CRF层说明
如果没有CRF层
您可能已经发现,即使没有CRF层,如下图所示,换句话说,我们依然可以训练BiLSTM命名实体识别模型。
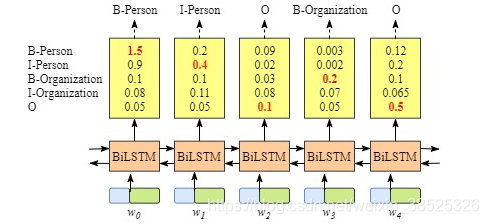
因为BiLSTM输出的每一个单词都是数据标签。对于每个单词我们都可以选择得分最高的标签。
举个例子,对于Wo,"B-Person"拥有最高的Score,因此我们可以选择“B-Person”作为其最佳预测标签。同样的,我们对于W1可以选择由此I-Person,对于W2选择“O”,类推W3,W4。
虽然在这个例子中我们可以为句子 x 获得正确的标签,但它并不总是那样,请再次尝试下图中的示例。
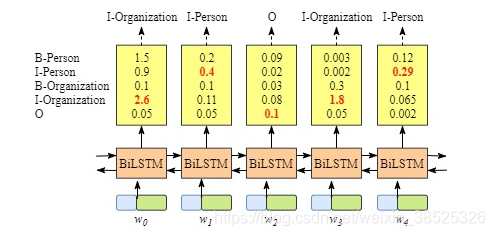
显然,这次输出无效,“I-Organization I-Person”和“B-Organization I-Person”。
CRF层可以从训练数据中学习约束
CRF层可以为最终预测标签添加一些约束以确保它们有效。在训练过程中,CRF层可以自动从训练数据集中学习这些约束。
约束可能是以下几种:
- 句子中第一个单词的标签应以“B-”或“O”开头,而不是“I-”
- B-label1 I-label2 I-label3 I- …“,在此模式中,label1,label2,label3 …应该是相同的命名实体标签。例如,“B-Person I-Person”有效,但“B-Person I-Organization”无效。
- “O I-label”无效。一个命名实体的第一个标签应以“B-”而非“I-”开头,换句话说,有效模式应为“O B-label”
- …
利用这些有用的约束,无效预测标签序列的数量将显着减少。
NEXT
在下一节中,我将分析CRF损失函数,以解释CRF层如何或为何可以从训练数据集中学习上述约束。
有人看继续写