======================\n');
end
运行结果:
划分成3类的结果如下:
第1类的有2 3
第2类的有4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30
第3类的有1
=======================
划分成4类的结果如下:
第1类的有4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 26 27 28 29
第2类的有25 30
第3类的有2 3
第4类的有1
=======================
划分成5类的结果如下:
第1类的有25
第2类的有30
第3类的有4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 26 27 28 29
第4类的有2 3
第5类的有1