文章目录
Bi-LSTM-CRF
1. CRF模型原理
1.1 HMM与MEMM

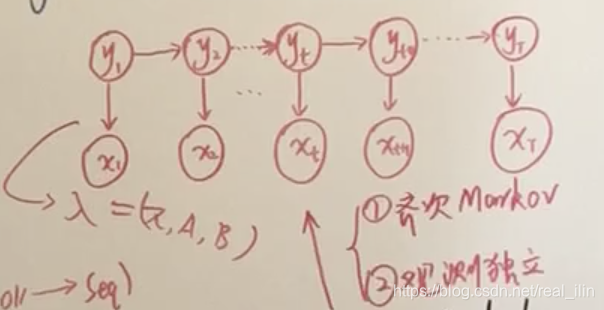
- HMM
是概率生成模型,对 建模,也就是随机变量X和Y的联合概率分布建模。
有两个假设:马尔可夫齐次假设和观测独立假设
对于词性标注问题来说,观测变量之间是相互独立的
- MEMM(maximum entropy markov model)
最大熵马尔可夫模型与HMM的不同是,在概率图上,x与y之间的箭头的方向发生了变化。HMM是从y->x而MEMM模型是x->y。本质上是把x由y影响变为了y受x影响,并且只是当前状态的x,比如t时刻的 是受 所有 的影响的。概率图的上半部分也是这个意思,x只用了一个节点,但是是输出到每一个y的,也表达了每个时刻的y是受全部x影响的。
这样就打破了HMM模型的观测独立假设,在词性标注中,一个词的词性不仅受当前词的影响,也受到上下文的影响。

1.2 MEMM与CRF,标注偏差问题
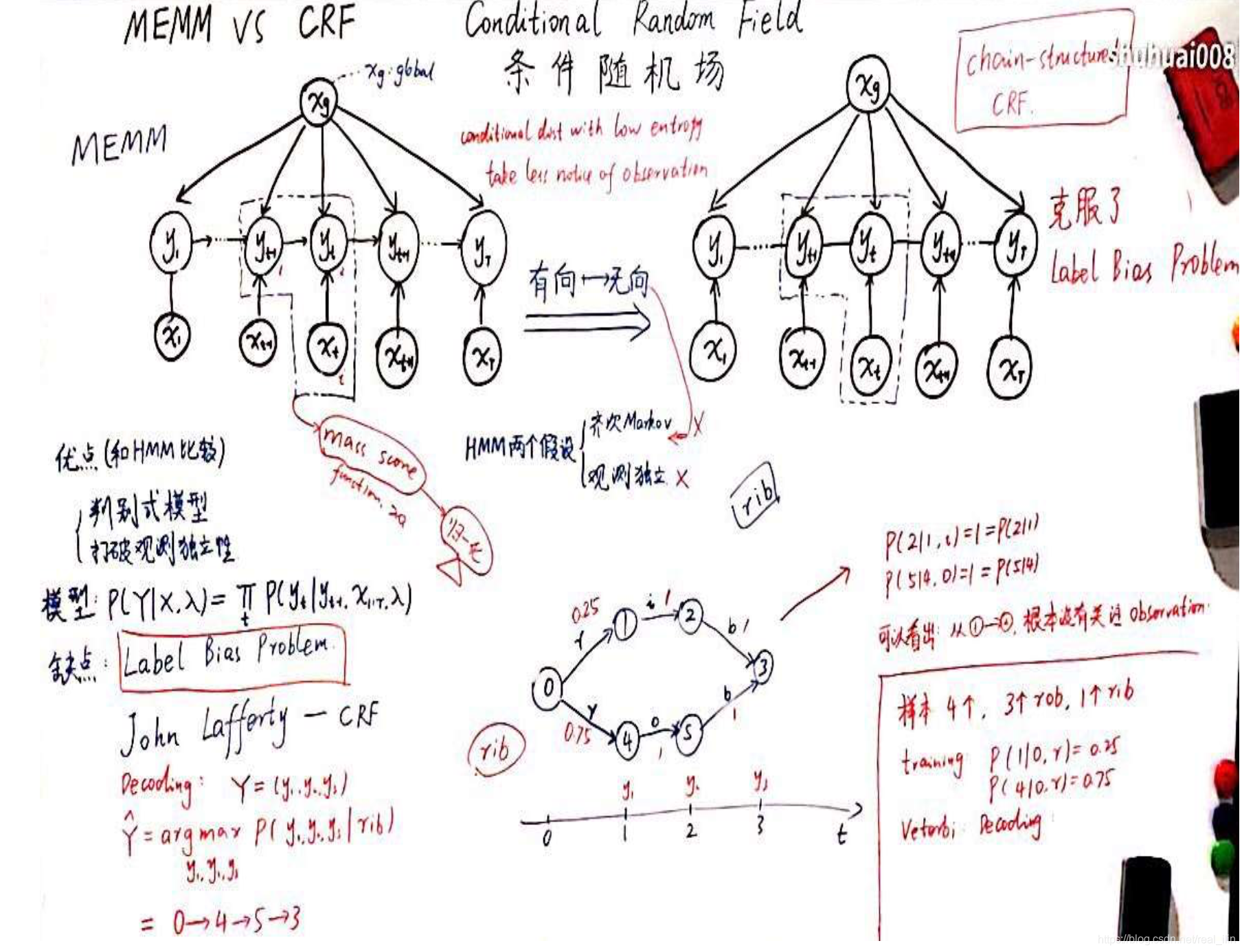
MEMM的问题是标注偏差,原因是局部归一化造成的。在每个时刻都要做归一化,这样处理是有问题的。比如
是一个概率分布,则关于
的函数必须要做归一化处理。
举一个例子:有四个样本,三个rob,一个rib,rib的路径是从0->1->2->3,而rob的路径是0->4->5 ->3。在状态1、2及状态4、5时转化为下一个状态的概率是1。也就是说从1到2时,只有一条路径,不管观测值是字母i还是其它的。4到5时候也是同理。条件概率在熵越小的时候,观测值对状态转化的影响就越小。
CRF对MEMM的优化就是把有向图变为了无向图,无向图有天然的全局归一化。随机变量y之间没有了箭头,x到y仍然有箭头,x是输入。
1.3 CRF模型的参数形式
求条件概率
的概率密码函数,概率分布。
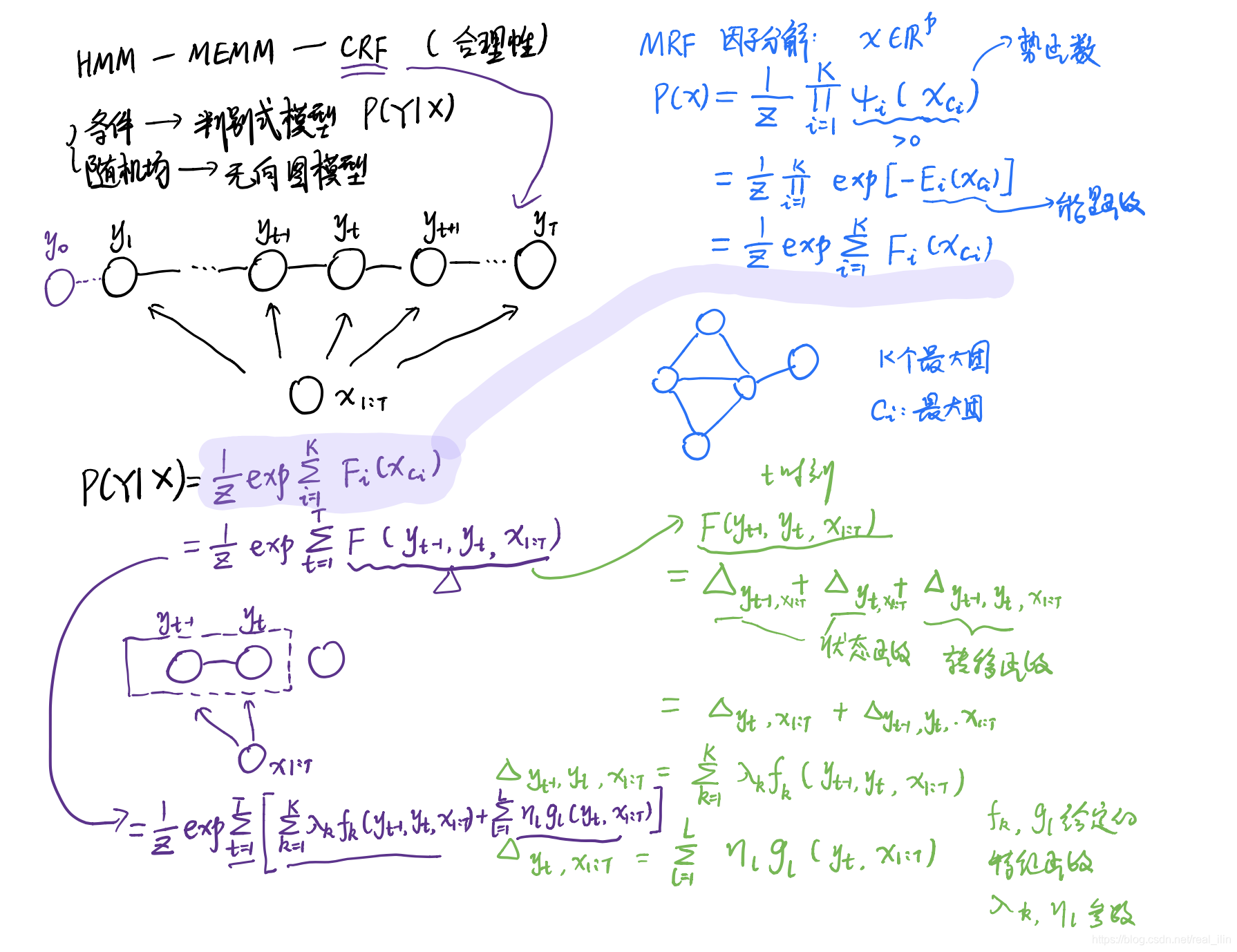
1.4 CRF模型的向量形式

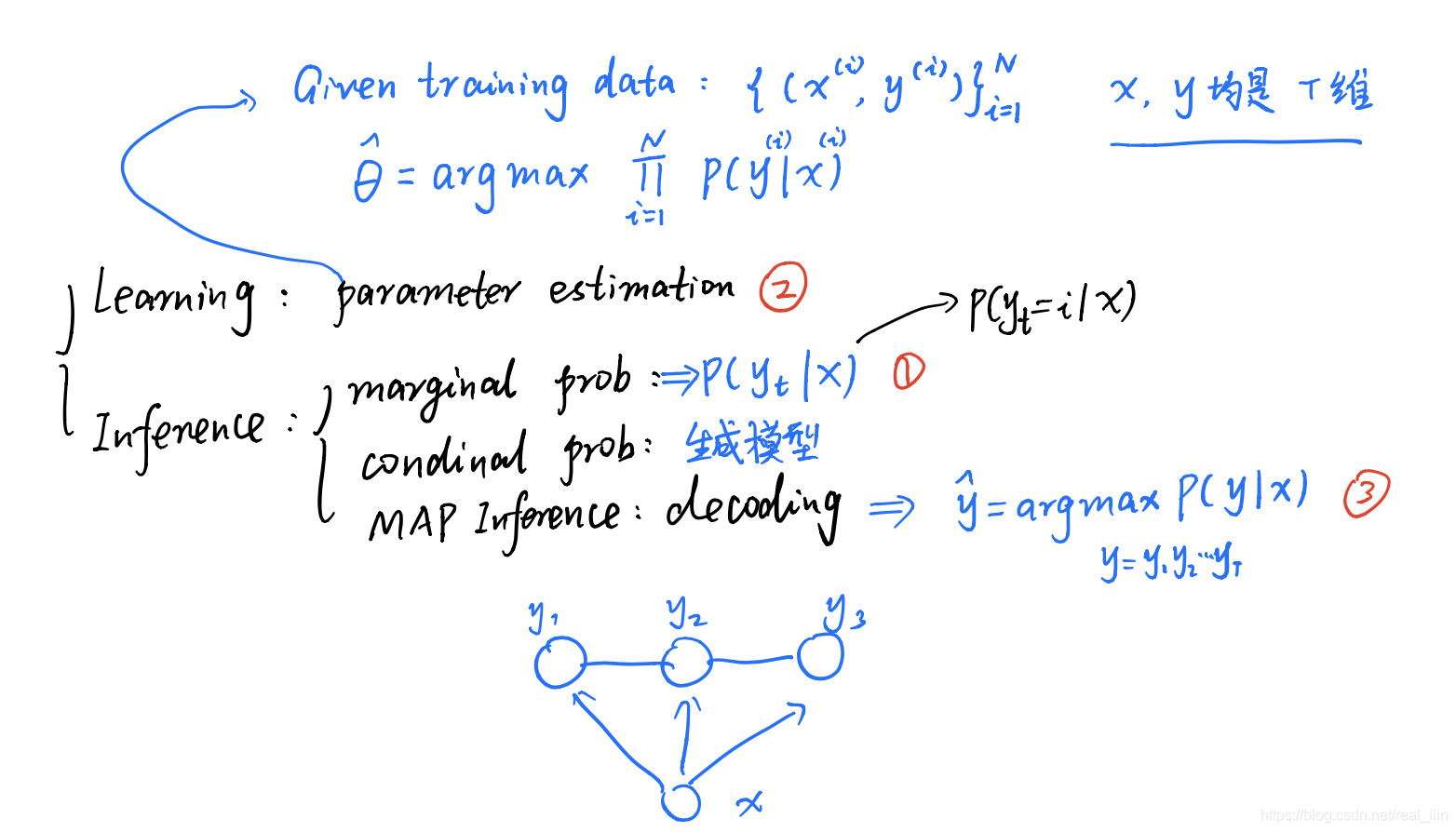
1.5 CRF要解决的问题
- 边缘概率计算
- 参数估计,也就是learning问
- MAP inference,也就是decoding问题
2. Bi-LSTM-CRF模型原理
最通俗易懂的BiLSTM-CRF模型中的CRF层介绍
知乎上的这篇讲的很好,既通俗易懂,又具有计算过程,可以很细节的了解整个模型的架构,损失函数,参数如何学习、学到参数后如何预测。
英文原文:目录为https://createmomo.github.io/2019/11/13/Table-of-Contents/,这个系列为:CRF Layer on the Top of BiLSTM
既然是条件随机场,求的是一个条件概率,也就是在给定一个序列X的条件下,标注序列为y的概率,即: ,在实际的任务中, 是一句话,“小明在中国长大。”, 是对应的标注序列。很自然的就会想这个概率应该如何定义呢?那就是,给每个序列一个score,这个条件概率就是真正的序列的得分除以所有可能的序列的得分。比如,抛一枚硬币,一共有两种可能性,正或反,并且这两种可能性是独立的,那么,发生正面的概率就是 。同理,条件随机场也是这个思想。
下一步就是如何来定义这个分值了,从结果看,条件概率是一个[0, 1]的值,为了保证是正值,给每种序列的score取了个指数。借鉴HMM中的发射矩阵和转移矩阵,每种序列的分值也应该有两部分组成,即由转移矩阵和发射矩阵来组成。
条件概率与损失函数的关系,我们想要条件概率的值越大越好,但是损失函数是越小越好,所以就先取了个log,再取了个负号,log函数是单调递增的,相对大小没有影响。使得损失函数在训练的过程中最小化。
假设每条可能的路径都有一个分值
,真实路径的分值在所有可能路径的分值总和的占比:
在训练时,我们希望这个值越大越好。其实这个公式就是CRF的定义P(y|X),分母就是归一化因子
。
但是如何来定义
呢,我们用指数的形式来定义,
来保证是一个正数。一个路径发生的得分与什么有关系呢?与两部分有关,一个发射矩阵,另一个是转移矩阵,你看上面一节中CRF的定义中也是有两部分组成了。发射矩阵是由Bi-LSTM的输出,因为经过softmax之后转化成了num_labels维度了。而转移矩阵一开始是初始化的,然后不断更新,就是我们学习的参数。
为了方便处理,取了log,并加了一个负号。目的是为了在训练的过程中,可以最小化损失。

在Tensorflow中红框是用tf.contrib.crf.crf_sequence_score计算的,蓝框中的值是用tf.contrib.crf.crf_log_norm来计算的。
接下来的问题是蓝框中的值是如何计算的?一个很自然的想法是既然的求所有路径的分值的和,那么我们把所有的路径枚举出来就好了。是可以这样,但是时间复杂度太高了。如label的个数是 ,序列的长度是 的话,一共有 种可能,这是指数级别的。所以我们用动态规划(Dynamic Planning)的思想来计算。

->
->
的路径都放到alpha0和alpha1中了。
寻找最佳路径是从最后面一个往前找的。最后一个单词
的状态为
的时候的分值为0.9比状态
的分数0.8要高,所以首先确定最后一个状态是
,接下来就会问,
是什么状态时,转移到
为
的 分值最高。因为
也可能是
或
。在alpha1中发现上一个分别为(1,0),表示上一个状态转移分别为
->
和
->
,所以确实
的最优状态为
。
所以
->
为
->
。
下一步就再问,
的什么状态转化为
的
状态的分值最大?发现是(1,1)代表是
的状态。
所以:
到
的路径为
->
。
**alpha0中存的是每个单词不同状态的分值,来确定当前单词的最优状态。而alpha1中存放的是从上一个单词转化为当前单词的最优路径,是用来确定上一个单词的最优状态。**以此类推,从后往前找到一条最优路径。
3. 模型实现
3.1 tensorflow实现
Tensorflow 1中的crf实现:
tensorflow中crf模块函数解析
3.2 pytorch实现
-
pytorch实现计算score:
https://blog.csdn.net/cuihuijun1hao/article/details/79405740 -
crf实现讲解:知乎:
https://gist.github.com/koyo922/9300e5afbec83cbb63ad104d6a224cf4 -
Bert-based Named Entity Recognization
https://github.com/lemonhu/NER-BERT-pytorch -
pytorch官网 基本bi-lstm-crf实现
https://pytorch.org/tutorials/beginner/nlp/advanced_tutorial.html -
pytorch官网crf优化版
https://github.com/mali19064/LSTM-CRF-pytorch-faster -
torch-crf
https://github.com/kmkurn/pytorch-crf -
allennlp实现:
https://github.com/allenai/allennlp/tree/master/tutorials
