Educoder实训平台机器学习—线性回归:scikit-learn线性回归实践 - 波斯顿房价预测
(下方代码已成功通过平台测试)
机器学习:波士顿房价数据集
波士顿房价数据集(Boston House Price Dataset)
使用sklearn.datasets.load_boston即可加载相关数据。该数据集是一个回归问题。每个类的观察值数量是均等的,共有 506 个观察,13 个输入变量和1个输出变量。
每条数据包含房屋以及房屋周围的详细信息。其中包含城镇犯罪率,一氧化氮浓度,住宅平均房间数,到中心区域的加权距离以及自住房平均房价等等。
CRIM:城镇人均犯罪率。
ZN:住宅用地超过 25000 sq.ft. 的比例。
INDUS:城镇非零售商用土地的比例。
CHAS:查理斯河空变量(如果边界是河流,则为1;否则为0)。
NOX:一氧化氮浓度。
RM:住宅平均房间数。

AGE:1940 年之前建成的自用房屋比例。
DIS:到波士顿五个中心区域的加权距离。
RAD:辐射性公路的接近指数。
TAX:每 10000 美元的全值财产税率。
PTRATIO:城镇师生比例。
B:1000(Bk-0.63)^ 2,其中 Bk 指代城镇中黑人的比例。
LSTAT:人口中地位低下者的比例。
MEDV:自住房的平均房价,以千美元计。
任务描述
本关任务:你需要调用 sklearn 中的线性回归模型,并通过波斯顿房价数据集中房价的13种属性与目标房价对线性回归模型进行训练。我们会调用你训练好的线性回归模型,来对房价进行预测。
相关知识
为了完成本关任务,你需要掌握:1.LinearRegression。
数据集介绍
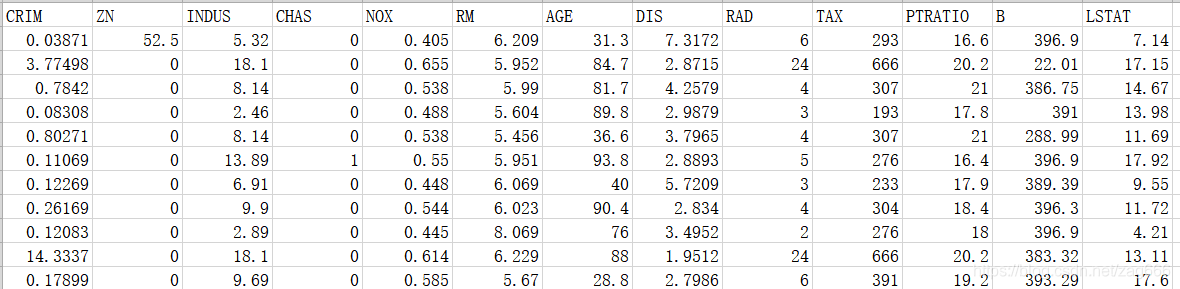
波斯顿房价数据集共有506条波斯顿房价的数据,每条数据包括对指定房屋的13项数值型特征和目标房价组成。用数据集的80%作为训练集,数据集的20%作为测试集,训练集和测试集中都包括特征和目标房价。
想要使用该数据集可以使用如下代码:
import pandas as pd
#获取训练数据
train_data = pd.read_csv('./step3/train_data.csv')
#获取训练标签
train_label = pd.read_csv('./step3/train_label.csv')
train_label = train_label['target']
#获取测试数据
test_data = pd.read_csv('./step3/test_data.csv')
数据集中部分数据与标签如下图所示:

LinearRegression
LinearRegression的构造函数中有两个常用的参数可以设置:
fit_intercept:是否有截据,如果没有则直线过原点,默认为Ture。
normalize:是否将数据归一化,默认为False。
LinearRegression类中的fit函数用于训练模型,fit函数有两个向量输入:
X:大小为[样本数量,特征数量]的ndarray,存放训练样本
Y:值为整型,大小为[样本数量]的ndarray,存放训练样本的标签值
LinearRegression类中的predict函数用于预测,返回预测值,predict函数有一个向量输入:
X:大小为[样本数量,特征数量]的ndarray,存放预测样本
LinearRegression的使用代码如下:
lr = LinearRegression()
lr.fit(X_train, Y_train)
predict = lr.predict(X_test)
编程要求
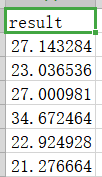
使用sklearn构建线性回归模型,利用训练集数据与训练标签对模型进行训练,然后使用训练好的模型对测试集数据进行预测,并将预测结果保存到./step3/result.csv中。保存格式如下:
通关代码
#encoding=utf8
#********* Begin *********#
import pandas as pd
from sklearn.linear_model import LinearRegression
train_data = pd.read_csv('./step3/train_data.csv')
train_label = pd.read_csv('./step3/train_label.csv')
train_label = train_label['target']
test_data = pd.read_csv('./step3/test_data.csv')
lr = LinearRegression()
lr.fit(train_data,train_label)
predict = lr.predict(test_data)
df = pd.DataFrame({'result':predict})
df.to_csv('./step3/result.csv', index=False)
#********* End *********#