前言
之前学过一些tensorflow,上手有那么一点小难,现在也没太玩明白,最近学习paddlehub感觉到了百度爸爸的魅力,免费的cpu、gpu总是那么的好用,paddlehub上手还是感觉很简单,今天写下观看百度教程的第五节大作业。
作业要求
作业网址:添加链接描述
作业简介:

步骤
这里之前学过了爬虫没想到居然这么有用哈哈哈,题目中的绘制词云就懒得弄了主要体会下爬取评论和敏感分析。
分析网页
网页地址:青春有你
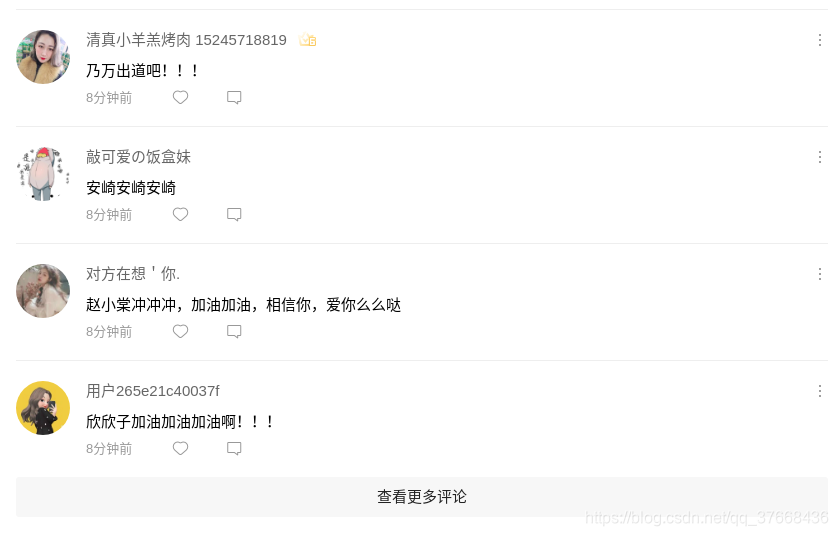
网页底部加载更多的评论需要点击查看更多评论,不然就只能看到这一页的所有评论没有下一页的,这种解决办法有两种:
- 一是使用selenium库的webdriver控制浏览器模拟点击按钮
- 二是模拟点击查看更多评论按钮点击发起的requests请求
个人感觉第一种办法应该算是万精油吧,代码写起来简单不用去分析request请求,也不用去了解网站的规则,但是稍微感觉笨拙了点。
这里主要使用第二种方法,首先便是使用谷歌浏览器的检查功能分析网页,打开Network:
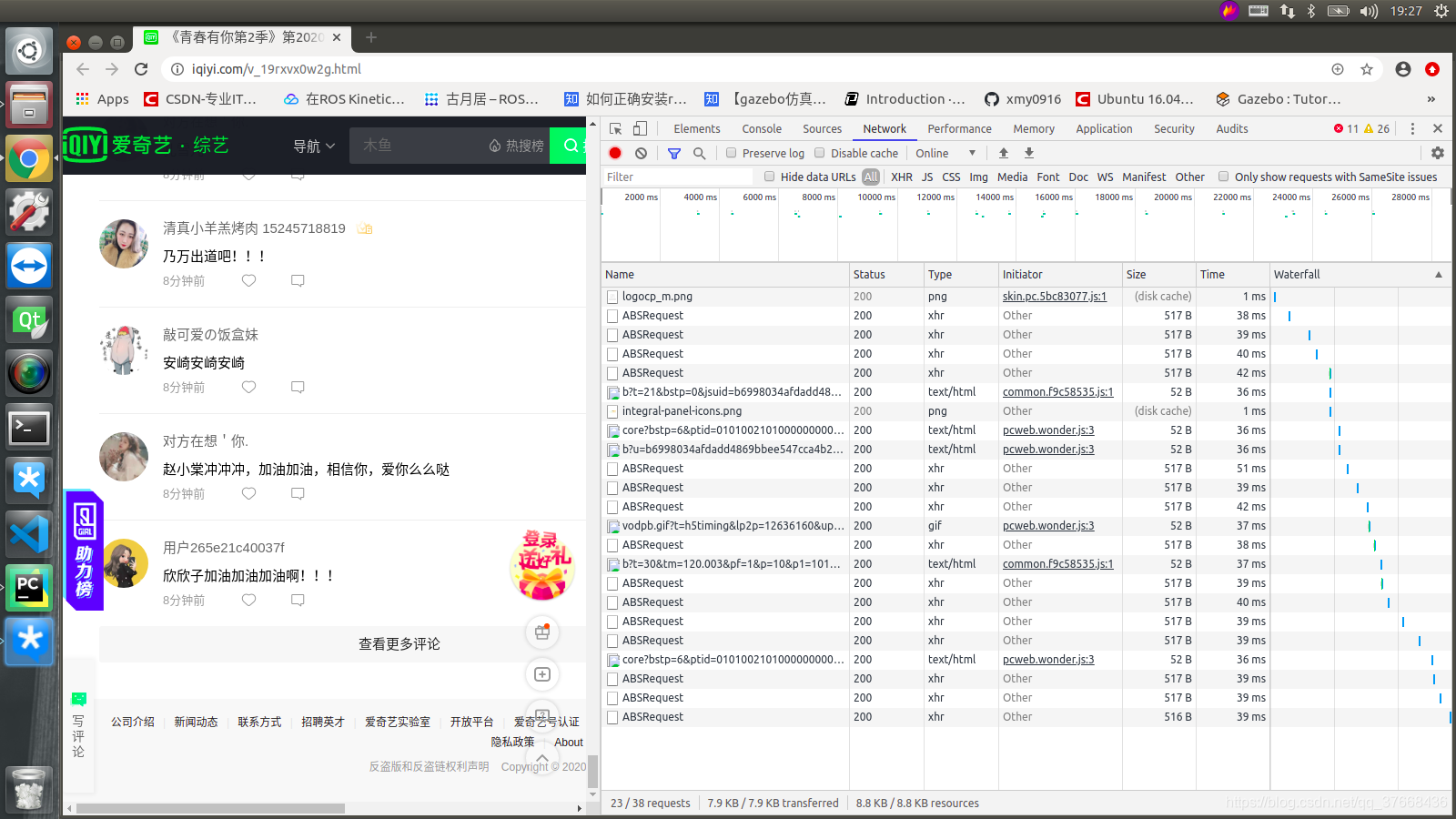
可以看到name一栏有很多正在发起的请求,我们点击查看更多评论看下此时网页发起的请求:
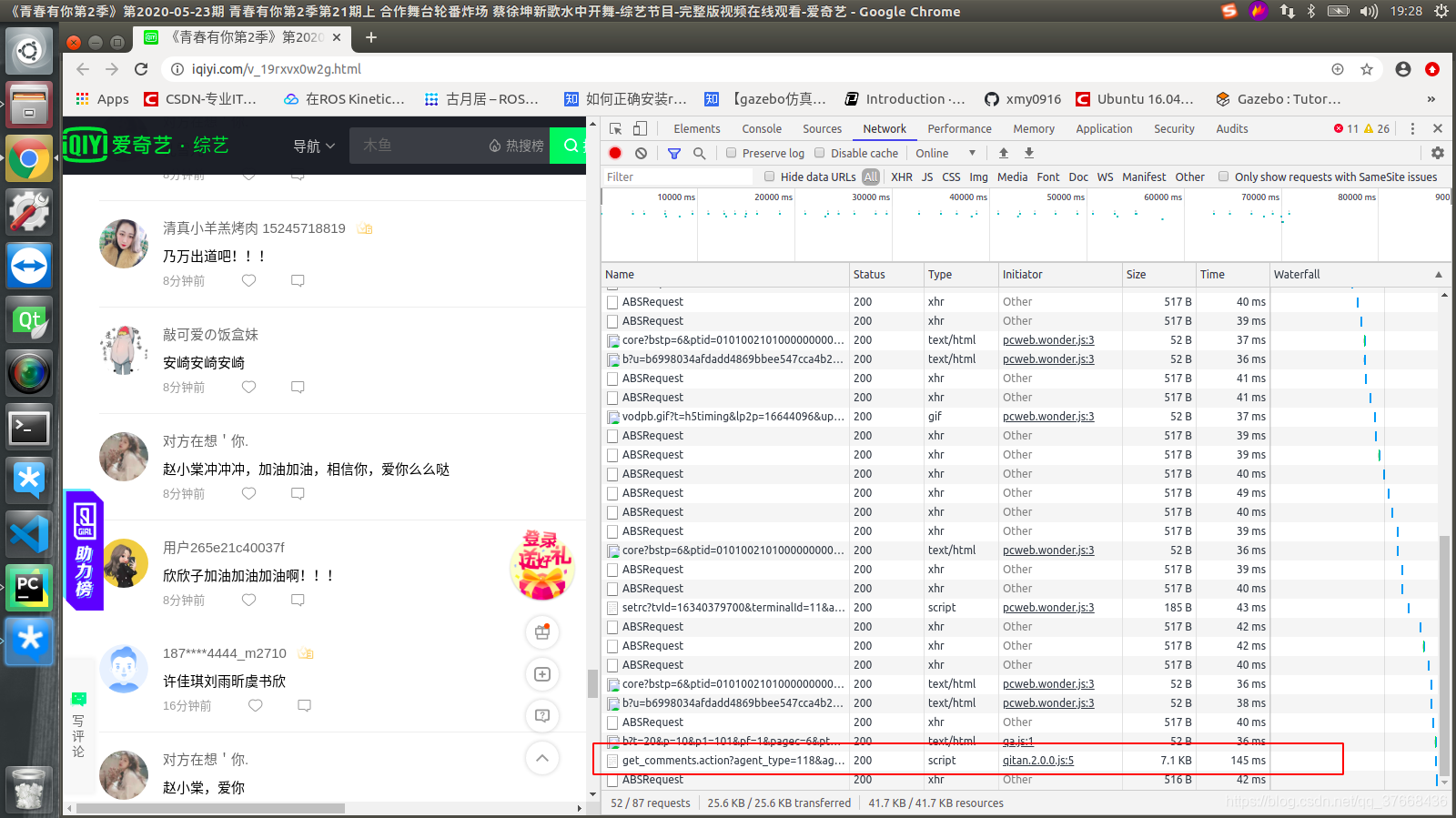
显而易见就是这个get_comments了,点击它查看它请求的url:
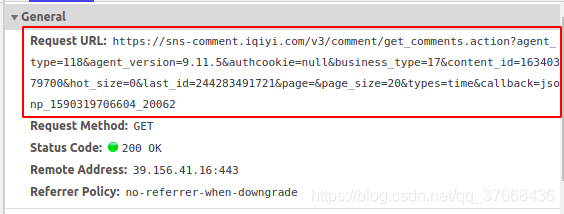
一个看不出啥规律,再看一个:
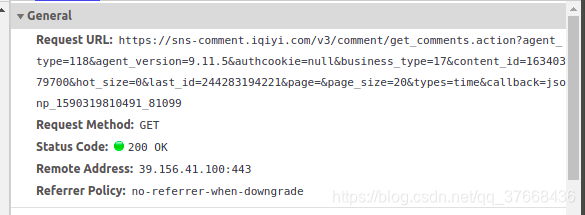
可以看到唯一变化的就是url中的last_id了,然后查看请求的url详情:
网址如下:请求的url
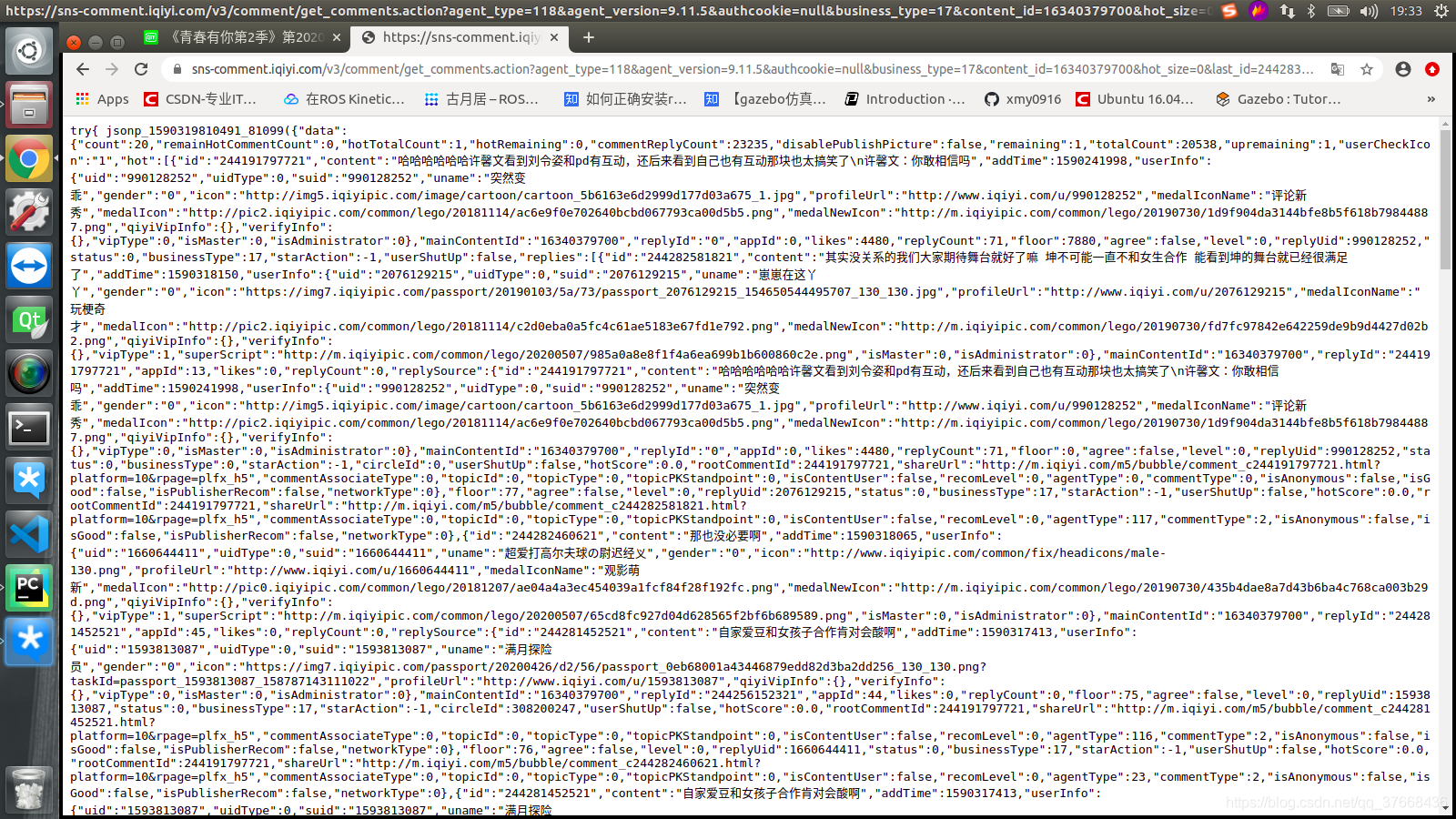
搜索id关键字:
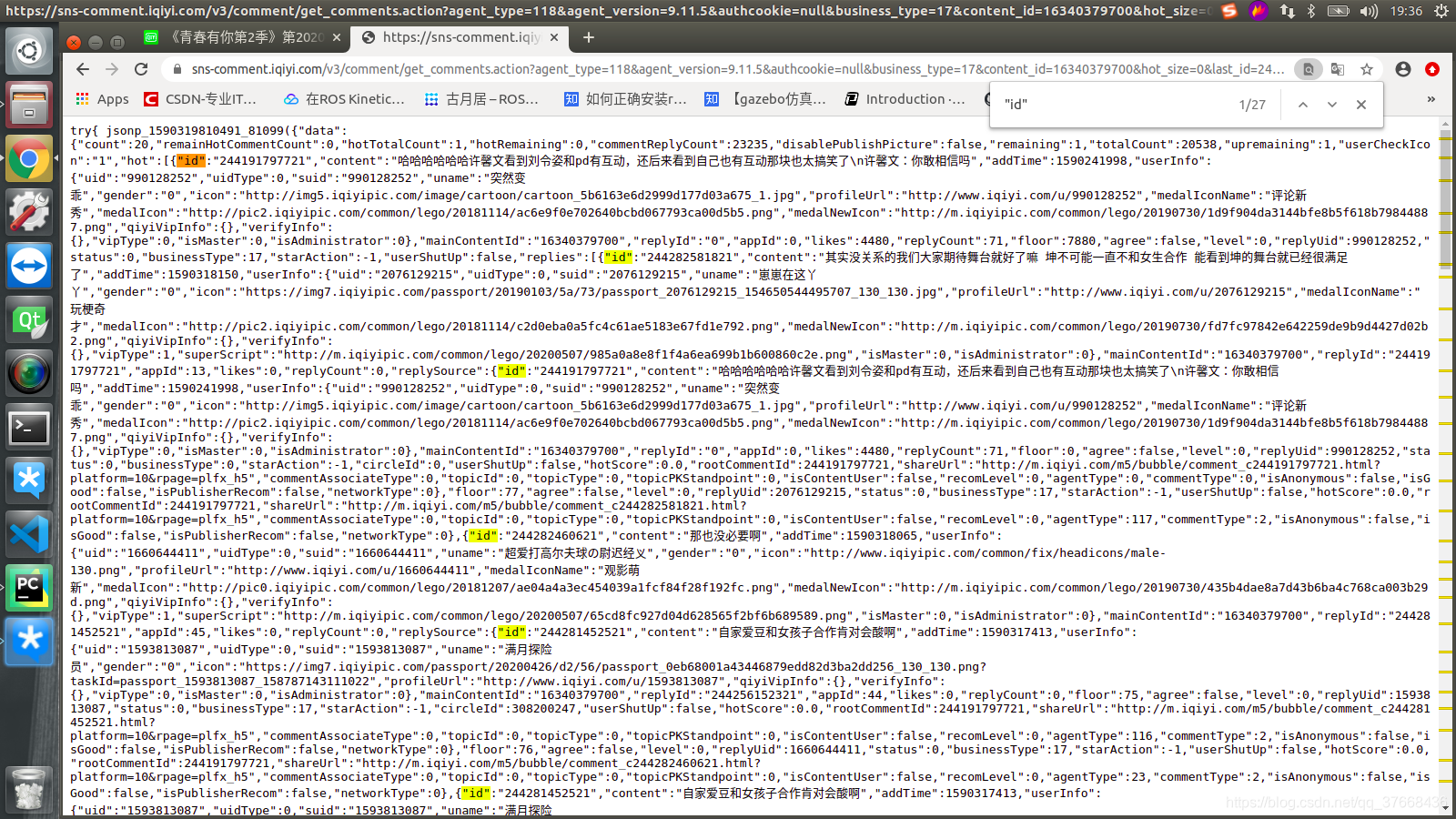
发现id和我们last_id的格式是一样的,这里基本可以猜想那个last_id就是当前界面显示的最下面一条的ID号,用此来记录新一页评论的ID起始位置。
编写代码
获取网页内容
def getMovieinfo(url):
'''
请求爱奇艺评论接口,返回response信息
参数 url: 评论的url
:return: response信息
'''
session = requests.Session()
headers = {
"User-Agent": "Mozilla/5.0",
"Accept": "application/json",
"Referer": "http://m.iqiyi.com/v_19rqriflzg.html",
"Origin": "http://m.iqiyi.com",
"Host": "sns-comment.iqiyi.com",
"Connection": "keep-alive",
"Accept-Language": "en-US,en;q=0.9,zh-CN;q=0.8,zh;q=0.7,zh-TW;q=0.6",
"Accept-Encoding": "gzip, deflate"
}
response = session.get(url, headers=headers)
if response.status_code == 200:
return response.text
return None
这段就是发起request请求得到response没什么难度。
解析网页
解析网页需要提取关键信息,信息取掉非法字符,信息写入本地,首先是去掉非法字符的函数:
def clear_special_char(content):
'''
正则处理特殊字符
参数 content:原文本
return: 清除后的文本
'''
s = re.sub(r"</?(.+?)>| |\t|\r", "", content)
s = re.sub(r"\n", " ", s)
s = re.sub('[^\u4e00-\u9fa5^a-z^A-Z^0-9]', '', s)
return s
sub函数就是将匹配到的re规则替换成参数中第二个,这里全是空格或者空也就是去掉匹配到的内容,这段re规则说实话每太看明白,先放放吧。
解析网页并写入本地文件:
def getCommentsAndID(html,lastId,arr):
comments = re.findall(r'"content":".*?"',html)
lastIDs = re.findall(r'"id":"\d+"',html)
with open('aqy.txt', 'a', encoding='utf-8') as f:
for i in range(len(comments)):
comment = comments[i].split(':')[1]
lastId = eval(lastIDs[i].split(":")[1])
comment = clear_special_char(comment)
arr.append(comment)
try:
f.write(comment + "\n")
except:
print("写入失败:" + comment)
return lastId
这里思路很简单就是逐个遍历匹配到的评论的id然后更新last_id,并且把评论信息去掉非法字符然后写入本地文件。这里匹配关键信息用的re规则也很简单:
r'"content":".*?"'
它能匹配的样式如下:
"content":"你好呀"
- “content”:是规则和匹配对象相对应没啥好说的
- 后面一串中的“ . ”表示某个字符
- 后面一串中的“ * ”表示对前一个字符做n次扩展,就是可以匹配n个字符的意思
- 后面一串中的“ ? ”表示对前一个字符做0或1次扩展
调用paddlehub训练好的lstm网络模型分析敏感词
def text_detection(text,file_path):
'''
使用hub对评论进行内容分析
return:none
'''
porn_detection_lstm = hub.Module(name="porn_detection_lstm")
f = open('aqy.txt', 'r',encoding='utf-8')
for line in f:
if len(line.strip()) == 1: #判断评论长度是否为1
continue
else:
test_text.append(line)
f.close()
input_dict = {"text": test_text}
results = porn_detection_lstm.detection(data=input_dict,use_gpu=True, batch_size=1)
# print(results)
for index, item in enumerate(results):
if float(item['porn_probs']) > 0.95 :
print(item['text'],':',item['porn_probs'])
完整代码
import requests
import re
import paddlehub as hub
def getCommentsAndID(html,lastId,arr):
comments = re.findall(r'"content":".*?"',html)
lastIDs = re.findall(r'"id":"\d+"',html)
with open('aqy.txt', 'a', encoding='utf-8') as f:
for i in range(len(comments)):
comment = comments[i].split(':')[1]
lastId = eval(lastIDs[i].split(":")[1])
comment = clear_special_char(comment)
arr.append(comment)
try:
f.write(comment + "\n")
except:
print("写入失败:" + comment)
return lastId
def getMovieinfo(url):
'''
请求爱奇艺评论接口,返回response信息
参数 url: 评论的url
:return: response信息
'''
session = requests.Session()
headers = {
"User-Agent": "Mozilla/5.0",
"Accept": "application/json",
"Referer": "http://m.iqiyi.com/v_19rqriflzg.html",
"Origin": "http://m.iqiyi.com",
"Host": "sns-comment.iqiyi.com",
"Connection": "keep-alive",
"Accept-Language": "en-US,en;q=0.9,zh-CN;q=0.8,zh;q=0.7,zh-TW;q=0.6",
"Accept-Encoding": "gzip, deflate"
}
response = session.get(url, headers=headers)
if response.status_code == 200:
return response.text
return None
def clear_special_char(content):
'''
正则处理特殊字符
参数 content:原文本
return: 清除后的文本
'''
s = re.sub(r"</?(.+?)>| |\t|\r", "", content)
s = re.sub(r"\n", " ", s)
s = re.sub('[^\u4e00-\u9fa5^a-z^A-Z^0-9]', '', s)
return s
def text_detection(text,file_path):
'''
使用hub对评论进行内容分析
return:none
'''
porn_detection_lstm = hub.Module(name="porn_detection_lstm")
f = open('aqy.txt', 'r',encoding='utf-8')
for line in f:
if len(line.strip()) == 1: #判断评论长度是否为1
continue
else:
test_text.append(line)
f.close()
input_dict = {"text": test_text}
results = porn_detection_lstm.detection(data=input_dict,use_gpu=True, batch_size=1)
# print(results)
for index, item in enumerate(results):
if float(item['porn_probs']) > 0.95 :
print(item['text'],':',item['porn_probs'])
if __name__ == '__main__':
base_url = "https://sns-comment.iqiyi.com/v3/comment/get_comments.action?agent_type=118&agent_version=9.11.5&authcookie=null&business_type=17&content_id=16340379700&hot_size=0&last_id="
lastId = "0"
page = 20
comments = []
for i in range(page):
response = getMovieinfo(base_url + lastId)
lastId = getCommentsAndID(response,lastId,comments)
print(comments)
'''
使用hub对评论进行内容分析
'''
file_path = 'aqy.txt'
test_text = []
text_detection(test_text, file_path)
pycharm下运行代码
首先安装一下模块:
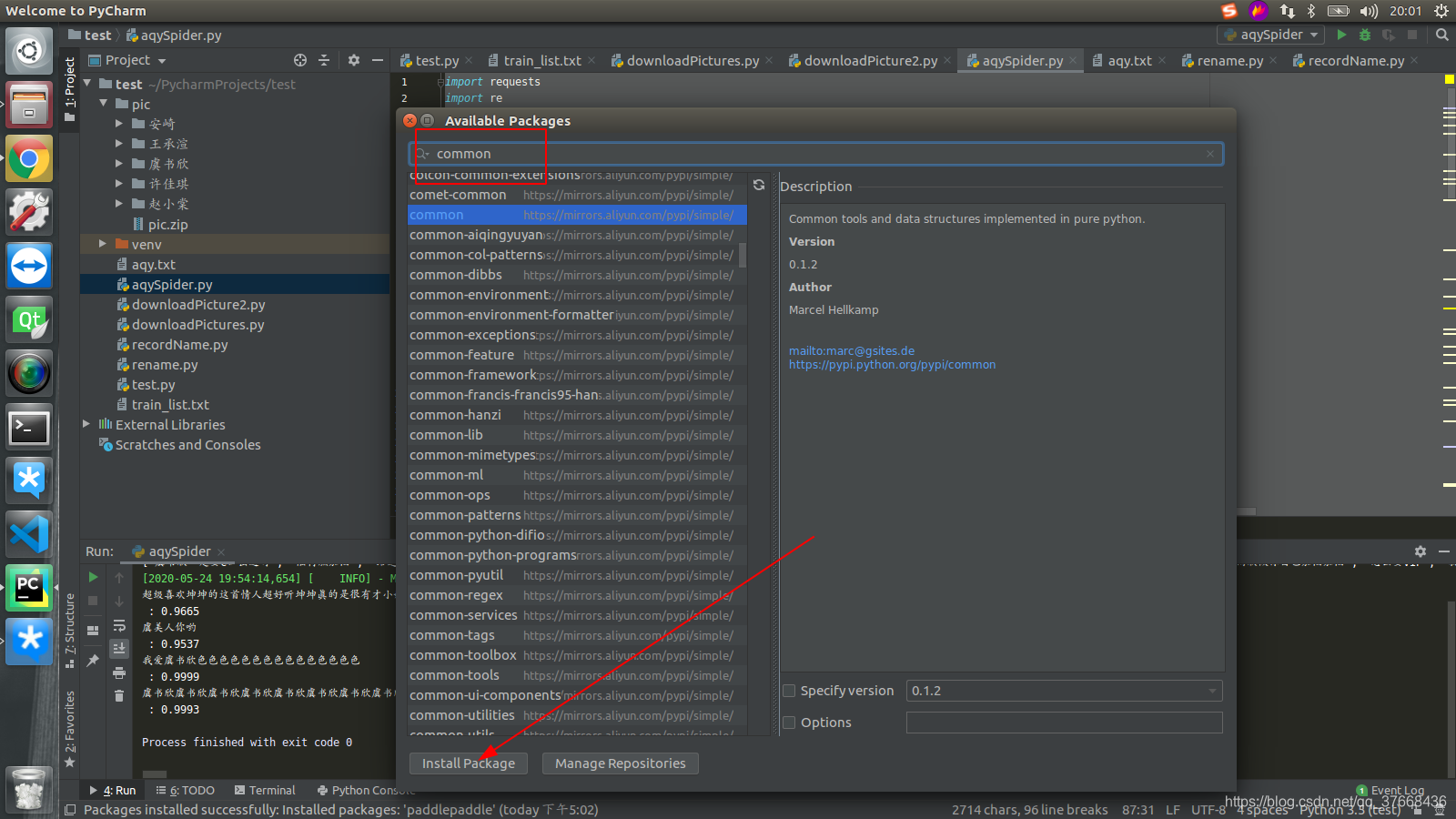
common、dual、tight 、data、prox、paddlepaddle、paddlehub
直接在:
file -> settings -> Project:project_name -> Project Interpreter -> +号
搜索这几个名字然后点击Install Package即可:
然后安装网络训练好的模型文件,在pycharm的终端输入:
hub install porn_detection_lstm==1.1.0
一切就绪后点击pycharm的运行,结果如下:
