一、主题式网络爬虫设计方案
1,主题式网络爬虫名称:
爬取爱奇艺影片热榜
2,主题式网络爬虫爬取的内容与数据特征分析:
爬取内容为:影片名称,排名,与其点击量
数据特征分析:将其储存于csv或xlsx文件中
3.主题式网络爬虫设计方案概述(包括实现思路与技术难点)
实现思路:首先进行对网页源代码的访问分析,用BeautifulSoup进行HTML的解析和信息的爬取,后续对爬取下来的信息用pandas进行绘图数据分析
技术难点:爬取信息时对标签的查找,写出查找所需标签的代码,对数据进行相应的分析
二、主题页面的结构特征分析
打开网址http://v.iqiyi.com/index/dianying/index.html,F12或右键点击检查
扫描二维码关注公众号,回复:
10637579 查看本文章

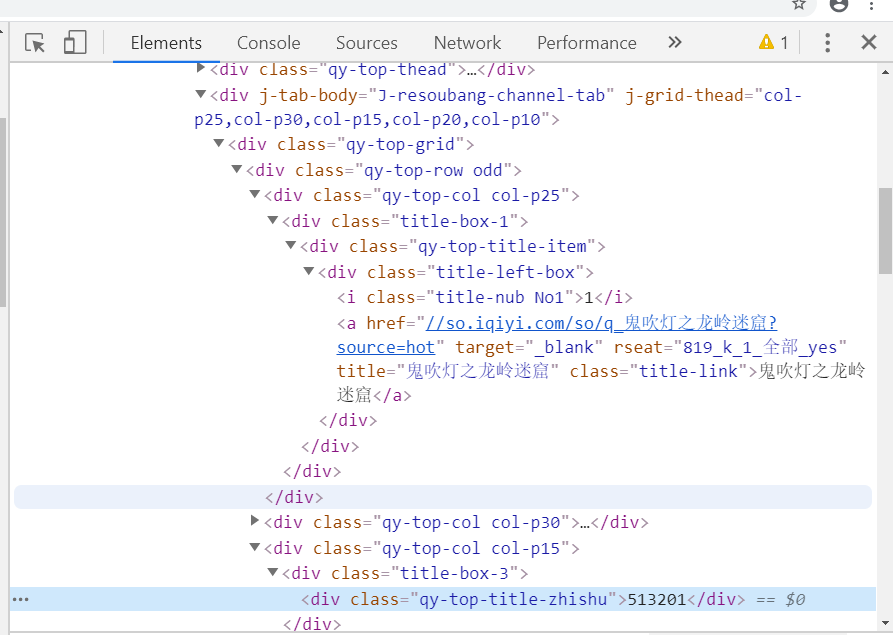

源代码中可以看到,影片标题的名称在div标签下的a,title-link标签中,点击数在标签div,qy-top-title-zhishu中
用for语句及find_all语句进行遍历和爬取
三、网络爬虫程序设计
#导入所需要的BeautifulSoup和pandas
import requests import pandas as pd
from bs4 import BeautifulSoup #待爬取的网址 url = "http://v.iqiyi.com/index/dianying/index.html" #模拟浏览器 header={"User-Agent": "kaidie"} #发送请求 r = requests.get(url,headers=header) #创建标题的空列表 titlelist=[] #创建点击数的空列表 mathlist=[] #为储存数据创立空列表 alist=[] #用BeautifulSoup进行html的解析 soup=BeautifulSoup(html,'html.parser') #找到所对应的标签 #用for遍历循环find_all查找语句查找标题 for a in soup.find_all("a","title-link"): titlelist.append(a.string) #同理找视频的点击数 for div in soup.find_all("div","qy-top-title-zhishu"): mathlist.append(div.string)
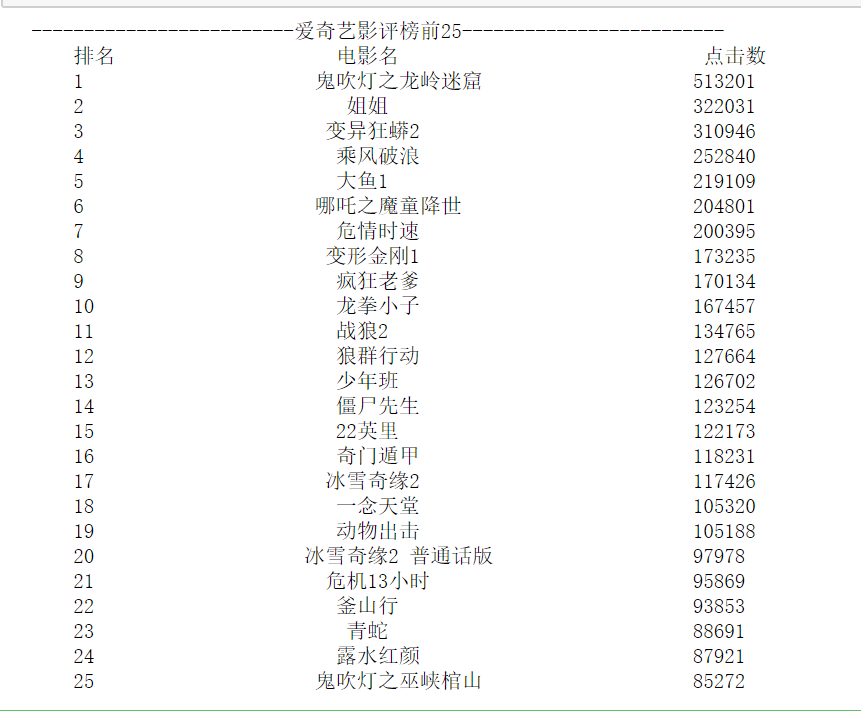
print(""-------------------------爱奇艺影片榜前25-------------------------"") print("{:^10}\t{:^30}\t{:^20}".format("排名","电影名","点击数")) #获取爱奇艺影片榜前25名 for i in range(25): print("{:^10}\t{:^30}\t{:^20}".format(i+1,titlelist[i],mathlist[i])) #将获取的数据放入alist的空列表中 for i in range(25): alist.append([i+1,titlelist[i],mathlist[i]]) #用pandas对数据进行储存,做到数据的持久化
A = pd.DataFrame(alist,columns = ['排名','电影名','点击数']) A.to_excel('爱奇艺排行.xlsx')

2.对数据进行清洗和处理
#读取文件中的信息 df = pd.DataFrame(pd.read_excel('爱奇艺排行.xlsx')) #打印出所有的信息 df.head(25)

#根据具体的需求可以清除不需要的数据 df.drop("点击数", axis=1,inplace=True) df.head(10)

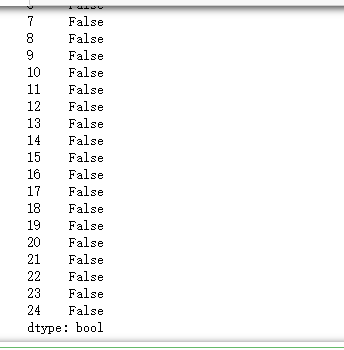
#重复值的处理 df = pd.DataFrame(pd.read_excel('爱奇艺排行.xlsx')) df.duplicated()
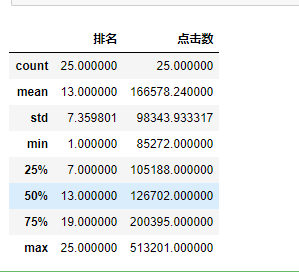
#异常值的观察 df = pd.DataFrame(pd.read_excel('爱奇艺排行.xlsx')) df.describe()
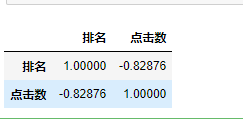
#查看相关系数 df = pd.DataFrame(pd.read_excel('爱奇艺排行.xlsx')) df.corr()
3.数据分析与可视化
#根据画图的需求导入相应的库 from matplotlib import pyplot as plt import numpy as np import matplotlib.pyplot as plt import matplotlib
import seaborn as sns
#定义一个散点图的函数
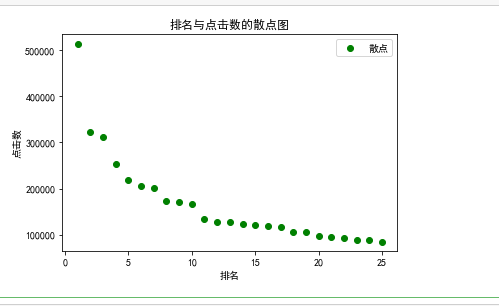
#排名与点击数的散点图 def Sspot(): df = pd.DataFrame(pd.read_excel('爱奇艺排行.xlsx')) #赋予x,y所对应的值 x = df.排名 y = df.点击数 plt.xlabel("排名") plt.ylabel("点击数") plt.scatter(x,y,color="green",label="散点") plt.title("排名与点击数的散点图") plt.legend() plt.show() Sspot()
#绘制扇形图 def Pspot(): df = pd.DataFrame(pd.read_excel('爱奇艺排行.xlsx')) x = df.电影名 y = df.点击数 #前五名的电影标题 name = [x[0],x[1],x[2],x[3],x[4]] math = [y[0],y[1],y[2],y[3],y[4]] explode=[0.1,0.1,0.1,0.1,0.1] plt.pie(math,labels=name,colors=["r","g","c","b","y"],explode=explode) plt.axis("equal") plt.title("点击数与电影的扇形图") plt.show() Pspot()

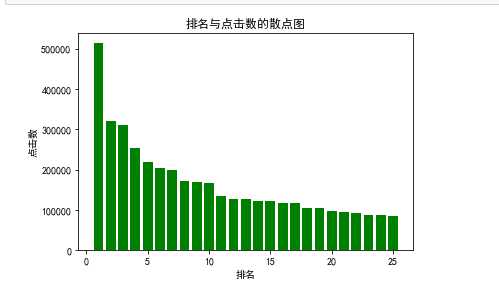
#排名与点击数的条形图 def Tspot(): df = pd.DataFrame(pd.read_excel('爱奇艺排行.xlsx')) x = df.排名 y = df.点击数 plt.xlabel("排名") plt.ylabel("点击数") plt.bar(x,y,color="green") plt.title("排名与点击数的条形图") plt.show() Tspot()
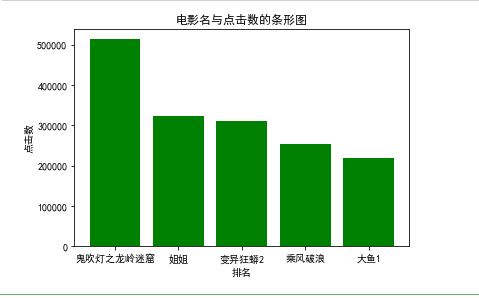
#前五名的电影与点击数的条形图 def Tspot2(): df = pd.DataFrame(pd.read_excel('爱奇艺排行.xlsx')) x = df.电影名[:5] y = df.点击数[:5] plt.xlabel("电影名") plt.ylabel("点击数") plt.bar(x,y,color="green") plt.title("电影名与点击数的条形图") plt.show() Tspot2()
#排名与点击数的折线图 def Zspot(): df = pd.DataFrame(pd.read_excel('爱奇艺排行.xlsx')) x = df.排名 y = df.点击数 plt.xlabel("排名") plt.ylabel("点击数") plt.plot(x,y,color="green",label="折线") plt.title("排名与点击数的折线图") plt.legend() plt.show() Zspot()

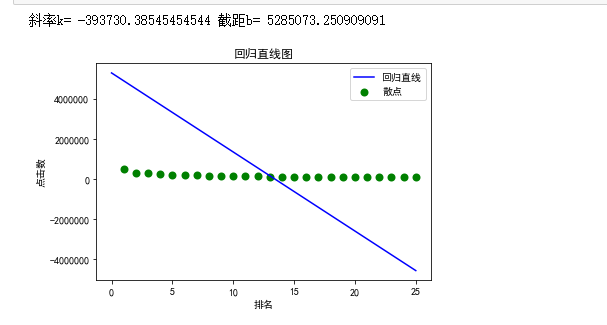
#回归直线的图 def huigui(): #x,y为回归直线的排名和点击数 x = df.排名 y = df.点击数 #X,Y为散点图的 X = df.排名 Y = df.点击数 #先定义所需要的数据 x_i2=0 x_i =0 y_i=0 #计算出x,y的均值用mean() q = x.mean() w = y.mean() for i in range(25): x_i2 = x_i+x[i]*x[i] x_i = x_i+x[i] y_i = y_i+y[i] #运用回归直线的公式计算出所需要的值 #分子 m_1 = x_i*y_i-25*q*w #分母 m_2 = x_i2-25*q*q #斜率 k = m_1/m_2 #截距 b = w-q*k x=np.linspace(0,25) y=k*x+b print("斜率k=",k,"截距b=",b) plt.figure(figsize=(6,4)) plt.xlabel('排名') plt.ylabel('点击数') plt.scatter(X,Y,color="green",label="散点",linewidth=2) plt.plot(x, y,color="blue",label= "回归直线") plt.title("回归直线图") plt.legend() plt.show() huigui()
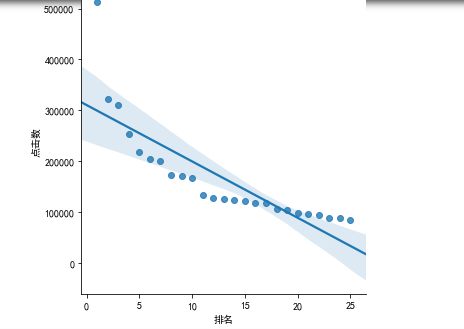
#排名和点击数的线性关系 df = pd.DataFrame(pd.read_excel('爱奇艺排行.xlsx')) sns.lmplot(x="排名",y= "点击数",data=df)
4.完整程序代码
1 #导入所需要的BeautifulSoup和pandas 2 import requests 3 import pandas as pd 4 from bs4 import BeautifulSoup 5 #根据画图的需求导入相应的库 6 from matplotlib import pyplot as plt 7 import numpy as np 8 import matplotlib.pyplot as plt 9 import matplotlib 10 import seaborn as sns 11 12 #待爬取的网址 13 url = "http://v.iqiyi.com/index/dianying/index.html" 14 #模拟浏览器 15 header={"User-Agent": "kaidie"} 16 #发送请求 17 r = requests.get(url,headers=header) 18 #创建标题的空列表 19 titlelist=[] 20 #创建点击数的空列表 21 mathlist=[] 22 #为储存数据创立空列表 23 alist=[] 24 25 #用BeautifulSoup进行html的解析 26 soup=BeautifulSoup(html,'html.parser') 27 #找到所对应的标签 28 #用for遍历循环find_all查找语句查找标题 29 for a in soup.find_all("a","title-link"): 30 titlelist.append(a.string) 31 32 #同理找视频的点击数 33 for div in soup.find_all("div","qy-top-title-zhishu"): 34 mathlist.append(div.string) 35 36 print(""-------------------------爱奇艺影评榜前25-------------------------"") 37 print("{:^10}\t{:^30}\t{:^20}".format("排名","电影名","点击数")) 38 39 #获取爱奇艺影评榜前25名 40 for i in range(25): 41 print("{:^10}\t{:^30}\t{:^20}".format(i+1,titlelist[i],mathlist[i])) 42 43 #将获取的数据放入alist的空列表中 44 for i in range(25): 45 alist.append([i+1,titlelist[i],mathlist[i]]) 46 47 #用pandas对数据进行储存,做到数据的持久化 48 A = pd.DataFrame(alist,columns = ['排名','电影名','点击数']) 49 A.to_excel('爱奇艺排行.xlsx') 50 51 #读取文件中的信息 52 df = pd.DataFrame(pd.read_excel('爱奇艺排行.xlsx')) 53 #打印出所有的信息 54 df.head(25) 55 56 #根据具体的需求可以清除不需要的数据 57 df.drop("点击数", axis=1,inplace=True) 58 df.head(10) 59 60 #重复值的处理 61 df = pd.DataFrame(pd.read_excel('爱奇艺排行.xlsx')) 62 df.duplicated() 63 64 #异常值的观察 65 df = pd.DataFrame(pd.read_excel('爱奇艺排行.xlsx')) 66 df.describe() 67 68 #查看相关系数 69 df = pd.DataFrame(pd.read_excel('爱奇艺排行.xlsx')) 70 df.corr() 71 72 #排名和点击数的线性关系 73 df = pd.DataFrame(pd.read_excel('爱奇艺排行.xlsx')) 74 sns.lmplot(x="排名",y= "点击数",data=df) 75 76 #定义一个散点图的函数 77 #排名与点击数的散点图 78 def Sspot(): 79 df = pd.DataFrame(pd.read_excel('爱奇艺排行.xlsx')) 80 #赋予x,y所对应的值 81 x = df.排名 82 y = df.点击数 83 plt.xlabel("排名") 84 plt.ylabel("点击数") 85 plt.scatter(x,y,color="green",label="散点") 86 plt.title("排名与点击数的散点图") 87 plt.legend() 88 plt.show() 89 Sspot() 90 91 #绘制扇形图 92 def Pspot(): 93 df = pd.DataFrame(pd.read_excel('爱奇艺排行.xlsx')) 94 x = df.电影名 95 y = df.点击数 96 #前五名的电影标题 97 name = [x[0],x[1],x[2],x[3],x[4]] 98 math = [y[0],y[1],y[2],y[3],y[4]] 99 explode=[0.1,0.1,0.1,0.1,0.1] 100 plt.pie(math,labels=name,colors=["r","g","c","b","y"],explode=explode) 101 plt.axis("equal") 102 plt.title("排名与电影的扇形图") 103 plt.show() 104 Pspot() 105 106 #排名与点击数的条形图 107 def Tspot(): 108 df = pd.DataFrame(pd.read_excel('爱奇艺排行.xlsx')) 109 x = df.排名 110 y = df.点击数 111 plt.xlabel("排名") 112 plt.ylabel("点击数") 113 plt.bar(x,y,color="green") 114 plt.title("排名与点击数的条形图") 115 plt.show() 116 Tspot() 117 118 #前五名的电影与点击数的条形图 119 def Tspot2(): 120 df = pd.DataFrame(pd.read_excel('爱奇艺排行.xlsx')) 121 x = df.电影名[:5] 122 y = df.点击数[:5] 123 plt.xlabel("电影名") 124 plt.ylabel("点击数") 125 plt.bar(x,y,color="green") 126 plt.title("电影名与点击数的条形图") 127 plt.show() 128 Tspot2() 129 130 #排名与点击数的折线图 131 def Zspot(): 132 df = pd.DataFrame(pd.read_excel('爱奇艺排行.xlsx')) 133 x = df.排名 134 y = df.点击数 135 plt.xlabel("排名") 136 plt.ylabel("点击数") 137 plt.plot(x,y,color="green",label="折线") 138 plt.title("排名与点击数的折线图") 139 plt.legend() 140 plt.show() 141 Zspot() 142 143 #回归直线的图 144 def huigui(): 145 #x,y为回归直线的排名和点击数 146 x = df.排名 147 y = df.点击数 148 #X,Y为散点图的 149 X = df.排名 150 Y = df.点击数 151 #先定义所需要的数据 152 x_i2=0 153 x_i =0 154 y_i=0 155 #计算出x,y的均值用mean() 156 q = x.mean() 157 w = y.mean() 158 for i in range(25): 159 x_i2 = x_i+x[i]*x[i] 160 x_i = x_i+x[i] 161 y_i = y_i+y[i] 162 #运用回归直线的公式计算出所需要的值 163 #分子 164 m_1 = x_i*y_i-25*q*w 165 #分母 166 m_2 = x_i2-25*q*q 167 #斜率 168 k = m_1/m_2 169 #截距 170 b = w-q*k 171 x=np.linspace(0,25) 172 y=k*x+b 173 print("斜率k=",k,"截距b=",b) 174 plt.figure(figsize=(6,4)) 175 plt.xlabel('排名') 176 plt.ylabel('点击数') 177 plt.scatter(X,Y,color="green",label="散点",linewidth=2) 178 plt.plot(x, y,color="blue",label= "回归直线") 179 plt.title("回归直线图") 180 plt.legend() 181 plt.show() 182 huigui()
四、结论
根据数据的图形分析,点击数会随着排名的降低呈现大幅度的下降
小结:在完成程序的过程,不断的探索,使我对函数的定义及爬虫的爬取更加精炼。本次任务,我受益良多。