backward()是Pytorch中用来求梯度的方法,可以分为三种情况来使用。
1.out.backwark()中out是一个标量
此时可以直接使用out.backwark():
import torch
from torch.autograd import Variable
#生成一个内容为[2,3]的张量,Varibale 默认是不要求梯度的,如果要求梯度,
#需要加上requires_grad=True来说明
#这里的Variable是为了设置变量,把a0=2,a1=3设置为两个变量
a = Variable(torch.tensor([2,3]),requires_grad=True)
b = a+3
c = b*3
out=c.mean() #求均值
out.backward()
print("a=",a)
print("out=",out)
print(a.grad) #求out对a的偏导
结果为
a= tensor([2., 3.], requires_grad=True)
out= tensor(16.5000, grad_fn=<MeanBackward0>)
tensor([1.5000, 1.5000])
将上面的程序写成数学表达式就是:
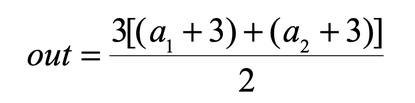
求偏导的过程为:
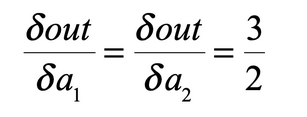
2. out.backward()中的out是一个向量(或者理解成1xN的矩阵)
import torch
from torch.autograd import Variable
#生成一个内容为[2,4]的张量,Varibale 默认是不要求梯度的,如果要求梯度,
#需要加上requires_grad=True来说明
a = Variable(torch.Tensor([[2,4]]),requires_grad=True)
b = torch.zeros(1,2)
b[0,0] = a[0,0]**2+a[0,1]
b[0,1] = a[0,1]**3+a[0,0]
out = 2*b
#括号里面的参数要传入和out维度一样的矩阵
#这个矩阵里面的元素会作为最后加权输出的权重系数
out.backward(torch.FloatTensor([[1,2]]))
print("a=",a)
print("out=",out)
print(a.grad) #求out对a的偏导
结果为:
a= tensor([[2., 4.]], requires_grad=True)
out= tensor([[ 16., 132.]], grad_fn=<MulBackward0>)
tensor([[12., 194.]])
将上面的程序写成数学表达式就是:
这儿有个疑问,为什么上面的程序计算出来是[12,194]呢?大家可以看到这一行传进去的两个参数[1,2]
out.backward(torch.FloatTensor([[1,2]]))
有:
3. out.backward()中的out是一个矩阵
import torch
from torch.autograd import Variable
#生成一个内容为[2,3]的张量,Varibale 默认是不要求梯度的,如果要求梯度,
#需要加上requires_grad=True来说明
a = Variable(torch.Tensor([[2,3],[1,2]]),requires_grad=True)
w = Variable(torch.ones(2,1),requires_grad=True)
out = torch.mm(a,w)
#括号里面的参数要传入和out维度一样的矩阵
#这个矩阵里面的元素会作为最后加权输出的权重系数
out.backward(torch.FloatTensor([[1],[1]]))
print("gradients are:{}".format(w.grad.data))
结果为:
gradients are:tensor([[3.],
[5.]])
