什么是Scikit-learn?
Scikit-learn是一个用于Python编程语言的机器学习库。它提供了各种监督和无监督学习算法,包括分类、回归、聚类、降维等。Scikit-learn易于使用且功能强大,可以处理大型数据集,并且具有很好的可扩展性。它还提供了许多方便的工具,如数据预处理、模型选择、评估和可视化等。Scikit-learn是许多机器学习项目中使用的首选库之一。
安装scikit-learn
pip install scikit-learnInstalling scikit-learn — scikit-learn 1.3.2 documentation

使用scikit-learn进行线性回归
下面是一个使用scikit-learn进行线性回归的详细案例:
1)首先,我们需要导入所需的库和数据集:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error, r2_score
2)接下来,我们创建一个简单的数据集,其中x是自变量,y是因变量:
# 创建数据集
np.random.seed(0)
x = np.random.rand(100, 1)
y = 2 + 3 * x + np.random.rand(100, 1)
# 绘制数据集
plt.scatter(x, y)
plt.xlabel('x')
plt.ylabel('y')
plt.show()
3)将数据集分为训练集和测试集:
# 将数据集分为训练集和测试集
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, random_state=0)
4)创建线性回归模型并拟合训练数据:
# 创建线性回归模型并拟合训练数据
regressor = LinearRegression()
regressor.fit(x_train, y_train)
5)使用模型进行预测:
# 使用模型进行预测
y_pred = regressor.predict(x_test)
6)评估模型的性能:
# 评估模型的性能
mse = mean_squared_error(y_test, y_pred)
r2 = r2_score(y_test, y_pred)
print('均方误差:', mse)
print('R2分数:', r2)
 均方误差越小,说明拟合效果越好,最小值为0。
均方误差越小,说明拟合效果越好,最小值为0。
R2分数刚好和均方误差相反,越大越好,最大值为1。
均方误差(Mean Squared Error,MSE)是用于评估回归模型拟合优度的一种统计指标。它表示预测值与实际值之间差异的平方和的平均值,即误差平方和的平均值。
MSE越小表示模型的预测效果越好,反之则表示模型的预测效果较差。通常情况下,MSE越小表示模型的拟合效果越好。
R2分数(Coefficient of Determination)也称为决定系数,是用于评估回归模型拟合优度的一种统计指标。它表示自变量对于因变量的解释程度,即自变量能够解释因变量变异的比例。
R2分数的取值范围在0到1之间,越接近1表示模型拟合效果越好,越接近0表示模型拟合效果越差。
R2分数还可以用于比较不同模型的拟合效果,通常情况下,R2分数越大表示模型的拟合效果越好。
7)最后,我们可以绘制拟合结果:
# 绘制拟合结果
plt.scatter(x_test, y_test, color='blue', label='actual')
plt.plot(x_test, y_pred, color='red', linewidth=2, label='predict')
plt.xlabel('x')
plt.ylabel('y')
plt.legend()
plt.show()
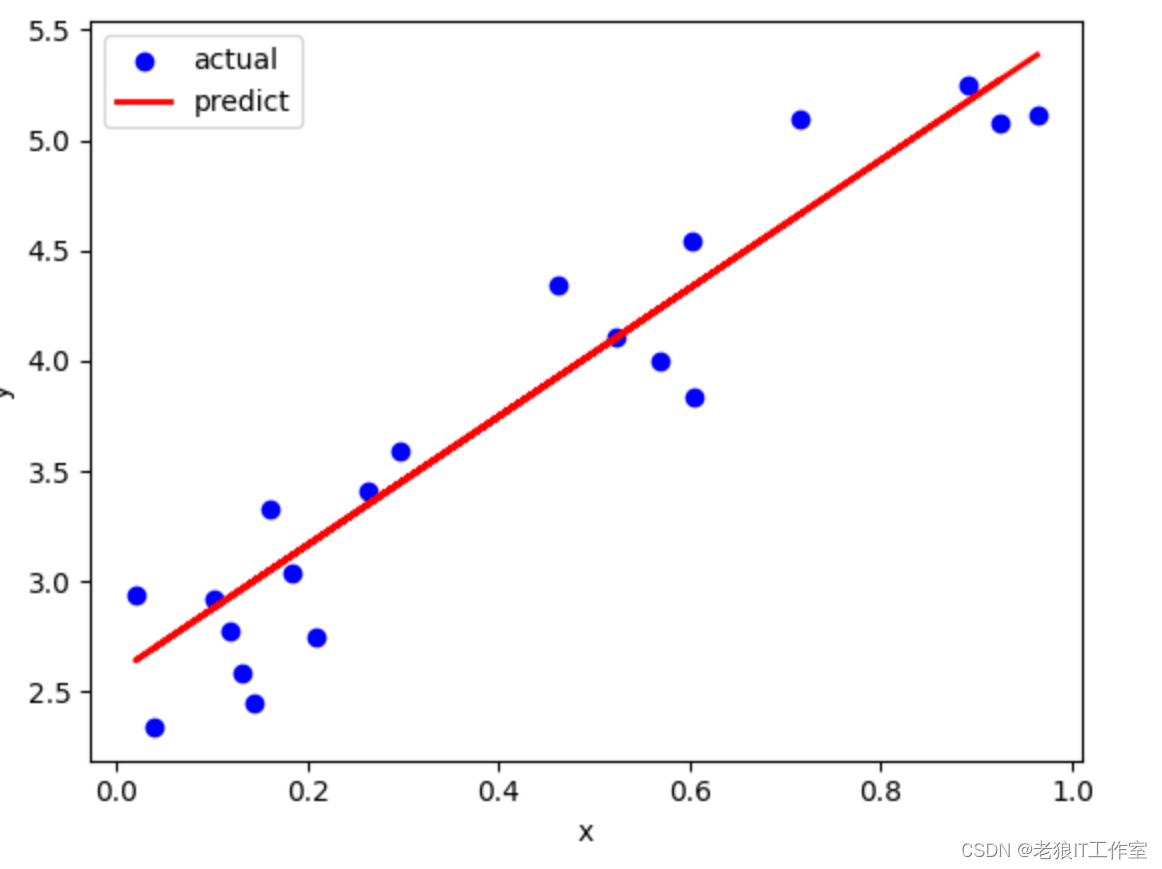
这个案例展示了如何使用scikit-learn进行线性回归。首先,我们创建了一个简单的数据集,然后将其分为训练集和测试集。接着,我们创建了一个线性回归模型并使用训练数据对其进行拟合。最后,我们使用测试数据对模型进行评估,并绘制了拟合结果。