上次说要爬取爱奇艺关于爱情公寓5的相关弹幕,然后今天看了一下,具体实现起来很简单, 这次主要是做个demo
实现
首先还是打开爱奇艺,选择爱情公寓5第一集,然后等待90s广告。(这个时候可以打开pycharm把必备的requests什么都写好放着)
然后去network找,发现好像没有明显的danmu字样,于是乎转到elements,随便点了一个弹幕,发现居然是动态加载的
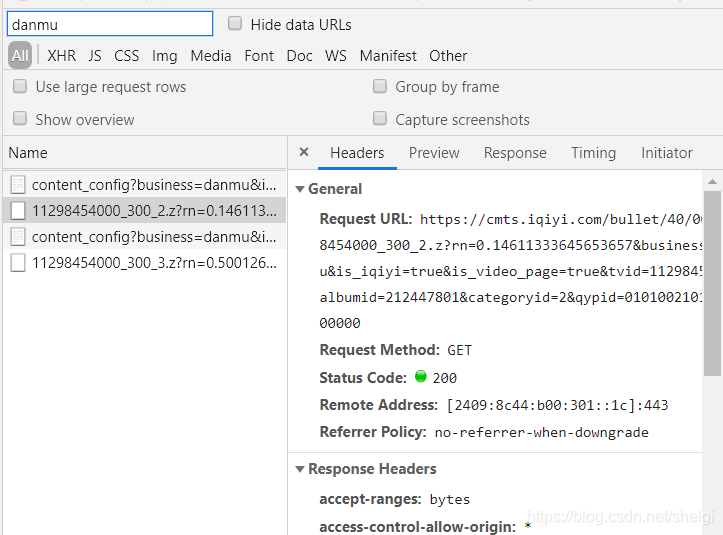
那我想应该是有文件的,然后懒得找了,直接去network搜danmu看会搜到什么吧,果然有个奇怪的网址

然后我点开网址预览是一堆乱码,下载下来一个.z文件的压缩包,打不开。。。但是我坚信这就是弹幕,毕竟business:danmu太明显了。然后用zlib打开,得到了我想要的。
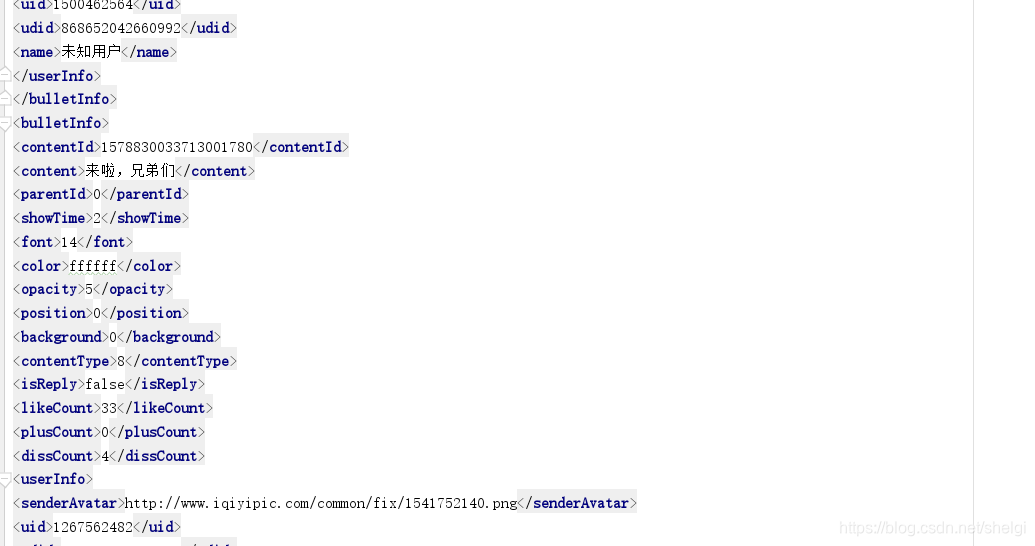
其中content就是弹幕内容啦。
再来看看url的构造,其实可以简化,只需要得到相应的tvid
#https://cmts.iqiyi.com/bullet/tvid倒数4位的前两位/tvid最后两位/tvid_300_x.z
#x的计算方式为片子总时长除以300秒向上取整,即按每5分钟一个包。
这样只要遍历x就能得到一集的弹幕,再遍历所有tvid,就可以得到全部的弹幕。
demo代码
import zlib
import requests
url='https://cmts.iqiyi.com/bullet/40/00/11298454000_300_1.z'
res=requests.get(url).content
zarray = bytearray(res)
xml=zlib.decompress(zarray, 15+32).decode('utf-8')
with open('./iqiyi.xml','w',encoding='utf-8') as f:
f.write(xml)
f.close()
这就把.z文件以二进制重新编码,写成xml形式,当然你也可以不写成xml,直接用正则提取xml其中的相关信息就好。
