概述
对于序列标注问题,目前BiLSTM-CRF模型是目前使用比较流行的方法。本文以Neural Architectures for Named Entity Recognition为例,讲解BiLSTM-CRF模型在命名实体识别任务上的应用,着重于CRF层的分析。
数据描述
假设数据集有两种实体类型:人物(Person)和机构(Organization)。同时假设采用BIO标注体系。因此会有五种实体标签:
- B-Person
- I-Person
- B-Organization
- I-Organization
- O
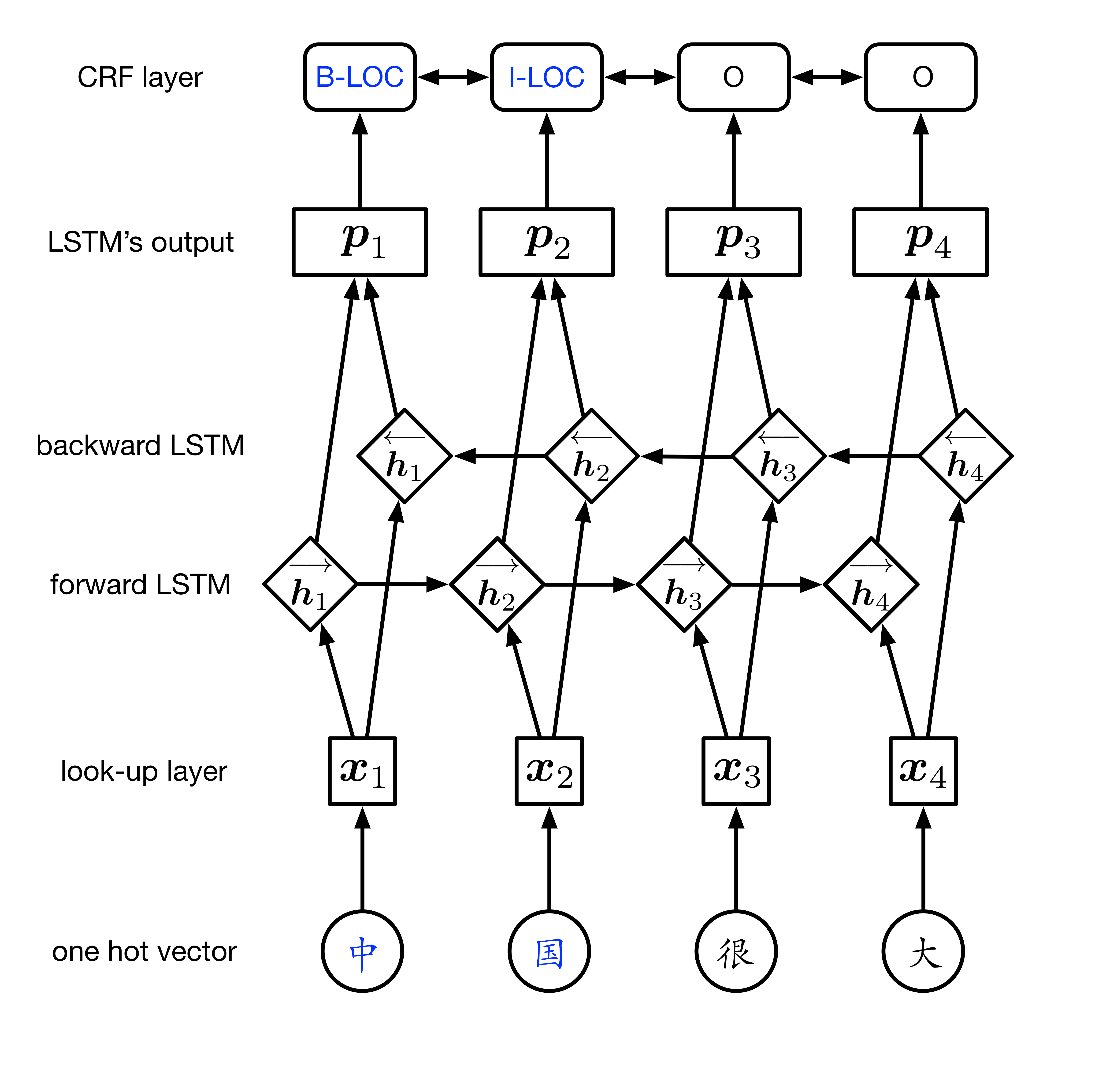
结构简介

第一层:表示层
将每个句子表示为词向量和字向量。
第二层:BiLSTM层
输入词向量和字向量到模型中的BiLSTM层,该层的输出是句子的每个词的所有标签的各自得分。
【注】此处的标签的各自得分充当的是CRF模型中的非归一化的发射概率。
在本例中就是五种标签的各自得分,如B-Person(1.5),I-Person(0.9),B-Organization(0.1),I-Organization(0.08),O(0.05)。
第三层:CRF层
该层使用BiLSTM层的输出——每个词的所有标签的各自得分,即(发射概率矩阵)以及转移概率矩阵,作为原始CRF模型的参数,最终获得标签序列的概率。
【注】
另一种结构图,表达含义相同。
CRF层详解
原理
BiLSTM层的输出是每个词的所有标签的各自得分,相当于每个词映射到标签的发射概率值。
设BiLSTM层的输出矩阵为 ,其中 代表词 映射到 的非归一化概率,类比于CRF模型中的发射概率矩阵。
CRF层中有一个转移概率矩阵 , 代表 转移到 的转移概率。
对于输入序列 对应的输出 序列 ,定义分数为

【注】每一个score对应一个完整的路径。
利用Softmax函数,为每一个正确的 序列 定义一个概率值( 代表所有的tag序列,包括不可能出现的)

在训练中,最大化似然概率 即可,利用对数似然

将损失函数定义为 ,利用梯度下降法进行学习。
对损失函数计算时, 的计算简单,但 计算复杂,因为需要计算每一条可能路径的分数。
采用该方法计算:对于到词 的路径,先把到词 的 算出,因为

因此计算每一步的路径分数和直接计算全局分数相同,但可以大大减少计算时间。
利用维特比算法进行预测。
作用
在BiLSTM-CRF模型中,若没有CRF层也未必不可,在结构简介中已经简单描述BiLSTM层的输出,即为句子的每个词的所有标签的各自得分。若没有CRF层,直接选择BiLSTM层中最大的得分输出标签类型即可。
那么CRF层作用是什么?即如下:
- 句子的开始单词的标签类型应该是
B或O,而不是I - 限制一些格式。如
B-Person I-Person是合理的,B-Person I-Organization是不合理的
【采用CRF层的原因】
- LSTM考虑的是输入序列X的上下文信息。CRF还可以考虑tag之间的依赖关系信息。
【参考资料】