回归分析(regression analysis)是确定两种或两种以上变量间相互依赖的定量关系(函数关系)的一种统计分析方法。(回归问题的目标值是连续型的,分类问题的目标值是离散型的)
回归有倒推的含义,就是从大量统计数据中寻找特征值与目标值之间的函数关系。(因为存在误差(损失函数)所以一般需要迭代)
线性关系:二维---->直线;三维---->平面。

线性回归:通过一个或者多个自变量(特征)与因变量(目标值)之间进行建模的回归分析。其中特点为一个或多个称为回归系数的模型参数的线性组合。
一元线性回归:涉及到的变量(特征)只有一个
多元线性回归:涉及到的变量(特征)有两个或两个以上
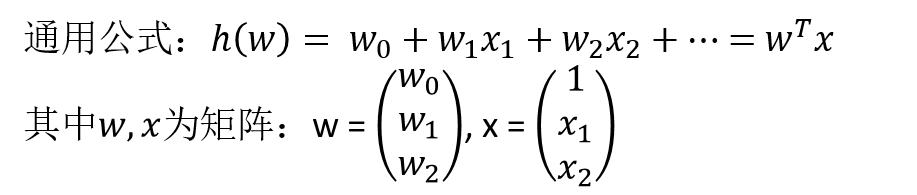

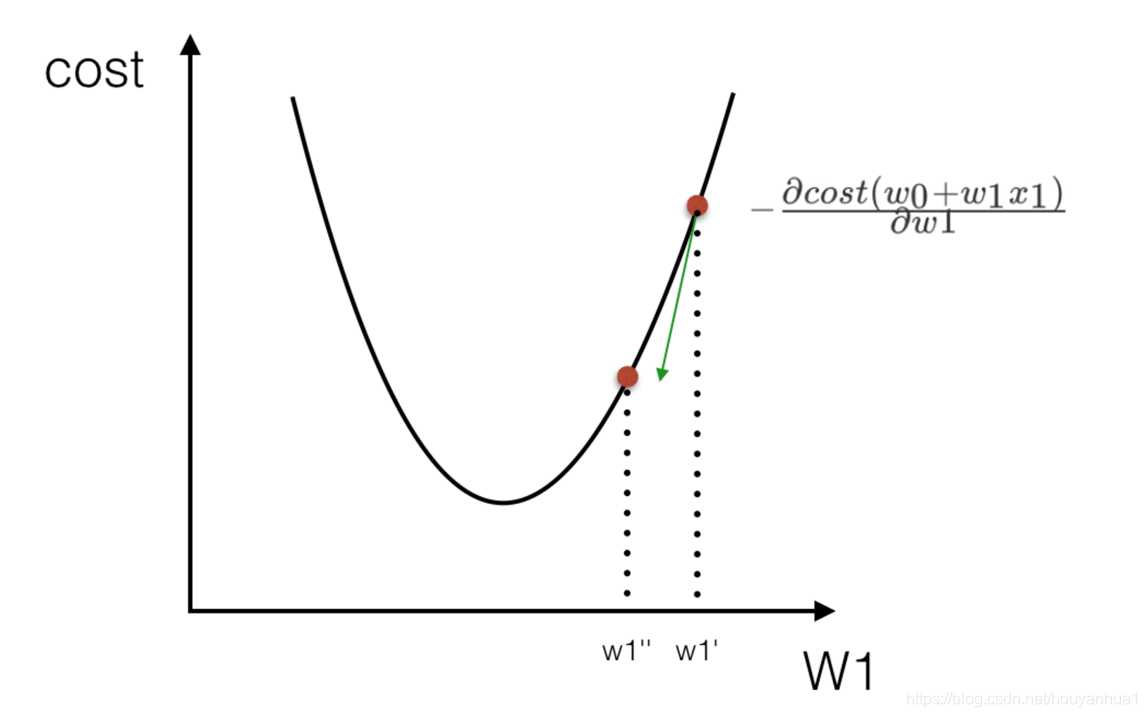
如何去求模型当中的W(权重,回归系数),使得损失最小? (两种方式:正规方程和梯度下降)




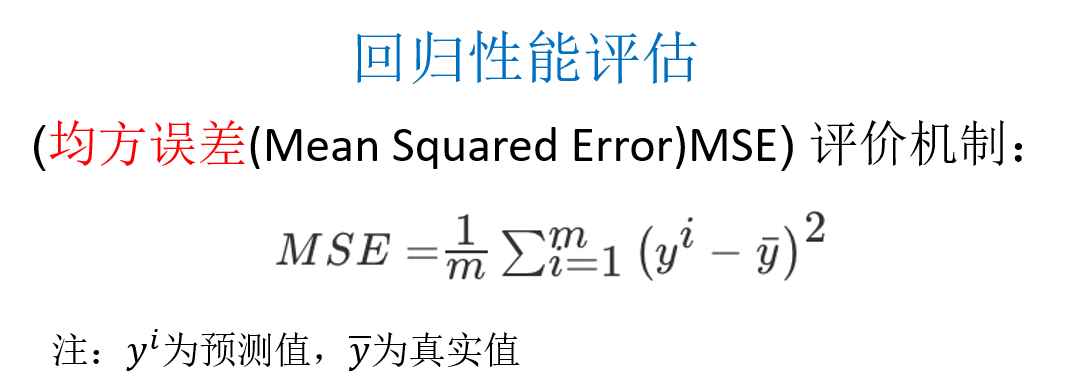

demo.py(线性回归(正规方程方式求解回归系数),LinearRegression。模型的保存、加载,joblib):
from sklearn.datasets import load_boston
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error
from sklearn.externals import joblib
# 线性回归,预测房价
# 获取数据 (加载scikit-learn中的数据集)
lb = load_boston()
# 分割数据集,划分训练集和测试集
x_train, x_test, y_train, y_test = train_test_split(lb.data, lb.target, test_size=0.25)
print(y_train, y_test)
# 进行标准化处理 (如果不进行标准化,会影响不同特征在误差函数中的权重)
# 特征值和目标值都必须进行标准化处理, 实例化两个标准化API
std_x = StandardScaler()
x_train = std_x.fit_transform(x_train)
x_test = std_x.transform(x_test)
# 目标值进行标准化
std_y = StandardScaler()
y_train = std_y.fit_transform(y_train) # 高版本的API需要传入二维数组:y_train.reshape(-1,1)
y_test = std_y.transform(y_test)
# # 根据之前保存的模型预测房价结果
# model = joblib.load("./tmp/test.pkl") # 加载保存的模型
# y_predict = std_y.inverse_transform(model.predict(x_test))
# print("根据保存的模型预测的结果:", y_predict)
# 正规方程方式求解回归参数(权重) 建立模型 进行预测。
lr = LinearRegression()
lr.fit(x_train, y_train)
# 打印回归参数(权重)
print(lr.coef_) # [-0.09700408 0.08235437 0.01618256 0.07418575 -0.17451631]
# 保存训练好的模型
joblib.dump(lr, "./tmp/test.pkl")
# 预测测试集的房子价格
y_lr_predict = std_y.inverse_transform(lr.predict(x_test)) # inverse_transform()表示将标准化后的值转换成原始的值。
print(y_lr_predict) # [14.09155911 25.10132059 33.6112457 18.72601122 ...]
# 预测结果的均方误差 (回归问题不能用准确率进行评估)
print("正规方程的均方误差:", mean_squared_error(std_y.inverse_transform(y_test), y_lr_predict))
# 26.1692742604
demo.py(线性回归(梯度下降方式求解回归系数),SGDRegressor):
from sklearn.datasets import load_boston
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import SGDRegressor
from sklearn.metrics import mean_squared_error
from sklearn.externals import joblib
# 线性回归,预测房价
# 获取数据 (加载scikit-learn中的数据集)
lb = load_boston()
# 分割数据集,划分训练集和测试集
x_train, x_test, y_train, y_test = train_test_split(lb.data, lb.target, test_size=0.25)
print(y_train, y_test)
# 进行标准化处理 (如果不进行标准化,会影响不同特征在误差函数中的权重)
# 特征值和目标值都必须进行标准化处理, 实例化两个标准化API
std_x = StandardScaler()
x_train = std_x.fit_transform(x_train)
x_test = std_x.transform(x_test)
# 目标值进行标准化
std_y = StandardScaler()
y_train = std_y.fit_transform(y_train) # 高版本的API需要传入二维数组:y_train.reshape(-1,1)
y_test = std_y.transform(y_test)
# # 根据之前保存的模型预测房价结果
# model = joblib.load("./tmp/test.pkl") # 加载保存的模型
# y_predict = std_y.inverse_transform(model.predict(x_test))
# print("保存的模型预测的结果:", y_predict)
# 梯度下降方式求解回归参数(权重) 建立模型 进行预测。
sgd = SGDRegressor() # scikit-learn中,学习速率已经封装在API内部。
sgd.fit(x_train, y_train)
# 打印回归参数(权重)
print(sgd.coef_) # [-0.0637264 0.05708586 -0.0555915 0.04695691 -0.09686863]
# 保存训练好的模型
joblib.dump(sgd, "./tmp/test.pkl")
# 预测测试集的房子价格
y_sgd_predict = std_y.inverse_transform(sgd.predict(x_test))
print(y_sgd_predict) # [14.58732341 24.39995957 35.81995631 ...]
# 预测结果的均方误差 (回归问题不能用准确率进行评估)
print("梯度下降的均方误差:", mean_squared_error(std_y.inverse_transform(y_test), y_sgd_predict))
# 26.906113135

线性回归是最为简单、易用的回归模型。从某种程度上限制了使用,尽管如此,在不知道特征之间关系的前提下,我们仍然使用线性回归器作为大多数系统的首要选择。
小规模数据:正规方程 LinearRegression。正规方程可能会过拟合,可以用岭回归(Ridge)避免过拟合。
大规模数据:梯度下降 SGDRegressor