scrapy说明
我的前文中有scrapy的安装和一些基础使用的说明,这里只是在此基础上使用scrapy对爱奇艺的电影的爬取,主要的爬取内容是 对电影分类下的爬取

爬取的主要内容
- 每个分类中的电影(PS爱奇艺把《夜闯寡妇村》分为恐怖。。。。。)
- 分别从 近期热门 ,免费电影,会员专享,最新上线,院线大片,评分最高进行爬取
- 小艺艺有个固定的套路,每个大类下10页,每页多少个,额,没数。
- 主要获取电影名称,主演和电影的链接。
页面分析
打开浏览器搜索“爱奇艺”
-
进去后按下键盘的这里——F12查看页面的源码
-
就会看到这页面
-
点击Network,
-
在Network中可以看到对应的请求和响应
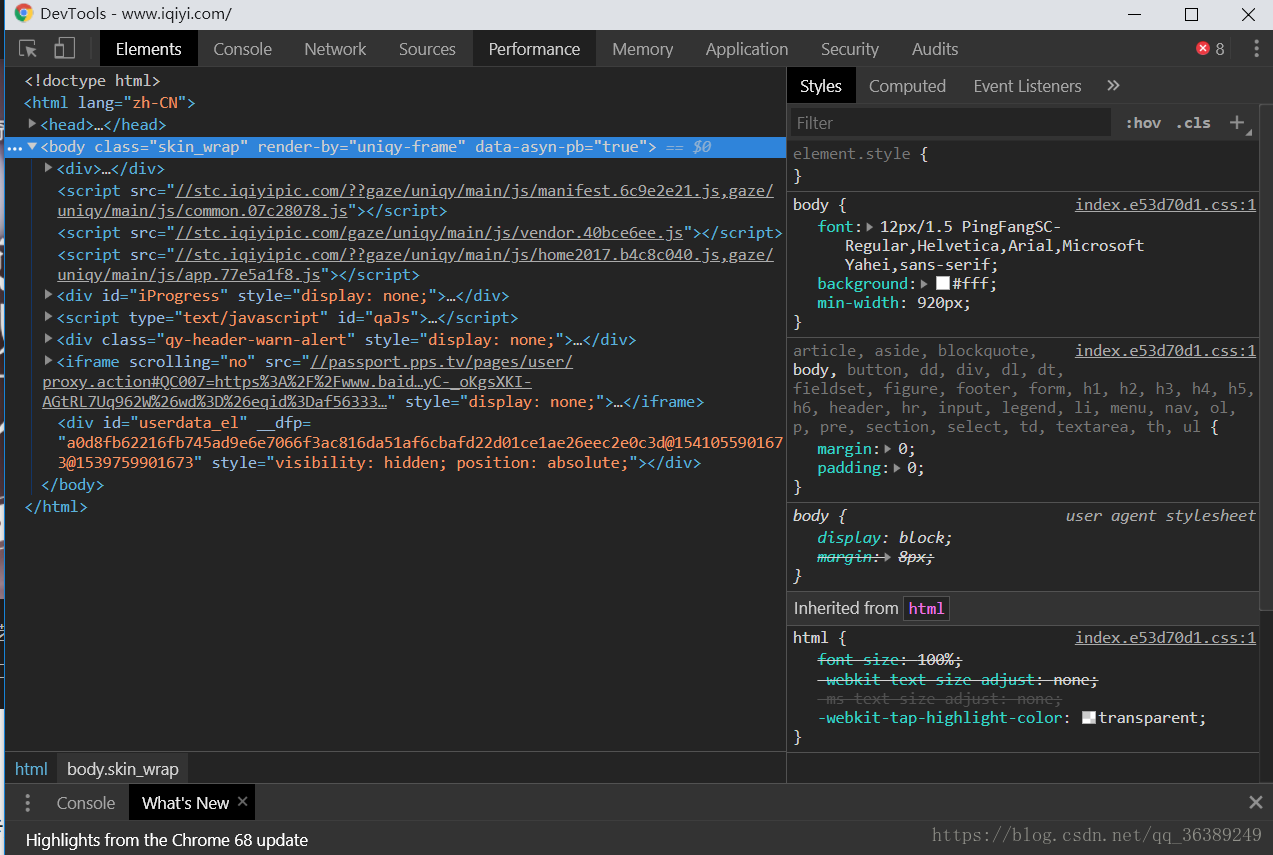
工程
- 打开自己的控制台,或者在对应的文件夹下使用shift+右击打开 Windows PowerShell
- 输入
scrapy startproject Iqiyi - 切换到对应的目录下,然后
scrapy genspider spider iqiyi.com - spider 为虫子的名字
- iqiyi.com是为了限制爬虫的爬取域,防止我们的虫子乱跑
- 然后利用pycharm打开我们的项目工程(pycharm的安装网上右很多的教程)
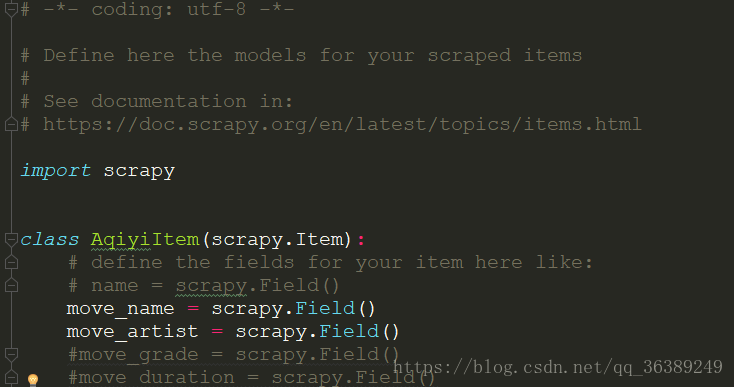
- 首先到items.py中设置需要爬取的内容
- 然后我们去进行爬虫的编写,在执行完
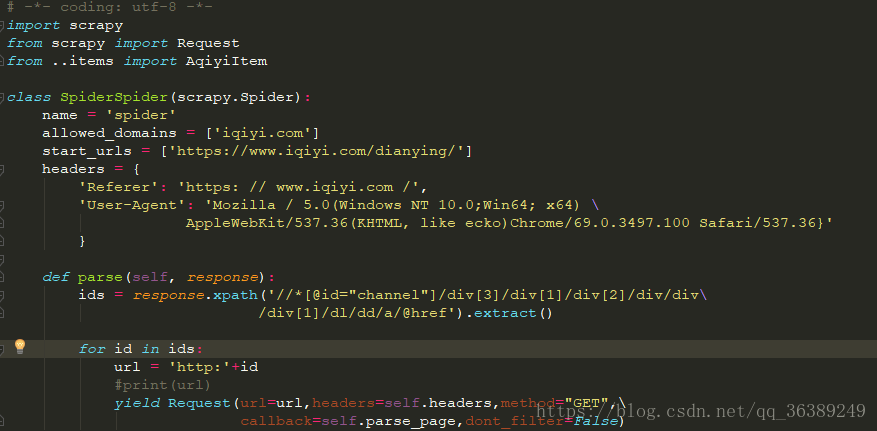
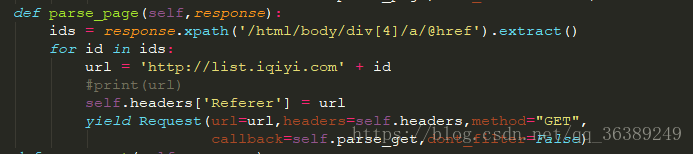
scrapy genspider spider iqiyi.com,会在spiders文件夹下生成一spider.py文件,我们的爬虫的逻辑主要在这里进行编写。 - 根据需要,我们首先要在小艺的电影首页获取6个分类界面的对应的URL。
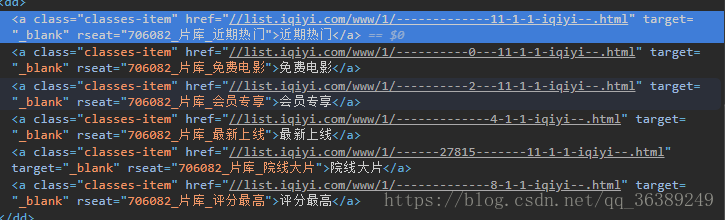
- 可以自己试着点开看,我就直接在chrome直接利用查看源码的方式进行查看
- - 这个对应的a标签下的href有半拉的URL,我们可以把它搞出来然后拼接成一个完整的URL,供我们继续使用
- 比较简单直接贴代码了
- 在 Request中最后的dont_filter = false 是为了去,比起用requests模块来书,需要自己进行去重处理,可以说是很简单了,有兴趣得按住ctrl点击过去看看底层的处理
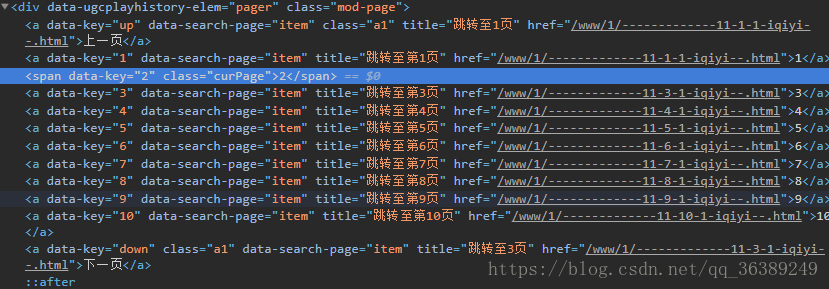
- 获取到各个也页面后就可以进行下一步了,每一类下有10页,首先得想办法打开这10页的对应得URL。
- 图上得那一堆就是对应的半拉得各个页面得地址,要做得就是把这个地址搞出来
- 上货
- 把获取的半拉地址进行拼接,然后将完整的URL通过get的方式进行提交。
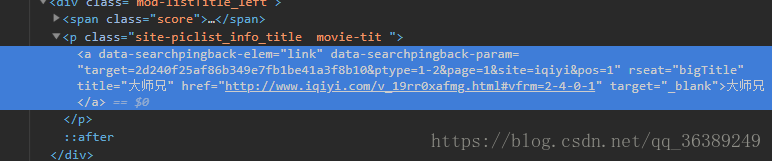
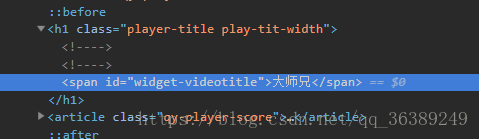
-现在我们可以获取各个类的完整的10个页面了,接下来就是获取每个电影了,接着对页面进行查看。 - 黝霍!!有完整的URL地址,以《大师兄》为例子,把他扒拉下来
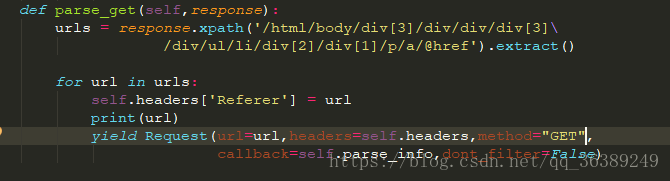
- 这下对应的每个类别下的电影就可以拿下来了,然后还是用大师兄的例子,获取他的演员表,和电影名称
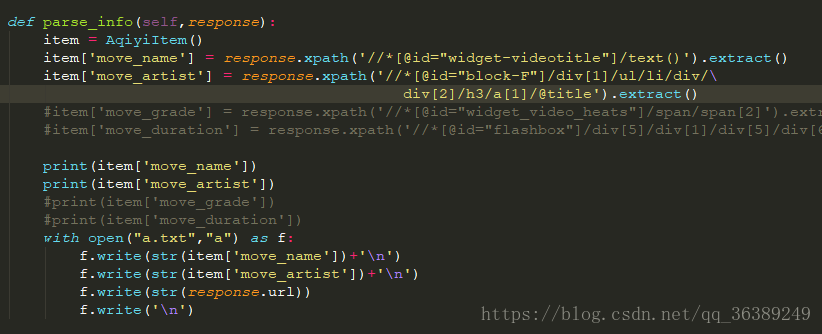
-这就是我们需要的信息了,没啥需要注意的,就直接上代码了- 这里可以先使用print()查看数据,等数据没有错误之后再放入文件
使用IP 代理
- IP代理的使用是为了防止我们在频繁访问时,被关小黑屋,找个马甲去访问,救不会直接被查了。、
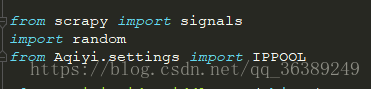
- 都知道在放出虫子时会经过中间件middleware,虫子才会到网上去爬,给虫子穿马甲的最合适的地方就是这个地方。
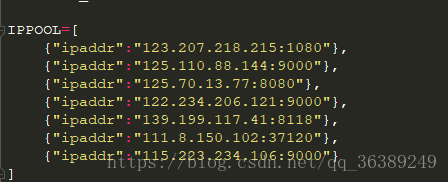
- 然后获取IP代理有好多方法,有免费,也有收费的,至于哪里有,出门左转,找百度。
- 首先打开settings.py文件,这里是对应虫子的一些相应的设置。
- 说到settings,这里有个ROBOTSTXT_OBEY,设置成False,不去检验robot.txt文档,让虫子为所欲为(。。其实不可能)
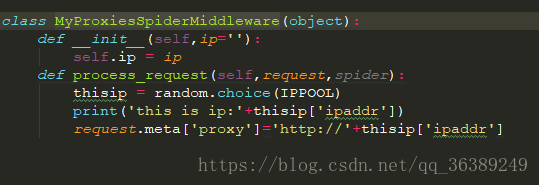
- 然后打开middlewares.py文件
- 这样就完成了马甲,在运行的时候有“主机链接失败”提示的时候换代理的Ip就好了。
- 然后打开settings进行设置、

数据的存储
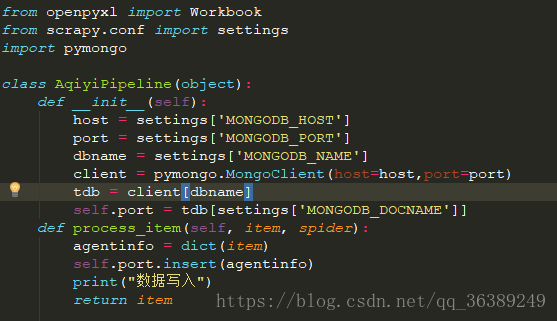
- 使用mongodb对数据进行存放
- 首先需要安装pymongo
pip install pymongo回车等待。。。。。。。。。。 - 打开piplienes.py
- 数据库的链接和写入,前提是本机得有数据库
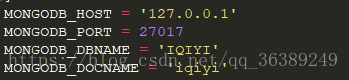
- 打开settings.py
- 放入对应得地址,端口号,库名和表名
程序运行
- 可以在控制台下输入
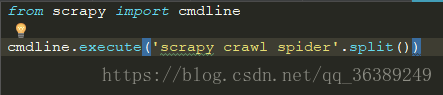
scrapy crawl spider回车运行 - 或者
- 在工程中得根目录下创建个start.py然后
- 利用框架自己带的工具
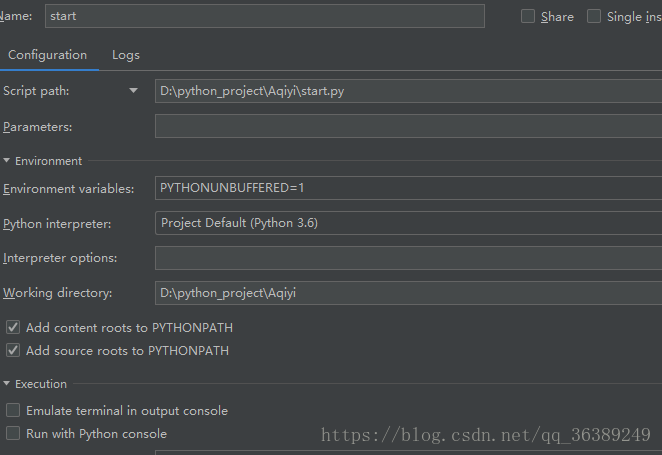
- 点击pychram菜单栏上的run--------->Edit configration ---->点击加号选择python
- 然后设置
- script path为srat的路径就可以了。
这就是以完整的小练习。
