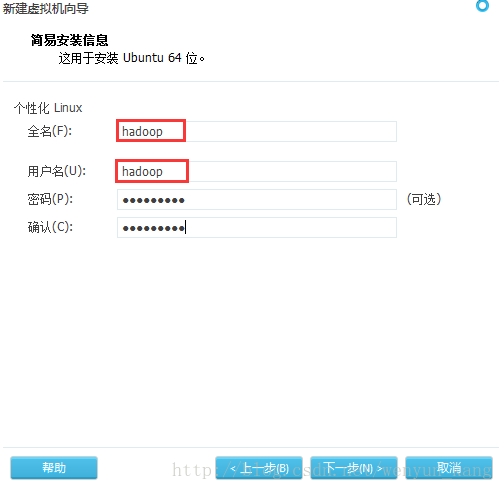
强调!!!
用户名称要相同,否则可能出现稀奇古怪的错误!!!(我就因为这个问题,在后面快装完的时候不得不从头再来)
原因:Hadoop要求所有机器上Hadoop的部署目录结构要求相同(因为在启动时按与主节点相同的目录启动其它任务节点),并且都有一个相同的用户名账户。参考各种文档上说的是所有机器都建立一个hadoop用户,使用这个账户来实现无密码认证。

我这里是在虚拟机上新建的系统,即装系统的时候将每个系统的下面这个界面的用户名填成一样的
一、开发环境
硬件环境:ubuntu-16.04.3 服务器3台(一台 master 结点,两台 slave 结点),在虚拟机中搭建
软件环境:jdk1.8.0_144,hadoop-2.8.1
jdk下载(下载对应版本以“.tar.gz”结尾的文件)

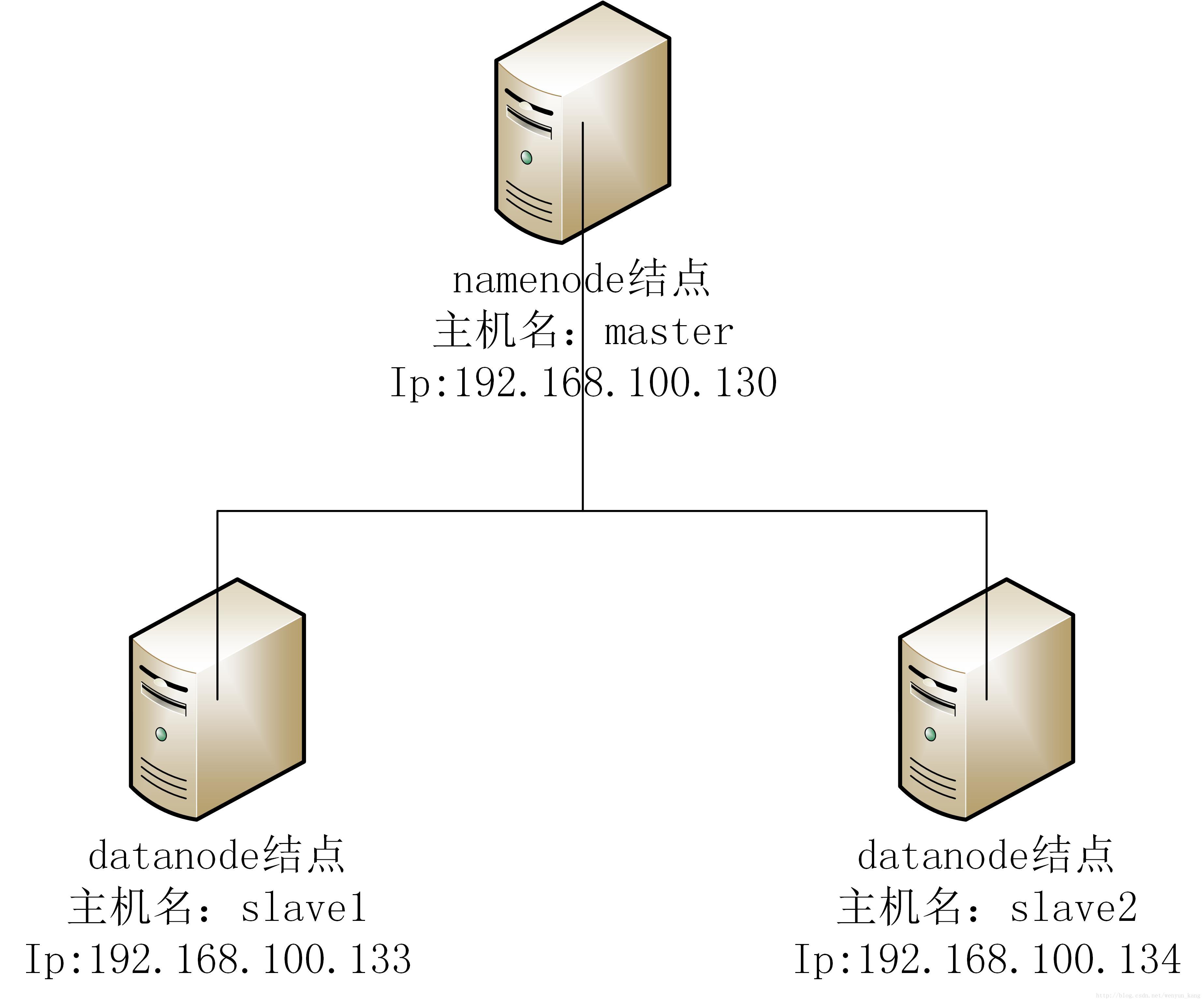
二、集群拓扑图
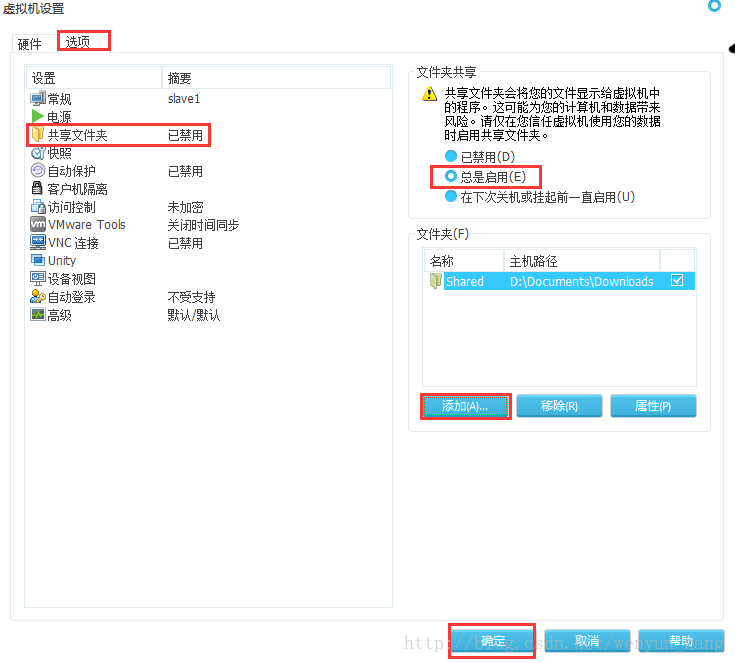
三、与本地Win7系统共享本地文件
ps:省去在虚拟机中下载文件,方便很多
1、虚拟机设置
虚拟机菜单栏 -> 虚拟机 -> 设置 -> 选项 -> 共享文件夹 -> 总是启用 -> 添加(我将添加的共享目录命名为Shared) ->确定
2、VMware Tools安装
(1)虚拟机菜单栏 -> 虚拟机 -> 安装VMware Tools
(2)等一会虚拟机会自己打开VMware Tools文件夹
(3)在该目录下,右键打开命令行,将压缩文件拷贝到桌面上,再到桌面上将其解压缩
cp VMwareTools-10.1.6-5214329.tar.gz /home/hadoop/Desktop/
cd /home/hadoop/Desktop/
tar -xzvf VMwareTools-10.1.6-5214329.tar.gz
(4)成功之后以管理员root身份执行解压缩之后文件目录里的vmware-install.pl文件即可进行安装
sudo vmware-tools-distrib/vmware-install.pl
(5)一路回车
酱紫就装好了

(6)共享文件在 /mnt/hgfs/Shared 文件夹下
ps:Shared是刚添加共享目录时自己起的名字
3、将下载好的软件包放到共享文件夹下
四、JDK的安装与配置
1、解压缩
(1)把压缩包拷贝到你想要安装的位置,我要装在 /usr/local 目录下
sudo cp jdk-8u144-linux-x64.tar.gz /usr/local
(2)进到对应目录下解压缩
cd /usr/local
sudo tar -zxvf jdk-8u144-linux-x64.tar.gz
2、配置环境变量
(1)修改配置文件
sudo vi /etc/profile在末尾添加如下配置(Linux命令:G -> o(字母小o) - > 输入以下内容)
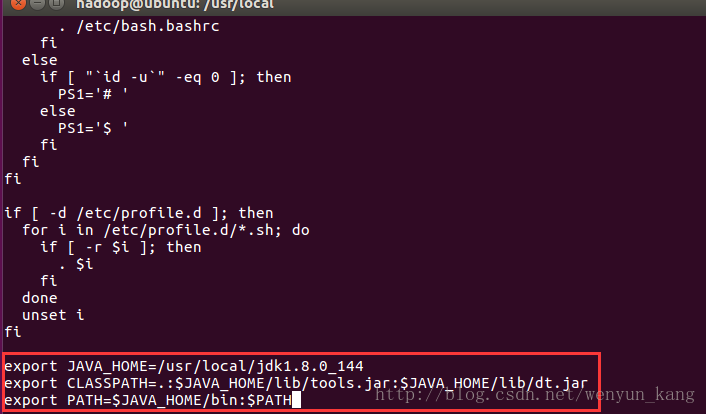
export JAVA_HOME=/usr/local/jdk1.8.0_144
export CLASSPATH=.:$JAVA_HOME/lib/tools.jar:$JAVA_HOME/lib/dt.jar
export PATH=$JAVA_HOME/bin:$PATH(Linux命令:Esc键 - > 输入“:wq”退出)
(2)重新加载/etc/profile,使配置生效
source /etc/profile(3)检查是否配置成功
echo $PATH
java -version
五、HOST文件配置
修改集群中每台服务器的 hosts 文件,配置主机名和 ip 地址的映射
vi /etc/hosts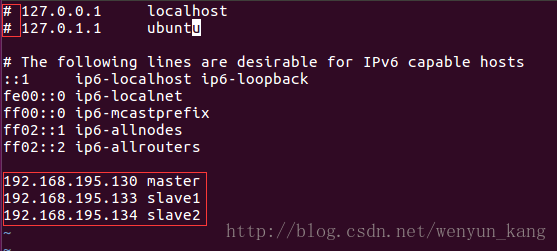
六、SSH的安装与配置
1、软件安装
(1)首先更新源(要确定系统可以联网,可以先打开浏览器访问以下百度主页,如果没连上网,可以试试到Win7系统上 “右键计算机 -> 管理 -> 服务和应用程序 -> 服务 -> 找到VMware相关的所有服务 -> 右键 -> 启动”)
sudo apt-get update(2)安装 openssh
- 服务端安装
sudo apt-get install openssh-server
- 客户端安装
sudo apt-get install openssh-client
ps:如何区分该装服务端还是客户端?
如果 slave1 系统想要登录 slave2 系统,那么 slave1 装客户端, slave2 装服务端,如果想要互相都能登录,就服务端和客户端都装
(3)测试是否可以登录
ssh -l hadoop 192.168.195.133(ssh -l [用户名] [远程ip])
( ip 可以用 ifconfig 命令查看)
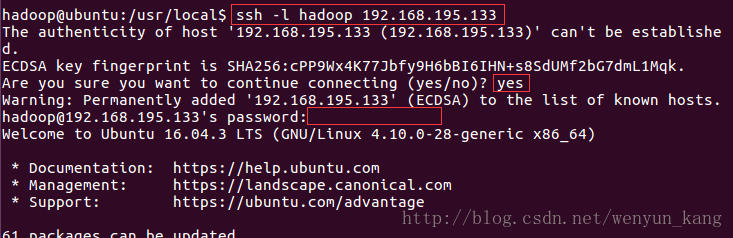
到现在,我们已经可以通过密码登录了
2、配置免密码登录
原理是验证公钥而不验证密码
(1)配置本机无密码登录
三台服务器均做如下设置
1)进入到宿主目录下,生成本机秘钥同时设置免密登录,注意,这里不能使用 root 用户生成秘钥,而是要使用你想要设置免密登录的用户
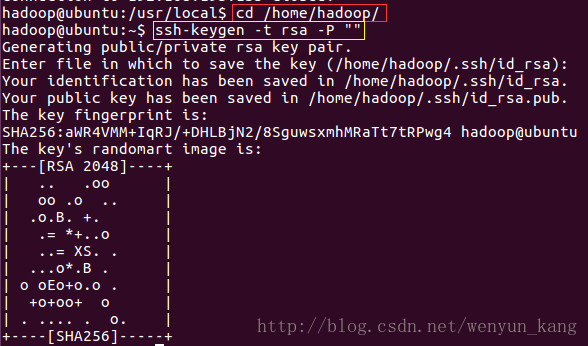
cd /home/hadoop/
ssh-keygen -t rsa -P ""一路回车
2)将公钥追加到 authorized_keys 文件中
cat .ssh/id_rsa.pub >> .ssh/authorized_keys赋予 authorized_keys 文件权限
chmod 600 .ssh/authorized_keys
3)验证是否成功
ssh localhost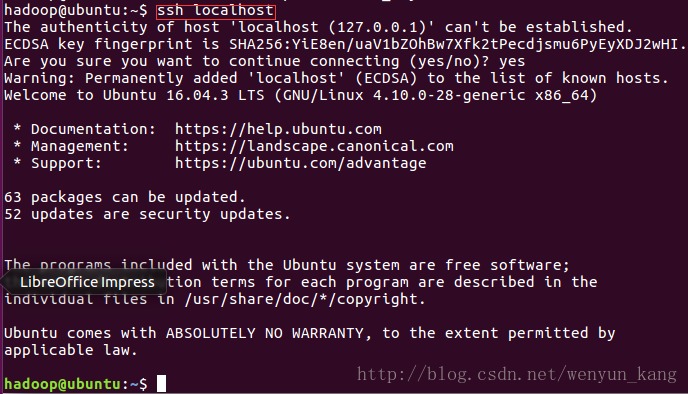
(2)配置 master 无密码登录 slave1 服务器
以下操作均在 slave1 服务器上操作
1)复制 master 的公钥到 slave1 上
scp hadoop@192.168.195.130:/home/hadoop/.ssh/id_rsa.pub /home/hadoop(scp master_userName@master_ip:master_file slave1 _folder)

2)将 master 公钥追加到 slave1 的 authorized_keys 文件中,删除 master 公钥文件
cat /home/hadoop/id_rsa.pub >> .ssh/authorized_keys
rm /home/hadoop/id_rsa.pub
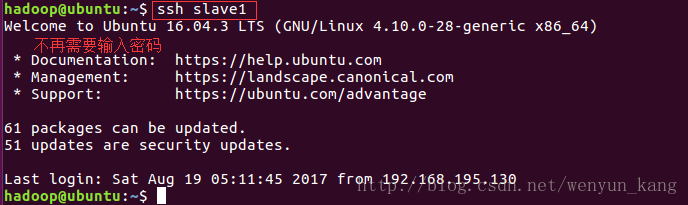
3)验证是否成功(在master服务器上操作)
ssh slave1(ssh ip 在 /etc/hosts 文件中我们已经将 ip 和主机名做了映射,所以可以直接用主机名代替 ip)
(3)参照上一步,完成以下配置
1)master -> slave2
2)slave1 -> master
3)slave2 -> master
4)slave1 -> slave2
5)slave2 -> slave1
七、Hadoop完全分布式环境的安装与配置
除特别说明外,以下操作均在 master 服务器上操作
1、创建文件目录
为了便于管理,给master的hdfs的NameNode、DataNode及临时文件,在根目录下创建目录:
/data/hdfs/name
/data/hdfs/data
/data/hdfs/tmp
sudo mkdir /data
sudo mkdir /data/hdfs
sudo mkdir /data/hdfs/name
sudo mkdir /data/hdfs/data
sudo mkdir /data/hdfs/tmp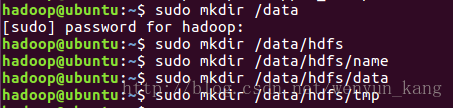
修正分割线———————————–
(ps:对之前看了这篇博客,照着搭建完出现问题的小伙伴表示万分抱歉,我也是在运行实例的时候找了好久才弄明白这个地方的错误的,求原谅T_T)
这里创建完各文件夹之后,记得要把文件夹的所有者和所属组改成 hadoop 用户,否则后面 hadoop 用户没有权限写入,会出错,我遇到的错误是 second 线程启动不起来,因为没有权限创建它所需要的文件夹及写入文件
sudo chown hadoop /data
sudo chown hadoop /data/hdfs
sudo chown hadoop /data/hdfs/name
sudo chown hadoop /data/hdfs/data
sudo chown hadoop /data/hdfs/tmp修正分割线———————————–
分别在 slave1 和 slave2 服务器上执行以下命令
sudo scp -r hadoop@master:/data /2、解压缩
(1)将共享目录下的软件包拷贝到 /data 目录下
sudo cp /mnt/hgfs/Shared/hadoop-2.8.1.tar.gz /data到 /data 目录下解压文件
cd /data
sudo tar -zxvf hadoop-2.8.1.tar.gz将解压完的 hadoop-2.8.1 文件的所有者及所属组改为 hadoop 用户,并删除压缩包
sudo chown -R hadoop:hadoop /data/hadoop-2.8.1
sudo rm -rf hadoop-2.8.1.tar.gz3、配置hadoop环境
(1)修改配置文件
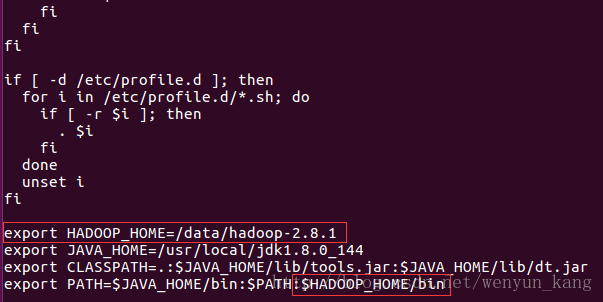
sudo vi /etc/profile在 JAVA_HOME 前面添加如下配置(Linux命令:G ->k(上移到 JAVA_HOME 那一行) -> o(字母小o) - > 输入以下内容)
export HADOOP_HOME=/data/hadoop-2.8.1修改 PATH 条目为
export PATH=$JAVA_HOME/bin:$PATH:$HADOOP_HOME/bin(Linux命令:Esc键 - > 输入“:wq”退出)
(2)重新加载 /etc/profile,使配置生效
source /etc/profile(3)检查是否配置成功
hadoop
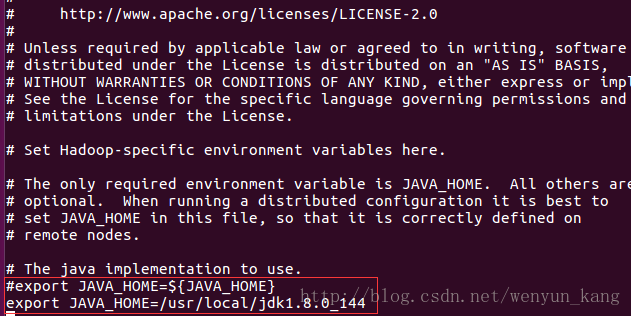
(4)修改 hadoop-env.sh 文件
hadoop 环境是基于 JVM 环境的,故需在 hadoop-env.sh 配置文件中指定 JDK 环境
sudo vi hadoop-2.8.1/etc/hadoop/hadoop-env.sh
找到 JAVA_HOME 修改
(Linux 命令:L -> j(下移两三行就能找到) -> I -> # -> Esc键 -> o (字母小o)-> 输入)
export JAVA_HOME=/usr/local/jdk1.8.0_144保存退出(Linux 命令:Esc键 -> :wq!)
(5)修改下列文件
在Linux系统桌面上新建以下文件,并修改相应内容(文件内容与上面的新建的 /data 文件夹有关)
1)core-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
<property>
<name>fs.default.name</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/data/hdfs/tmp</value>
</property>
</configuration>注意: hadoop.tmp.dir 的 value 填写对应前面创建的目录
2)hdfs-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/data/hdfs/name</value>
<final>true</final>
</property>
<property>
<name>dfs.blocksize</name>
<value>268435456</value>
</property>
<property>
<name>dfs.namenode.handler.count</name>
<value>100</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/data/hdfs/data</value>
<final>true</final>
</property>
</configuration>注意: dfs.namenode.name.dir 和 dfs.datanode.data.dir 的 value 填写对应前面创建的目录
3)mapred-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.map.memory.mb</name>
<value>1536</value>
</property>
<property>
<name>mapreduce.map.java.opts</name>
<value>-Xmx1024M</value>
</property>
<property>
<name>mapreduce.reduce.memory.mb</name>
<value>3072</value>
</property>
<property>
<name>mapreduce.reduce.java.opts</name>
<value>-Xmx2560M</value>
</property>
<property>
<name>mapreduce.task.io.sort.mb</name>
<value>512</value>
</property>
<property>
<name>mapreduce.task.io.sort.factor</name>
<value>100</value>
</property>
<property>
<name>mapreduce.reduce.shuffle.parallelcopies</name>
<value>50</value>
</property>
<property>
<name>mapred.healthChecker.script.path</name>
<value></value>
</property>
</configuration>4)yarn-site.xml
<?xml version="1.0"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>master:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:8031</value>
</property>
</configuration>(6)替换掉 hadoop-2.8.1 文件夹下的相应文件
cd hadoop-2.8.1/etc/hadoop/
sudo rm yarn-site.xml
sudo rm hdfs-site.xml
sudo rm core-site.xml
sudo mv /home/hadoop/Desktop/yarn-site.xml .
sudo mv /home/hadoop/Desktop/hdfs-site.xml .
sudo mv /home/hadoop/Desktop/core-site.xml .
sudo mv /home/hadoop/Desktop/mapred-site.xml .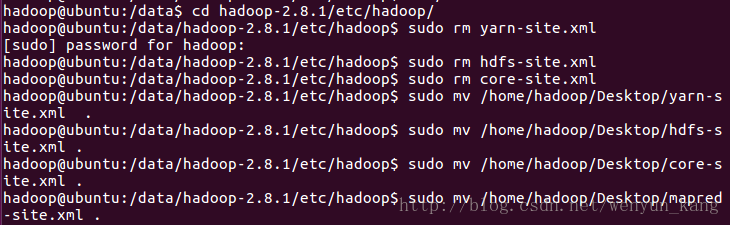
(7)修改 slaves 文件
sudo vi slaves为
slave1
slave2(Linux 命令:D -> i -> 输入即可)

保存退出(Linux 命令:Esc键 -> :wq!)
(8)复制到 slave1 和 slave2 服务器上
分别在 slave1 和 slave2 服务器上执行以下语句
sudo scp -r hadoop@master:/data/hadoop-2.8.1 /data(9)删除 slave1 和 slave2 服务器上的 slaves 文件,并更改 /data 文件夹的所有者及所属组为 hadoop 用户,分别在 slave1 和 slave2 服务器上执行以下语句
sudo rm slaves
sudo chown -R hadoop:hadoop /data
4、运行Hadoop
除特殊说明外,只在 master 上执行
(1)格式化NameNode
hadoop namenode -format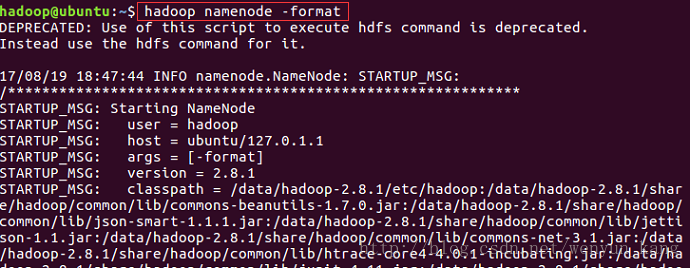
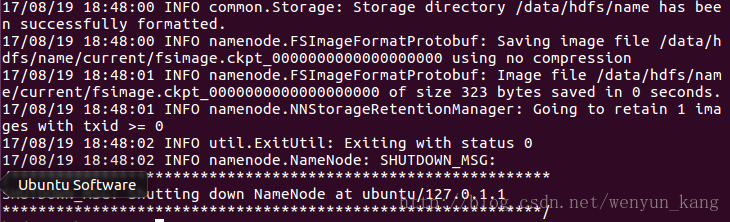
注意:这一步可能会出现问题,最好从头到尾看一遍以确定格式化成功
(2)启动HDFS文件管理系统
cd /data/hadoop-2.8.1/这边要保证三台服务器上的hadoop-2.8.1文件夹的所有者都是hadoop用户
(sudo chown hadoop /data/hadoop-2.8.1)
sbin/start-all.sh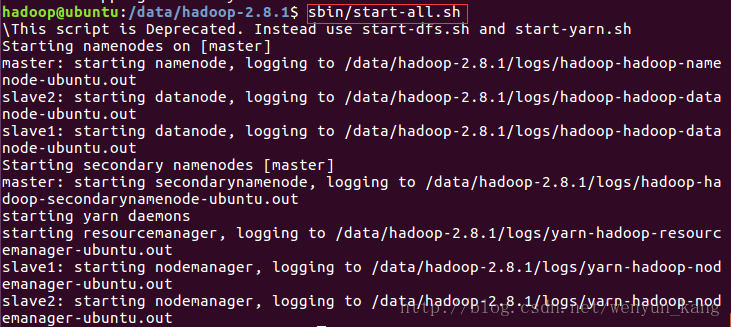
可以照着 log 的保存路径查看一下 log 日志,尤其是,如果出现了什么错误,日志里会写的很清楚
(3)查看启动进程
在 master 上执行
jpsmaster服务器:
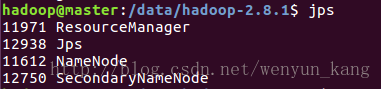
ps:SecondaryNameNode 线程没启动起来的话有可能是因为 hadoop 用户没有对 /data/hdfs 及其下的子文件夹的写权限
slave1服务器:

slave2服务器:
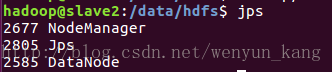
缺任何一个都是有问题的
5、测试Hadoop
(1)查看集群状态
hadoop dfsadmin -report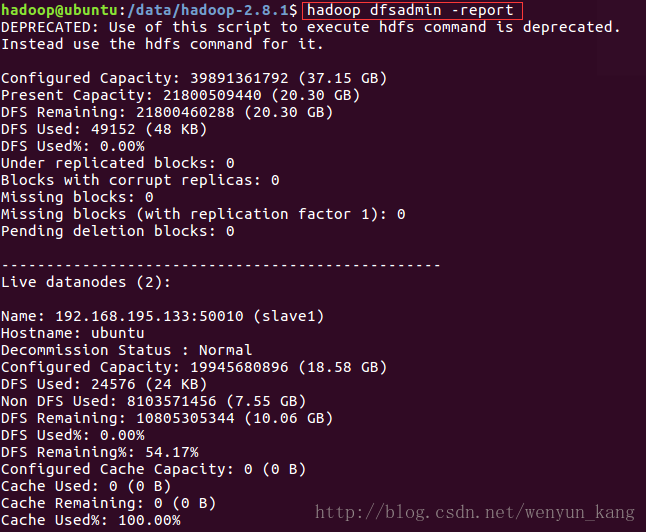
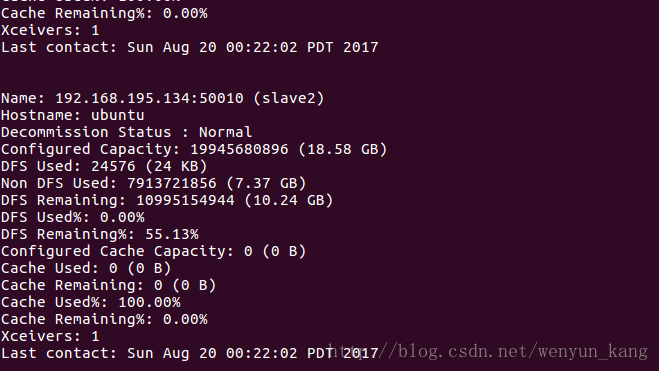
(2)测试集群
在master上创建个新文件夹
hdfs dfs -mkdir /user
分别在三台服务器上查看刚新建的文件夹是否成功
hdfs dfs -ls /master服务器:

slave1服务器:

slave2服务器:

(3)测试yarn
ip 是master 服务器的 ip ,端口是在前面修改的文件中指定的
http://192.168.195.130:18088/cluster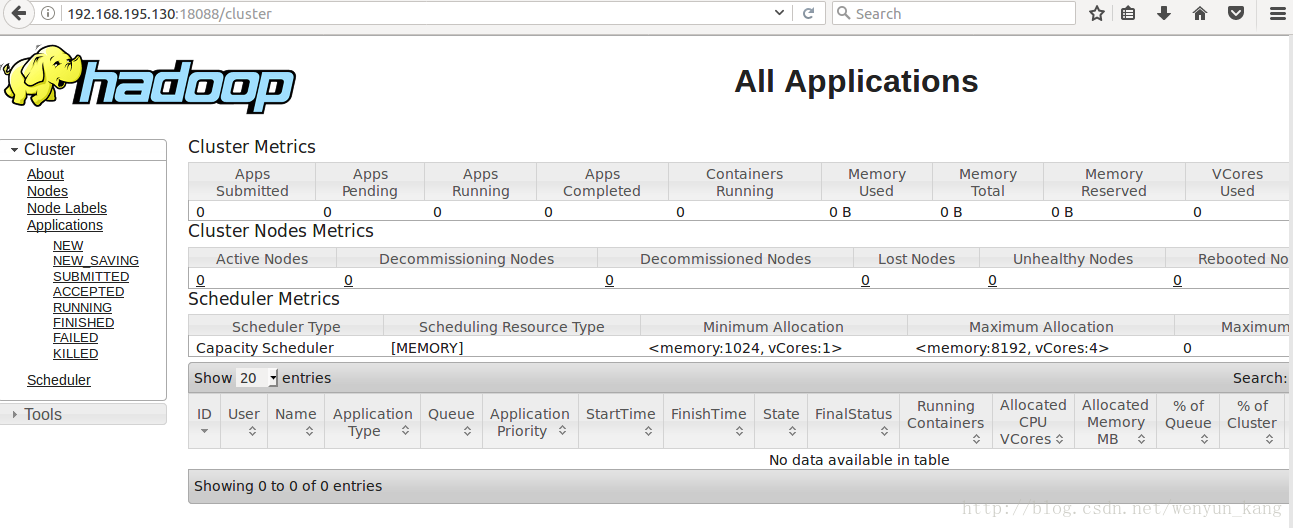
(4)测试 mapreduce
Hadoop 安装包里有提供现成的 mapreduce 例子,在 Hadoop 的share/hadoop/mapreduce 目录下。运行例子:
bin/hadoop jar /data/hadoop-2.8.1/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.8.1.jar pi 5 10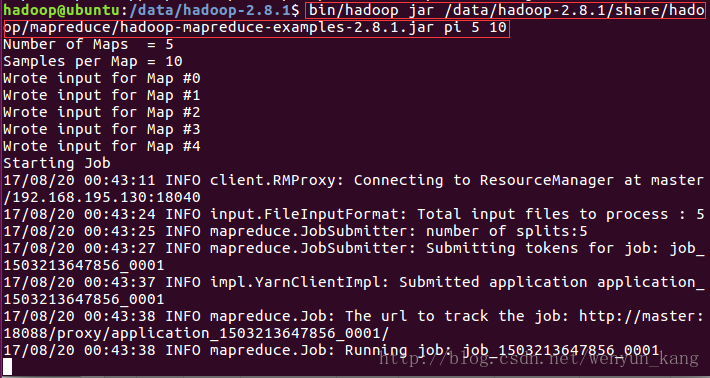
截图中是还没运行完毕的代码,如果电脑内存不是很大的话,他会在这里卡很久,我的电脑是8G,虚拟机分配的内存是1.5G(分配2G的话电脑就会卡到动不了。。。)

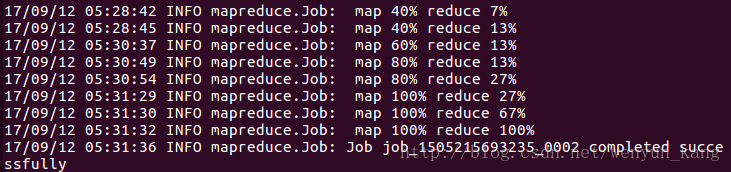
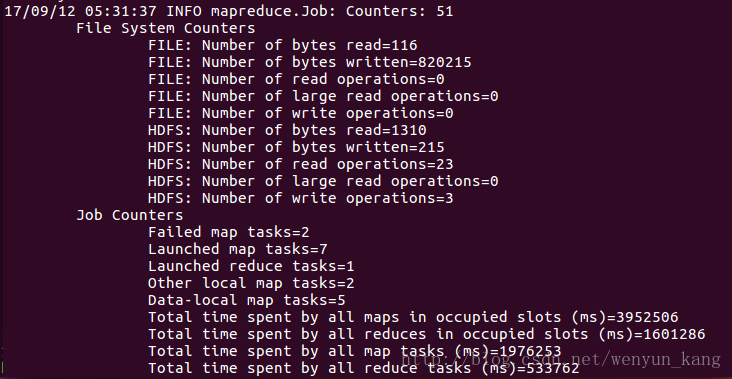
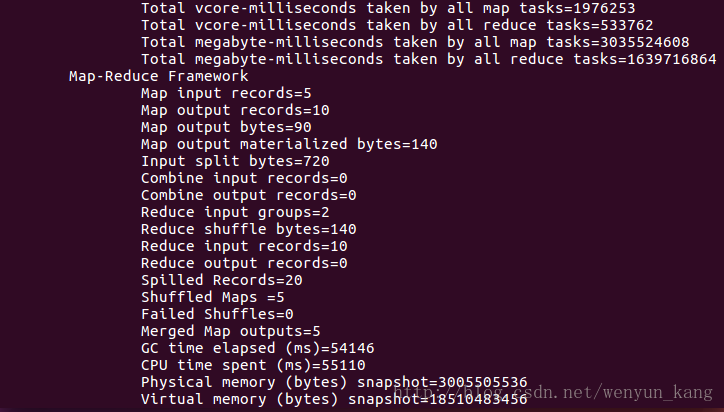
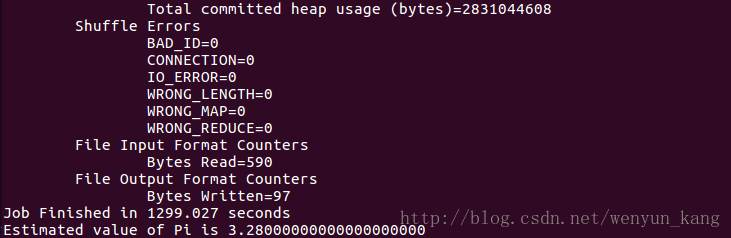
运行了n遍都失败之后,决定最后运行一遍,然后扔那运行我就干别的去了。。。一个多小时之后回来发现。。。竟然成功了,失败的原因是,电脑性能跟不上
然后刷新刚才的网页
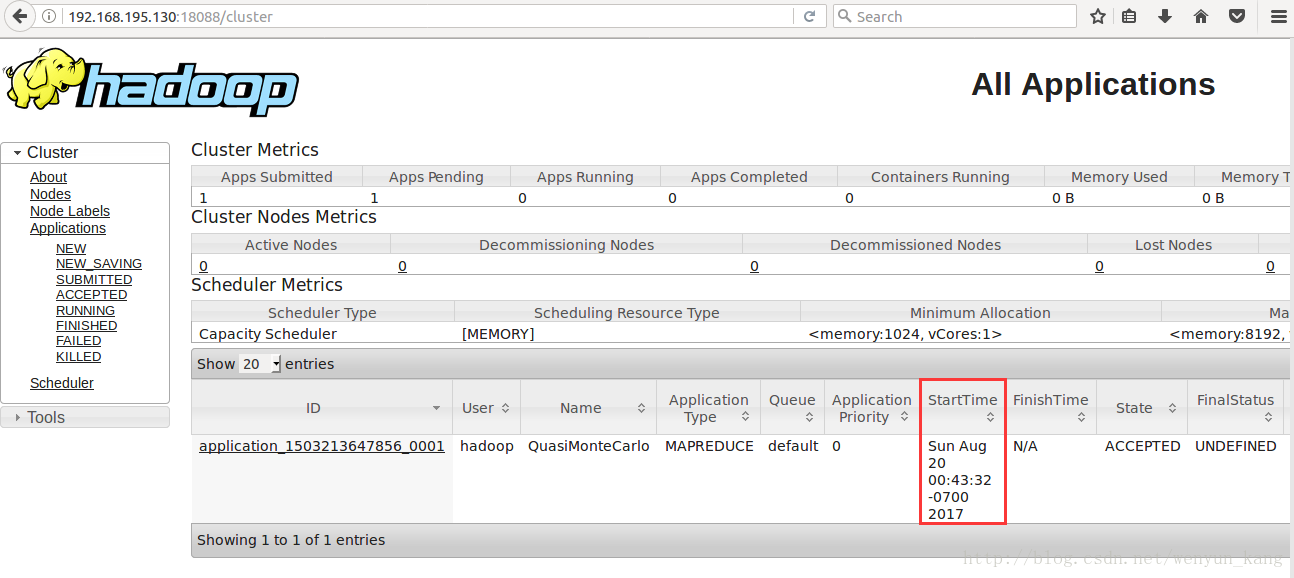
(5)查看HDFS
http://192.168.195.130:50070/dfshealth.html#tab-overview
唔哈哈哈哈哈~~~好啦,大功告成了,差不多花了一周的时间,踩了无数个坑才完成,激动!!!
日后可能遇到的问题
1、namenode没有启动,每次开机都得重新格式化一下namenode才可以
参考答案:
http://blog.csdn.net/bychjzh/article/details/7830508
2、hadoop运行到mapreduce.job: Running job后停止运行
参考答案:
http://blog.csdn.net/zhangchaokun/article/details/49105037
