一.主题式网络爬虫设计方案
1.主题式网络爬虫名称:爱奇艺电影网站排行榜数据分析
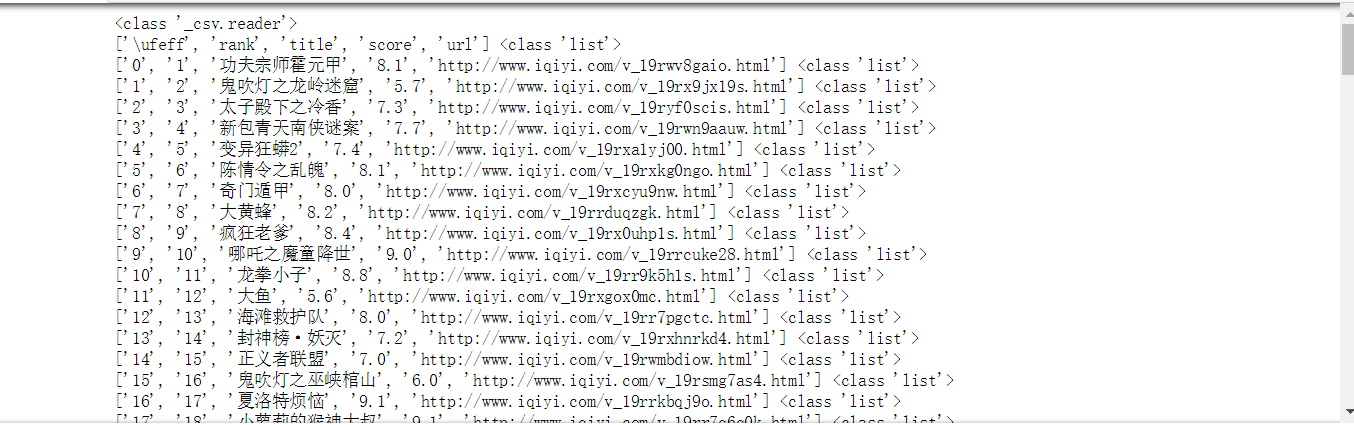
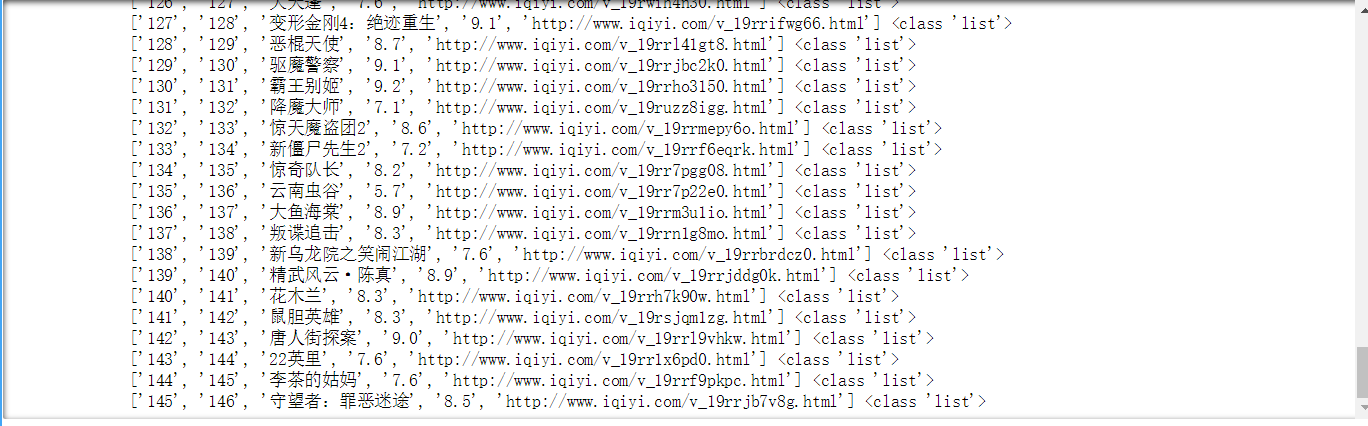
2.主题式网络爬虫爬取的内容:爱奇艺电影排行榜排名、评分等
3.设计方案概述:
实现思路:爬取网站内容,之后分析提取需要的数据,进行数据清洗,之后数据可视化,并计算评分和排名的相关系数
技术难点:网页结构复杂,需要提取的数据特征会略有变化
二、主题页面的结构特征分析
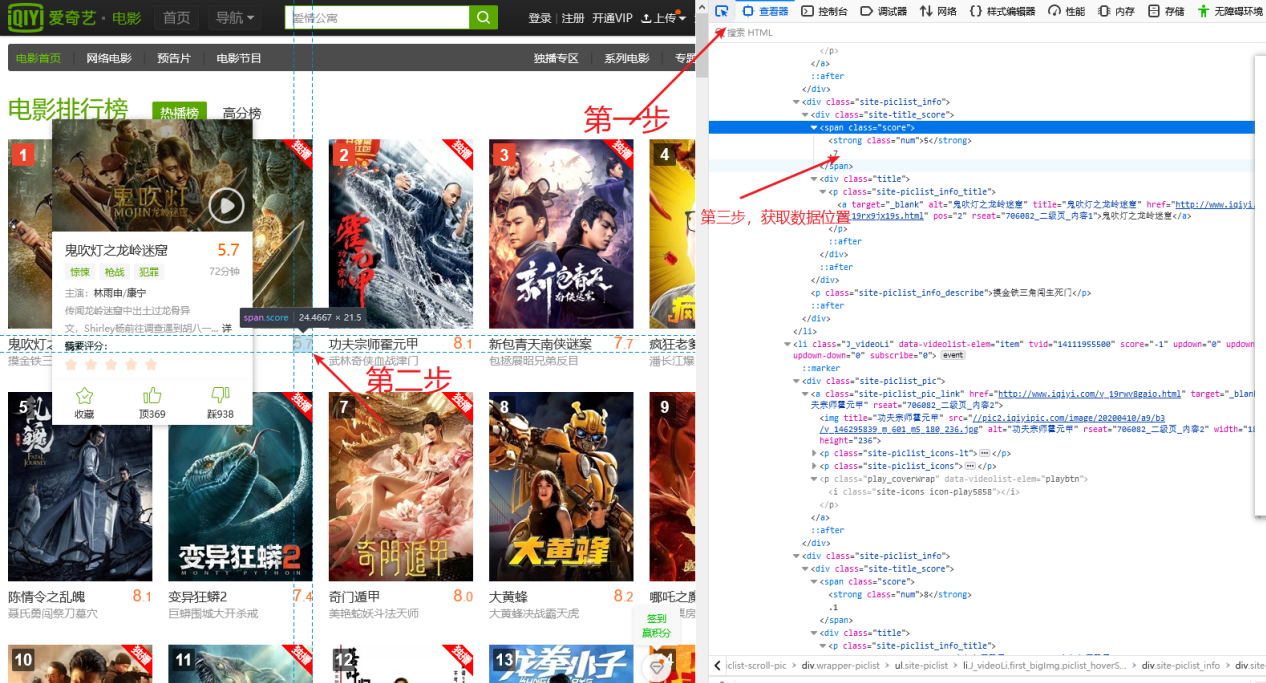
1.主题页面的结构与特征分析:打开开发者工具,通过逐个查找找到需要数据的所在位置,发现所需要的数据都在<ul class="site-piclist" data-widget-videolist="videolist" >下的<li
2.

三、网络爬虫程序设计
1.数据爬取与采集
import bs4 import requests import pandas as pd from bs4 import BeautifulSoup # 创建空词典 result = {"rank": [], # 标题 "title": [], # 主题 "score": [], # 价格 "url": [] # 地址 } def datas() :#封装爬取数据函数,以便后续使用 url = 'https://www.iqiyi.com/dianying_new/i_list_paihangbang.html' #按照获取的URL进行入参 res = requests.get(url) #获取网页内容 # print(res.status_code) #检查连接状态 bs = bs4.BeautifulSoup(res.text, 'html.parser') #用BS解释网页 datas = bs.find('ul',class_="site-piclist").find_all('li') for data in datas : mov_name = data.find('img')['title'] # 获取电影名字 try : mov_rank = data.find('span',class_='dypd_piclist_nub dypd_piclist_nubHot').text #获取电影排名,由于前三特征与后面的不同,因此采用试错历遍相关特征 except : mov_rank = data.find('span',class_='dypd_piclist_nub').text #同上 mov_score = data.find('span',class_='score').text #获取电影评分数据 url = data.find('a',class_='site-piclist_pic_link')['href'] result["rank"].append(mov_rank) # 排名 result["title"].append(mov_name) # 名字 result["score"].append(mov_score) # 评分 result["url"].append(url) # 评分 datas() # 将news_detail 中的每一条数据存到df中去 df = pd.DataFrame(result) # 将df的内容存到根目录下的“news.xlsx”文件中 df.to_csv('aiqiyi.csv',encoding='utf_8_sig')
2.对数据进行清洗和处理
3.文本分析(可选):因为都是数字,所以这里没有用到文本分析
4.数据分析与可视化:
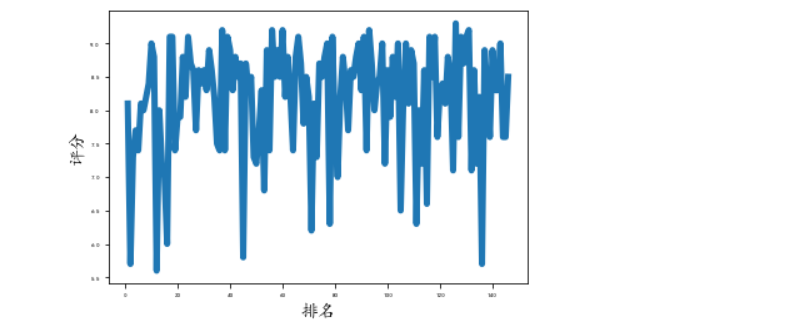
(1)折线图
import matplotlib.pyplot as plt import pandas as pd # 读取excel数据 data = pd.read_csv("aiqiyi.csv",usecols = [1,3]) # 转化成列表 df_li = data.values.tolist() rate1 = [] for s_li in df_li: rate1.append(s_li[0]) rate2 = [] for s_li in df_li: rate2.append(s_li[1]) input_value = rate1 squares = rate2 plt.plot(input_value, squares, linewidth=5) # 设置图表标题,并给坐标轴加标签 plt.xlabel("排名", fontsize=14) plt.ylabel("评分", fontsize=14) # 设置刻度标记的大小 plt.tick_params(axis='both', labelsize=5) # 展示图像 plt.show() # 保存图片 plt.savefig("line_chart.png",right=0.9)
(2)条形图
import pandas as pd import matplotlib.pyplot as plt #解决中文显示问题 plt.rcParams['font.sans-serif'] = ['KaiTi'] # 指定默认字体 plt.rcParams['axes.unicode_minus'] = False # 解决保存图像是负号'-'显示为方块的问题 # 读取excel数据 data = pd.read_csv("aiqiyi.csv",usecols = [1,3]) # 转化列表 df_li = data.values.tolist() # 转化列表 all_lists = [] for s_li in df_li: all_lists.append(s_li[1]) # 横轴标签 keys = ["5.1-6","6.1-7","7.1-8","8.1-9"] # 创建空词典 results = {} for key in keys: results.update({key:[]}) # 将数据存储到词典 for i in all_lists: if int(i) >= 5.1 and int(i) <= 6: results[keys[0]].append(i) elif int(i) >= 6.1 and int(i) <= 7: results[keys[1]].append(i) elif int(i) >= 7.1 and int(i) <= 8: results[keys[2]].append(i) elif int(i) >= 8.1 and int(i) <= 9: results[keys[3]].append(i) print(results) # 统计面积的个数 for result in results: results[result] = len(results[result]) # 标题 plt.title('爱奇艺评分统计图') #案例1:直辖市GDP水平 #构建数据 GDP=results.values() print(GDP) #绘图 plt.bar(range(len(GDP)),GDP, align='center',color='blue',alpha=0.8) #添加轴标签 plt.ylabel('评论数') #添加刻度标签 plt.xticks(range(len(GDP)),results.keys()) # 横轴标签旋转90度 plt.xticks(rotation = 90) #为每一个图形加数值标签 for x,y in enumerate(GDP): plt.text(x,y+1,y,ha='center') # 保存图像 plt.savefig('Bar_Graph.png') #显示图形 plt.show()
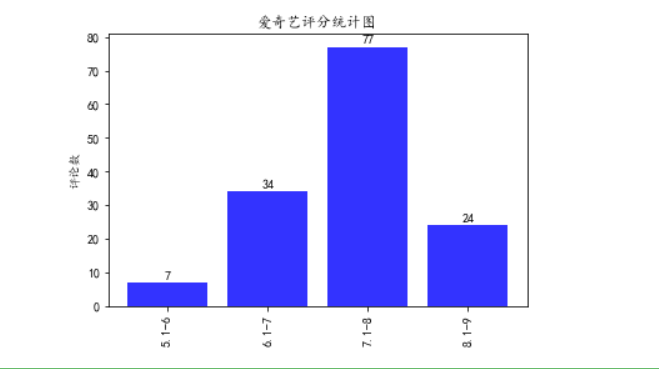
(3)饼状图
import matplotlib.pyplot as plt import pandas as pd #解决中文显示问题 plt.rcParams['font.sans-serif'] = ['KaiTi'] # 指定默认字体 plt.rcParams['axes.unicode_minus'] = False # 解决保存图像是负号'-'显示为方块的问题 # 读取excel数据 data = pd.read_csv("aiqiyi.csv",usecols = [1,3]) # 转化列表 df_li = data.values.tolist() # 转化列表 all_lists = [] for s_li in df_li: all_lists.append(s_li[1]) # 横轴标签 keys = ["5.1-6","6.1-7","7.1-8","8.1-9"] # 创建空词典 results = {} for key in keys: results.update({key:[]}) a=0 b=0 c=0 d=0 # 将数据存储到词典 for i in all_lists: if int(i) >= 5.1 and int(i) <= 6: a = a + 1 elif int(i) >= 6.1 and int(i) <= 7: b = b + 1 elif int(i) >= 7.1 and int(i) <= 8: c = c + 1 elif int(i) >= 8.1 and int(i) <= 9: d = d + 1 results[keys[0]].append(a) results[keys[1]].append(b) results[keys[2]].append(c) results[keys[3]].append(d) # 饼状图标题 plt.title('爱奇艺排行榜饼状图') # 饼状图颜色 colors = ['red','yellowgreen','blue','lightskyblue','tomato','cornflowerblue'] # 饼状图 plt.pie(results.values(),autopct='%1.1f%%',labels=results.keys(),colors=colors) # 饼状图右侧标签 plt.legend(loc='upper right') # 饼状图 plt.axis('equal') plt.savefig("Pie_chart.png",right=0.7) plt.show()
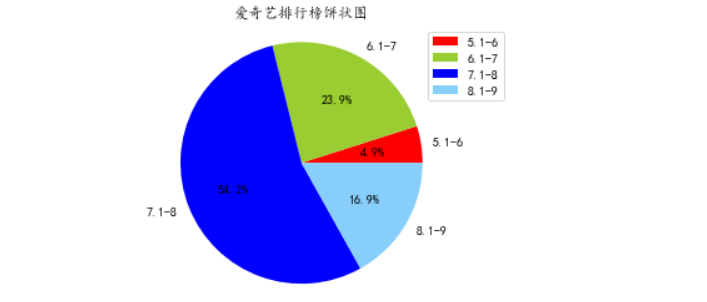
(4)散点图
import matplotlib.pyplot as plt import numpy as np import pandas as pd #解决中文显示问题 plt.rcParams['font.sans-serif'] = ['KaiTi'] # 指定默认字体 plt.rcParams['axes.unicode_minus'] = False # 解决保存图像是负号'-'显示为方块的问题 # 读取excel数据 data = pd.read_csv("aiqiyi.csv",usecols = [1,3]) # 转化成列表 df_li = data.values.tolist() rate1 = [] for s_li in df_li: rate1.append(s_li[0]) rate2 = [] for s_li in df_li: rate2.append(s_li[1]) xValue = rate1 yValue = rate2 plt.title(u'爱奇艺排行榜散点图') plt.xlabel('名次') plt.ylabel('评分') plt.legend() plt.scatter(xValue, yValue, s=20, c="#ff1212", marker='o') plt.show() plt.savefig("Scatter.png",right=0.7)

6.数据持久化
import csv if __name__ == "__main__": with open("aiqiyi.csv",'r',encoding='UTF-8') as csvFile: reader = csv.reader(csvFile) print(type(reader)) for i in reader: print(i,type(i))