文章目录
概述
- Hadoop完全分布式配置-具体步骤如下
默认前提:
1.在Windows平台下安装Vmware平台(默认已经安装)
2.在Vmware平台上安装Linux操作系统(默认已经安装)
这里我已安装的是 Vmware16 和 CentOS7.
1.准备Linux
- 网络设置NAT模式
编辑——>虚拟网络编辑器——>更改设置(需要管理员权限)

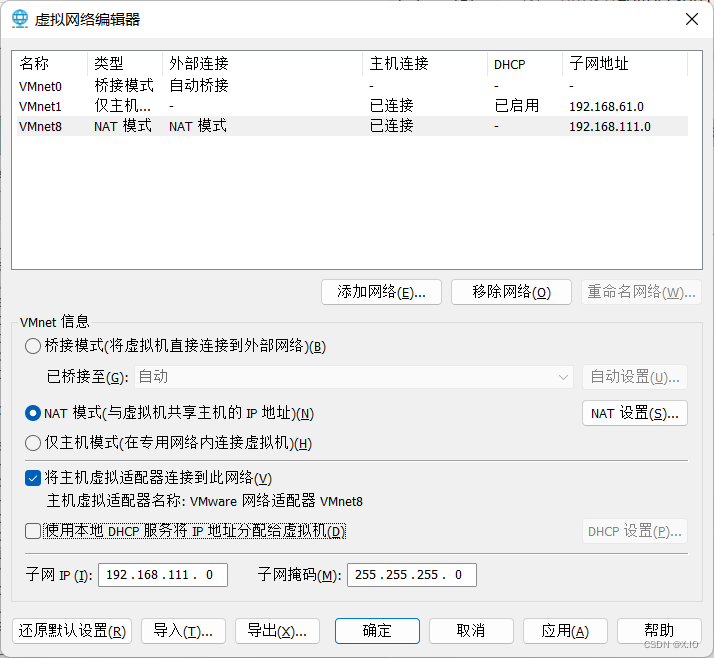
·桥接:选择桥接模式的话虚拟机和宿主机在网络上就是平级的关系,相当于连接在同一交换机上。
·NAT:NAT模式就是虚拟机要联网得先通过宿主机才能和外面进行通信。
·仅主机:虚拟机与宿主机直接连起来
如果是通过网线部署在不同的电脑上,应该选择桥接模式。
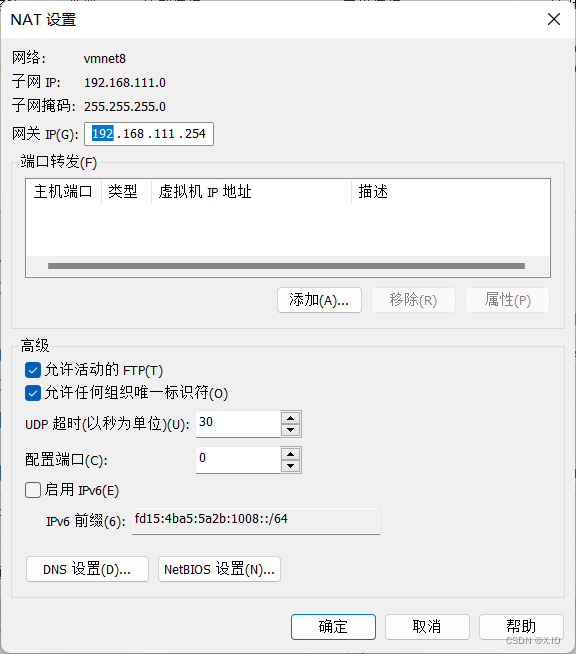
如果是选择NAT模式来用于设置本机局域网,则IP也要设置。
-
设置静态IP
·命令1:vi /etc/sysconfig/network-scripts/ifcfg-ens33 ·命令2:service network restart #重启网络,使上面的设置生效 ·命令3:ping www.baidu.com #可测试固定IP设置是否有效(1)执行命令1,修改配置文件。
首先,修改部分:BOOTPROTO=static 其次,添加部分:HDDR=刚刚复制的数字 IPADDR=192.168.111.131 GATEWAY=192.168.111.254 DNS1=8.8.8.8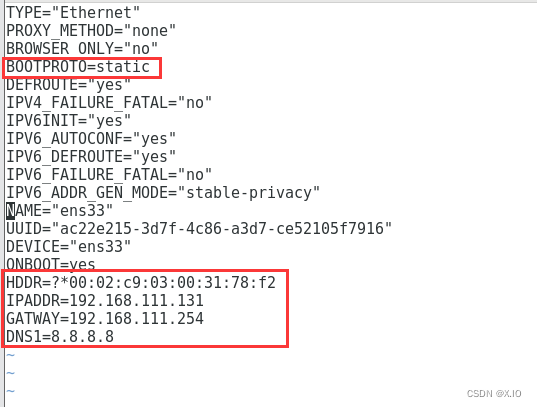
(2)执行命令2,重启网络,使设置生效

(3)执行命令3,测试固定IP设置是否有效

-
修改主机名字
·命令1:vim /etc/hostname 直接修改即可 重启系统reboot,使设置生效修改前:
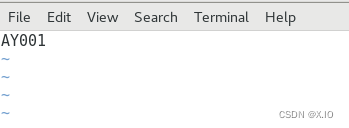
修改后: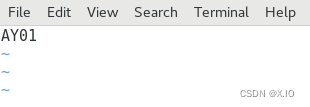
-
关闭防火墙
·永久性生效,重启后不会复原 开启:systemctl enable firewalld 关闭:systemctl disable firewalld ·即时生效,重启后复原 开启:systemctl start firewalld 关闭:systemctl stop firewalld ·查看防火墙运行状态:systemctl status firewalld永久性关闭防火墙,并reboot重启系统,然后用 systemctl status firewalld 查看防火墙的运行状态。
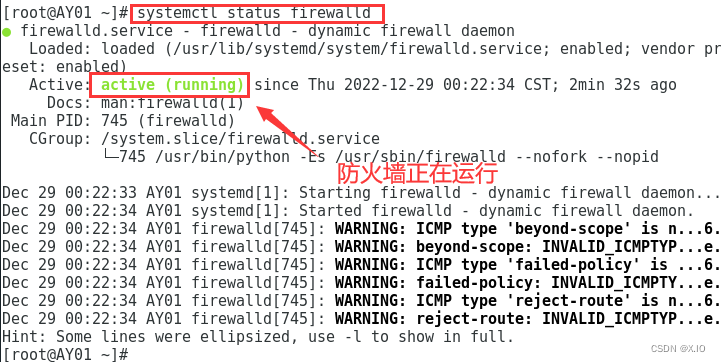
永久关闭并重启后:

2.安装JDK
默认已经在Windows上安装 Xshell 和 Xftp
下面我们将通过Xshell和Xftp进行操作
-
首先连接Xshell
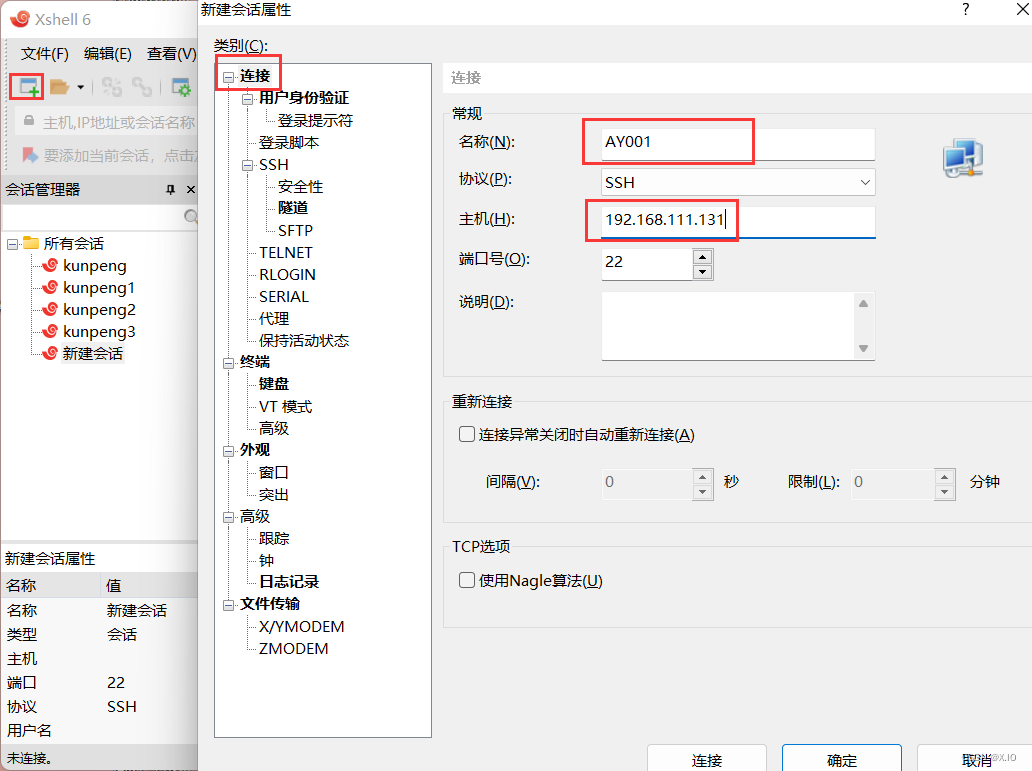
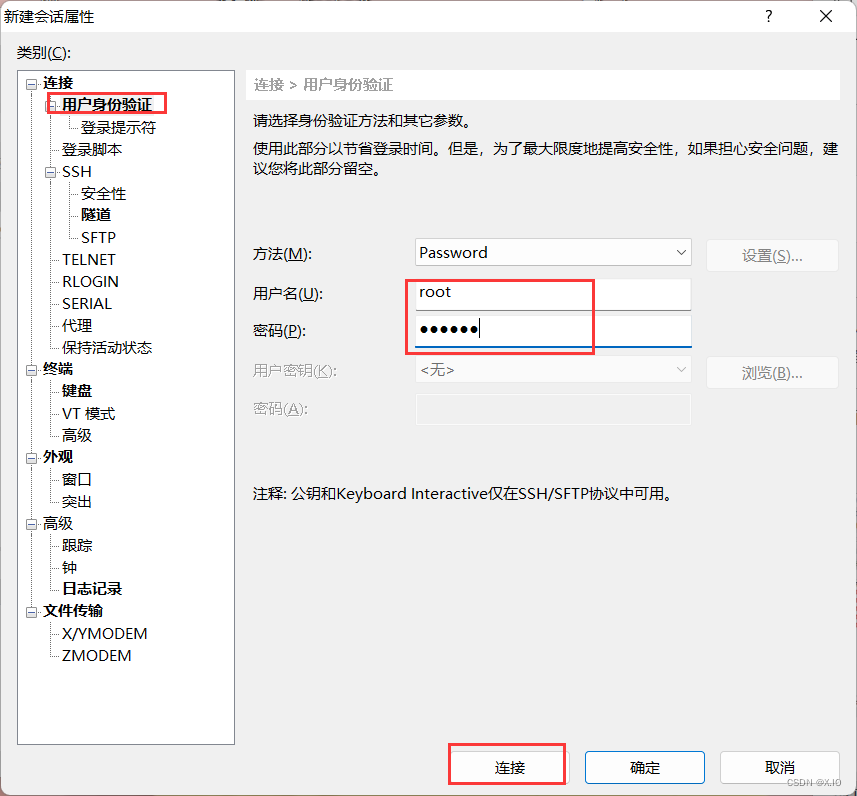
-
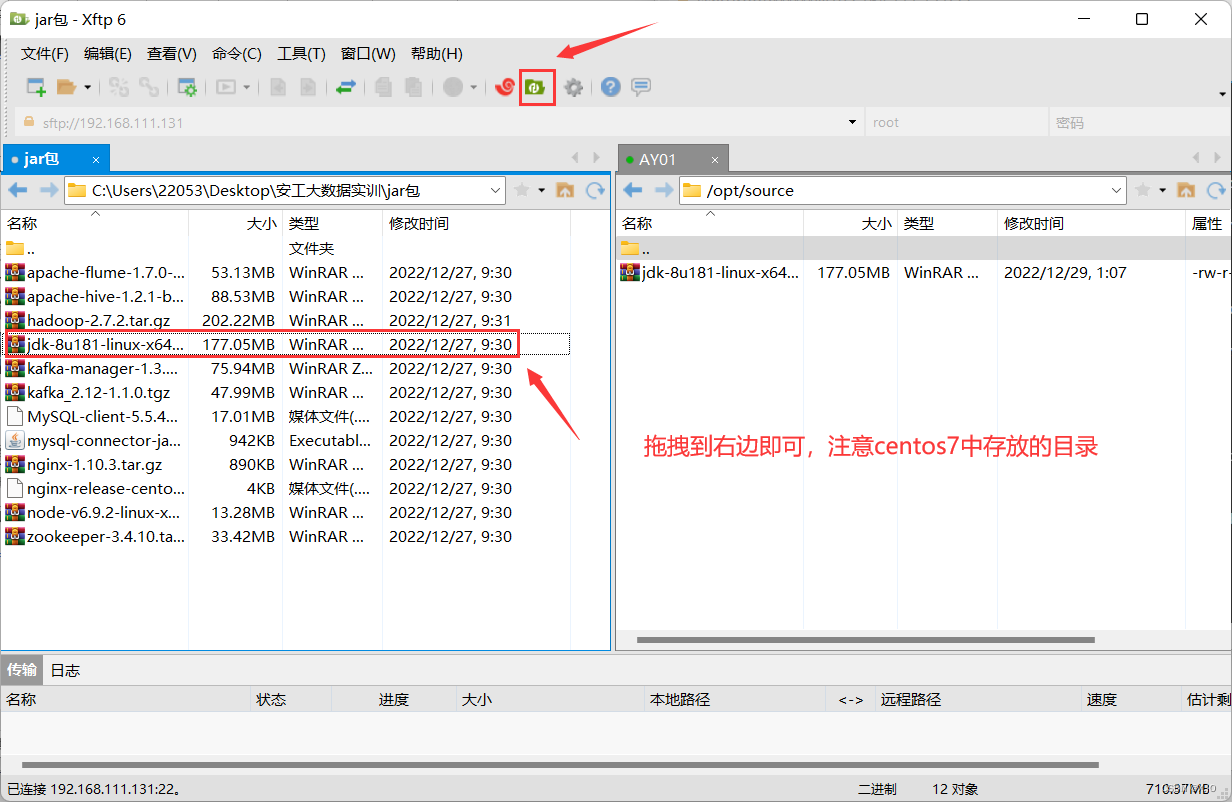
利用Xshell中的Xftp,把Windows中的 jdk 上传到 Linux 系统
准备工作:在/opt文件夹下创建两个文件夹 cd /opt mkdir module #module存放解压后文件 mkdir source #source存放原文件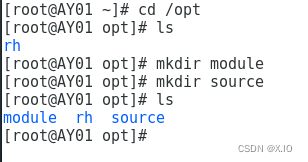
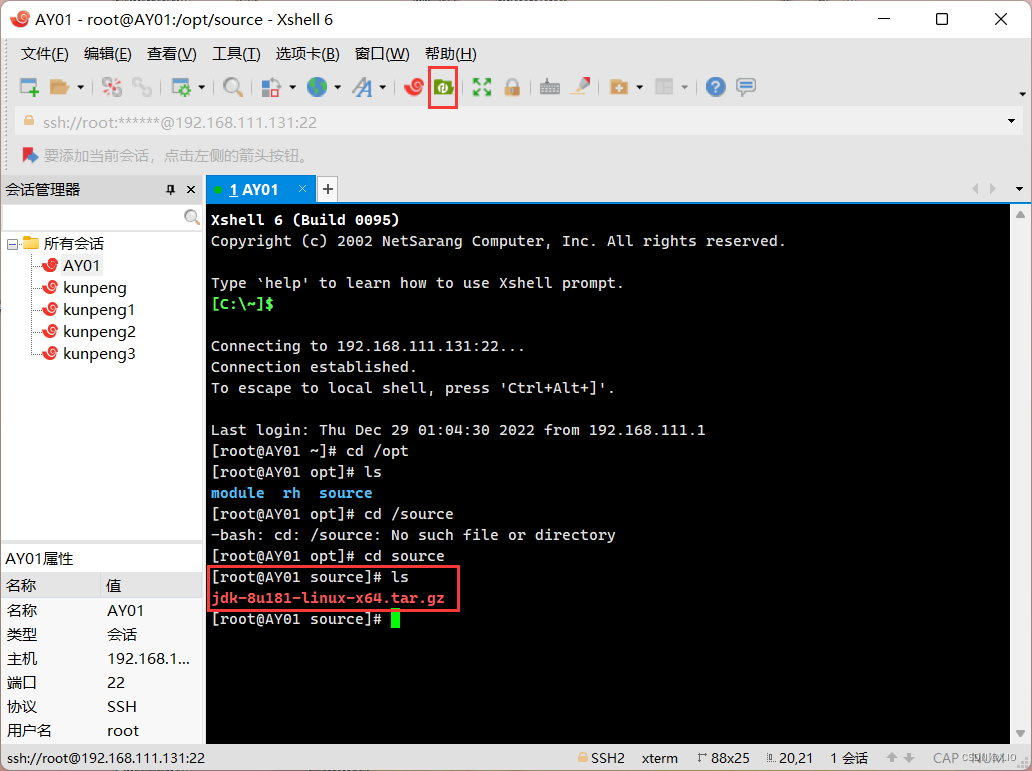
-
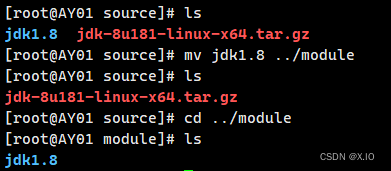
解压缩 jdk
·命令:tar -zxvf jdk-8u181-linux-x64.tar.gz ·修改文件夹的名称:mv jdk1.8.0_181 jdk1.8 ·移动到module文件夹中:mv jdk1.8 ../module解压后:

改名后:

移动后:
-
配置环境
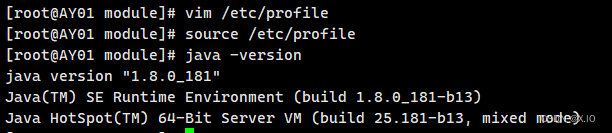
方法1:修改.bash_profile文件 ·vim ~/.bash_profile ·在.bash_profile文件末尾加入: export JAVA_HOME=/opt/module/jdk1.8 export PATH=$JAVA_HOME/BIN:$PATH ·然后执行以下命令,使环境变量配置立即生效 source ~/.bash_profile 方法2:修改/etc/profile文件 ·vim /etc/profile ·在profile文件末尾加入: export JAVA_HOME=/opt/module/jdk1.8 export PATH=$JAVA_HOME/bin:$PATH ·然后执行以下命令,使配置立即生效 source /etc/profile ·执行以下命令,查看java版本号: java -version·方法一:更为安全,它可以把使用这些环境变量的权限控制到用户级别,如果你需要给某个用户权限使用这些环境变量,你只需要修改其个人用户主目录下的.bash_profile文件就可以了。 ·方法二:更为方便,因为所有用户的shell都有权使用这些环境变量,如果你的计算机仅仅作为开发使用时推荐使用这种方法,否则可能会给系统带来安全性问题。这里我采用的是方法二:

3.克隆两台虚拟机
前面我们已经完成了 虚拟机AY01 的准备工作和 JDK的安装。
下面我们将对该虚拟机进行克隆。
右键——>管理——>克隆
然后进行克隆:

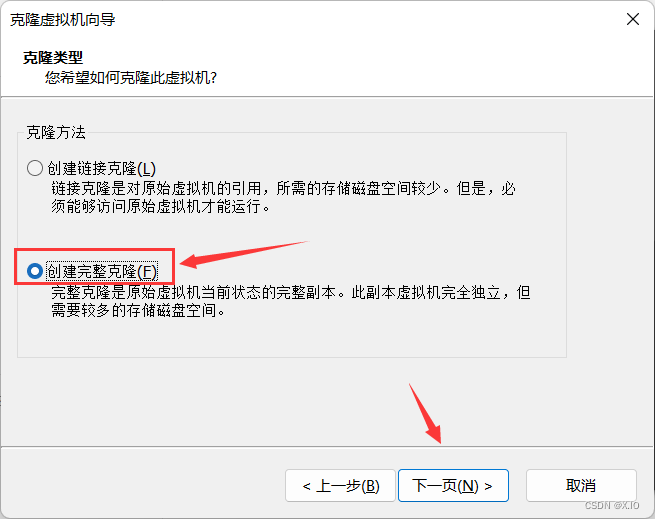
选择 “创建完整克隆”
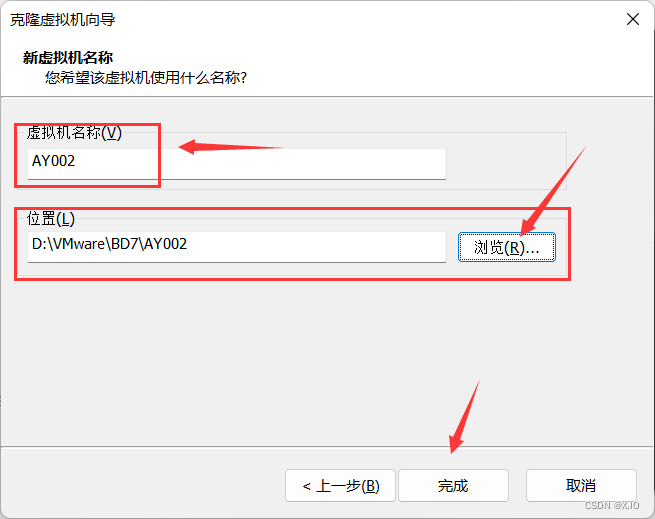
自行修改即可:

然后以同样的操作,完成第三台虚拟机的克隆即可。
克隆完成后,我们需要进行一些小操作:
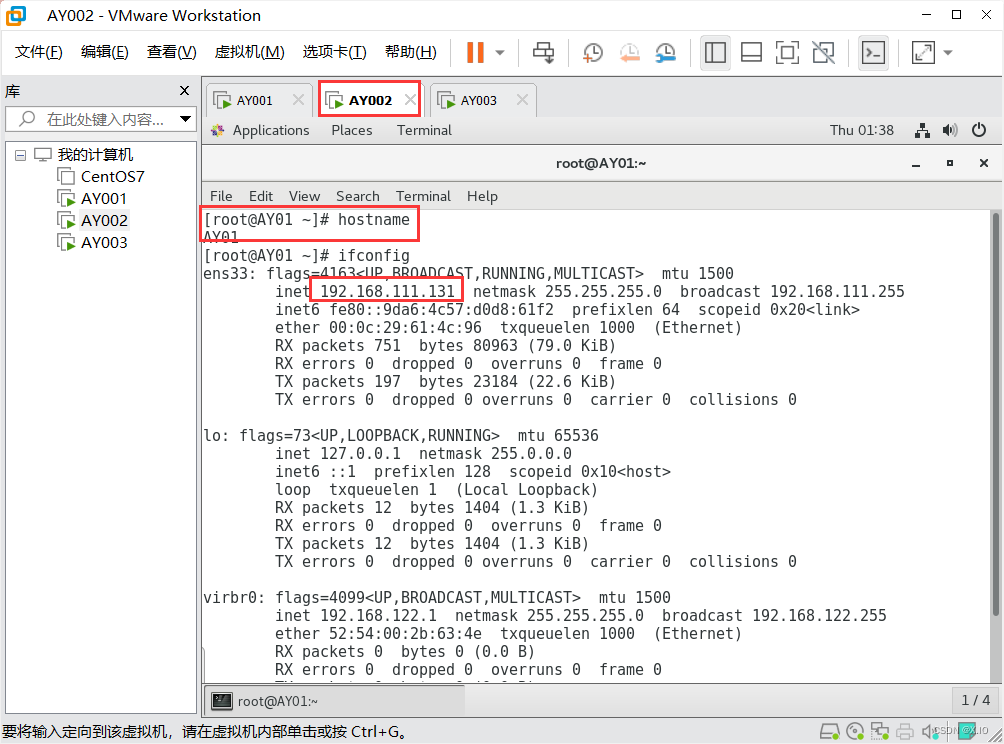
·修改 虚拟机AY002 和 虚拟机AY003 的 主机名 和 IP地址
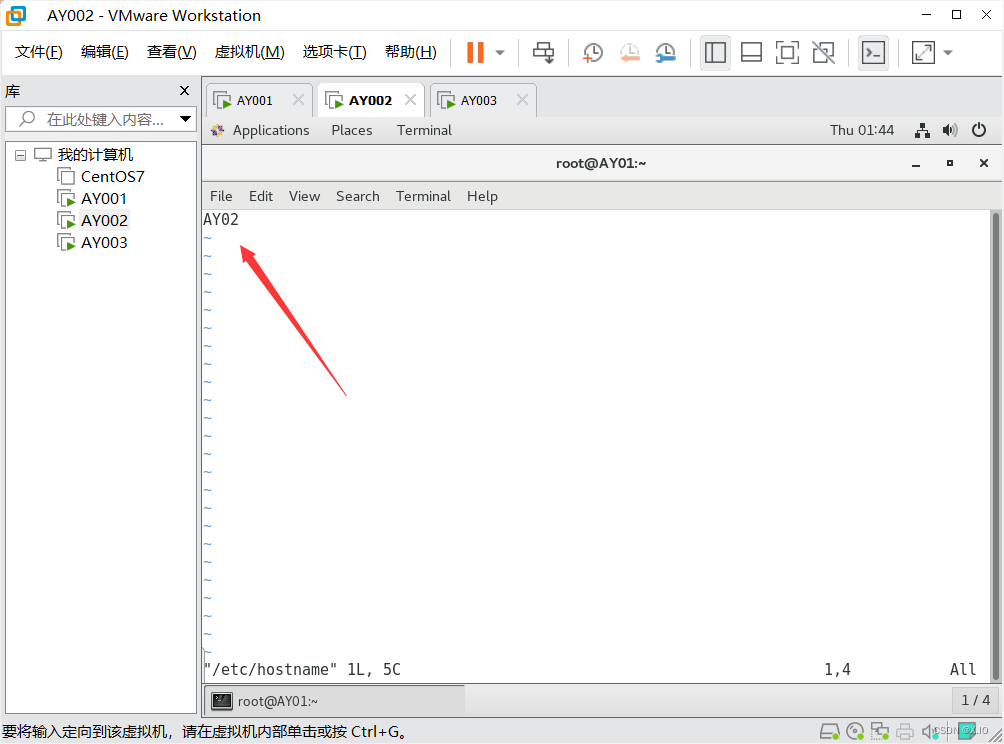
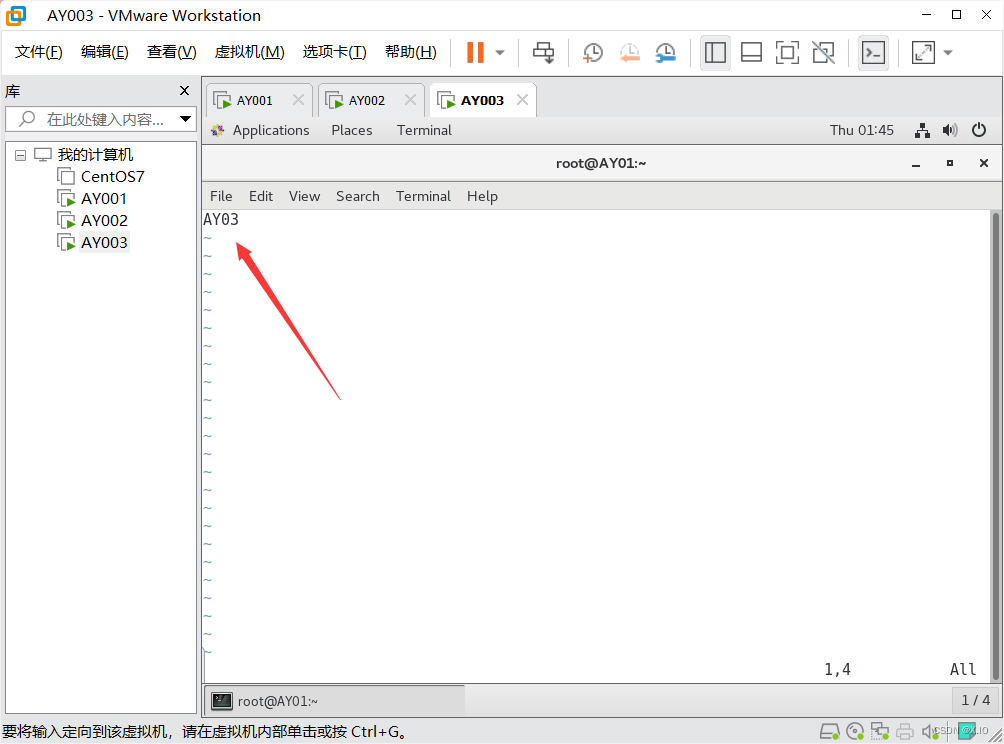
修改主机名:vim /etc/hostname #直接改即可,新主机名在reboot重启后生效
修改IP地址:vim /etc/sysconfig/network-scripts/ifcfg-ens33 #分别将AY002和AY003的IP地址改为192.168.111.132和192.168.111.133
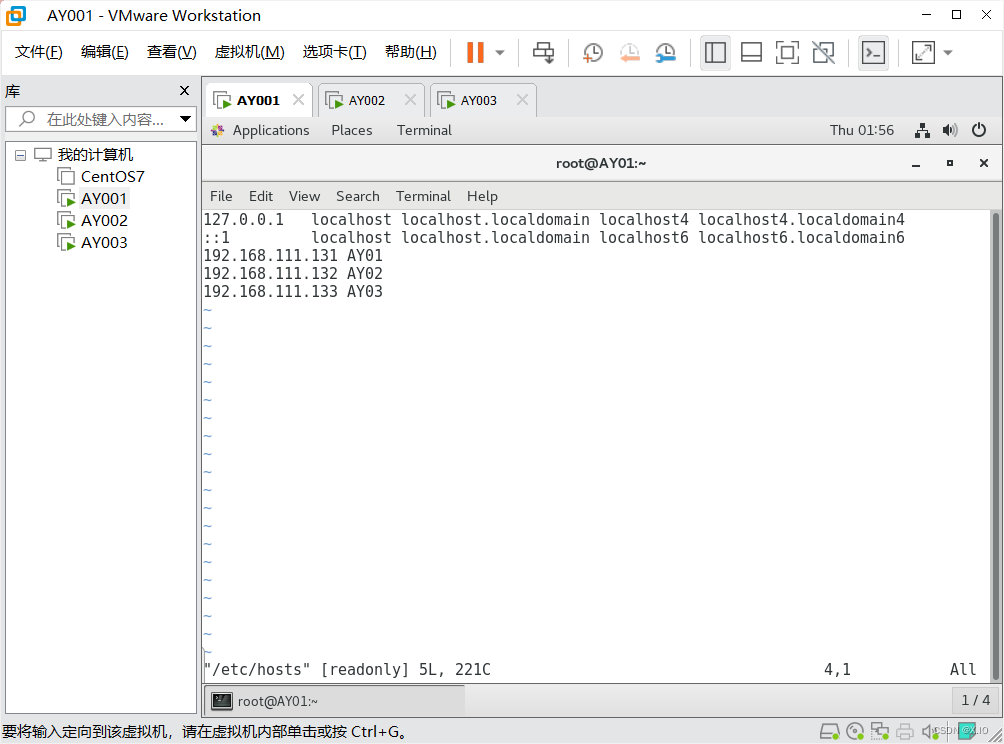
·修改三台系统的hosts文件,使IP与主机名对应
vim /etc/hosts
内容如下:
192.168.111.131 AY01
192.168.111.132 AY02
192.168.111.133 AY03
(1)修改前:
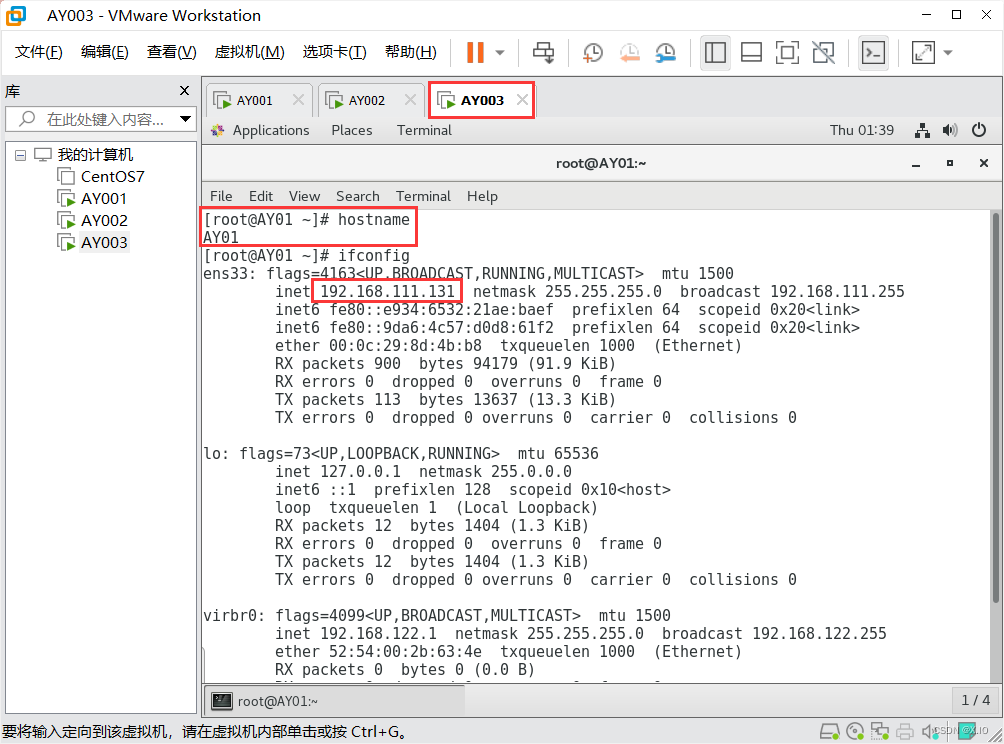
AY002:
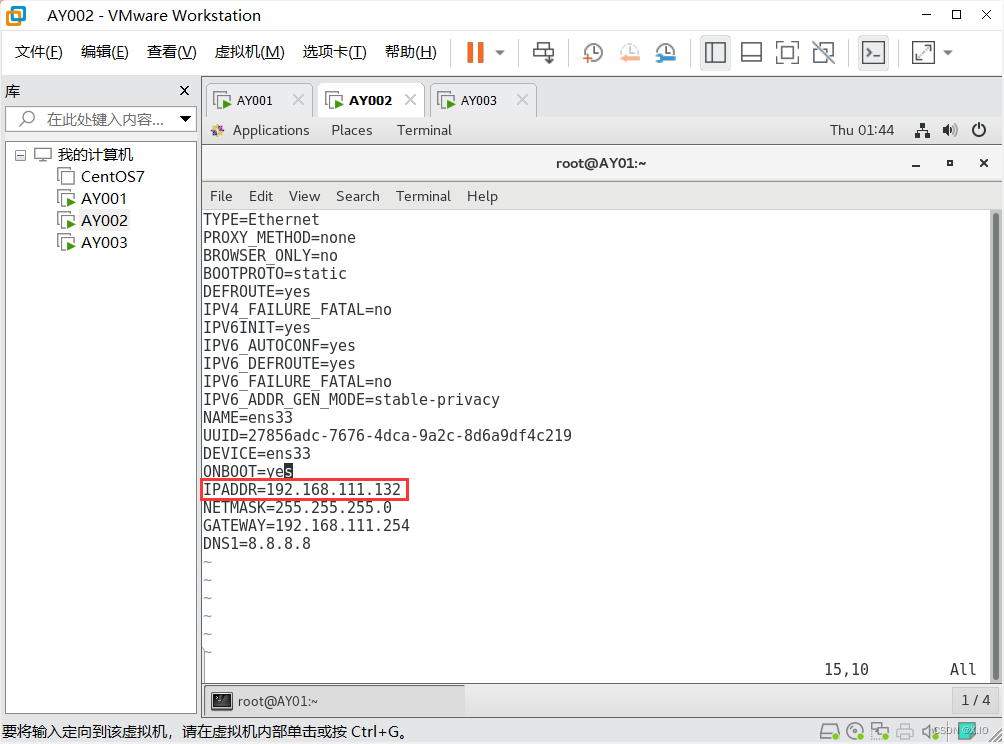
AY003:
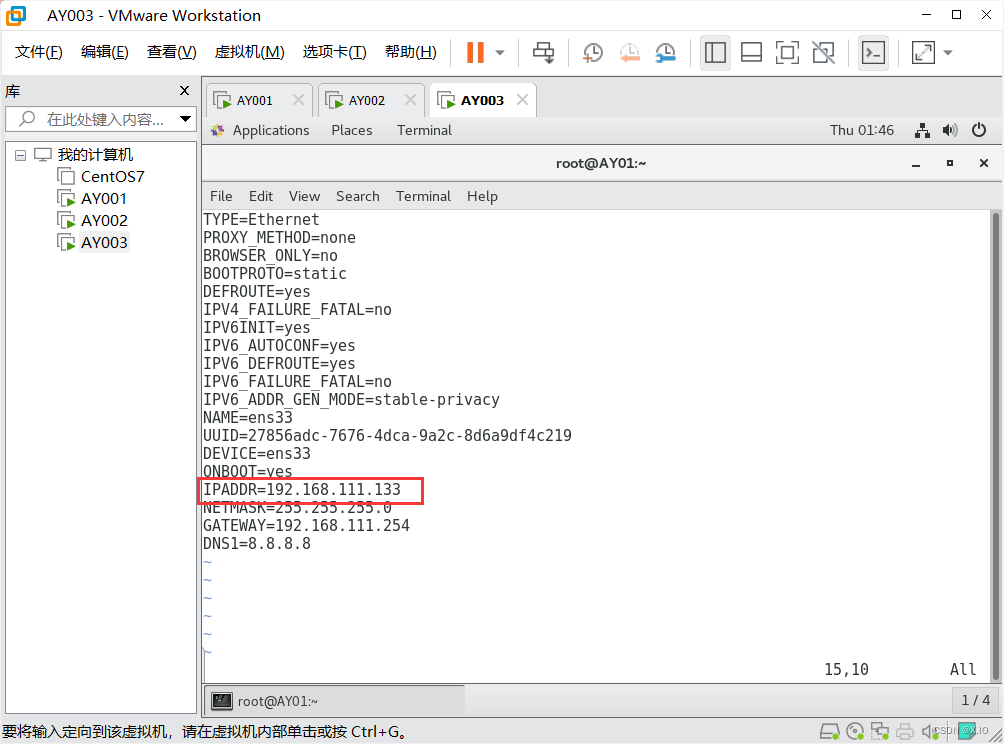
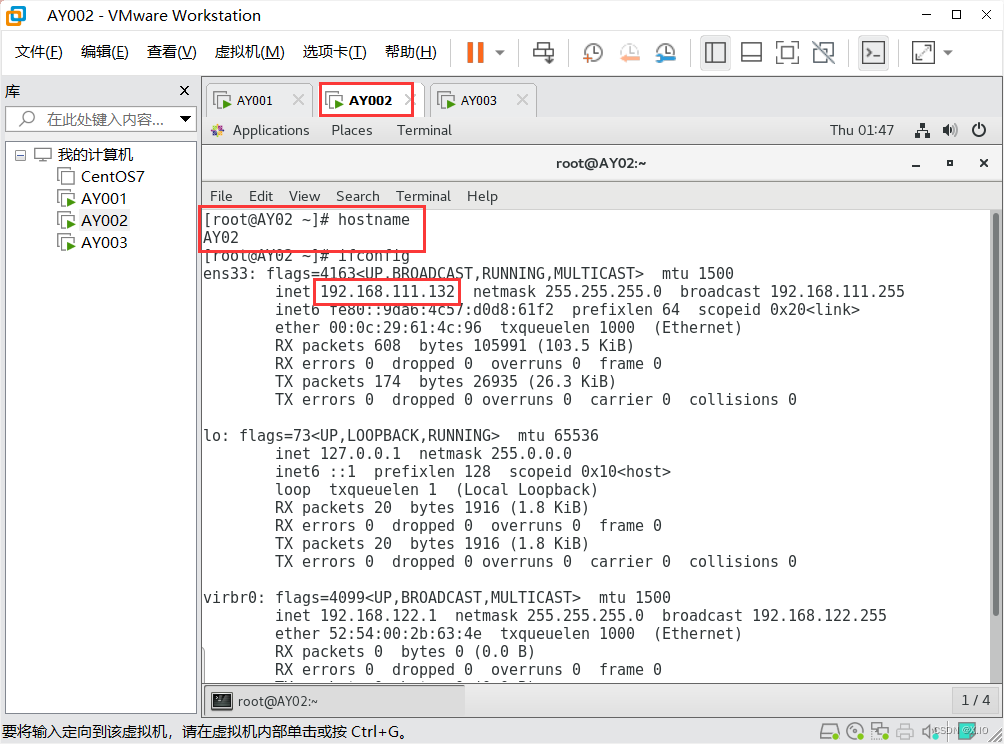
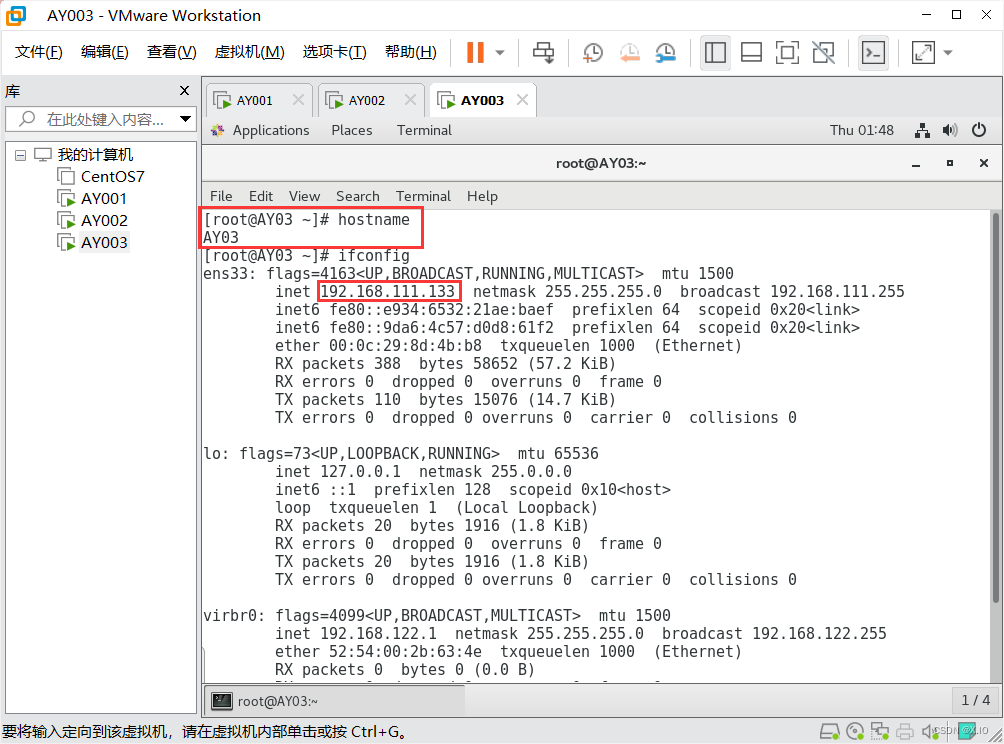
重启后:
(2)修改三台系统的hosts文件(注意是三台,每台的内容都一样)
具体内容如下图:
至此,我们完成了克隆的部分。
4.免密登陆
经过前面的操作,我们已经可以用Xshell来远程控制虚拟机AY02和虚拟机AY03,
下面我们的操作将在Xshell上进行(当然,也可以依然在Vmware平台上操作)
准备:首先要保证主机名、hosts、防火墙正确设置
-
配置每个节点本身公钥和私钥(即在每个节点执行如下两个命令:)
(1)进入家目录:cd ~ (2)生成公钥和私钥:ssh-keygen -t rsa ·进入.ssh目录:cd .ssh 执行上述指令,然后敲(三个回车),中间不要输入任何内容,在.ssh目录下就会生成两个文件id_rsa(私钥)、id_rsa.pub(公钥)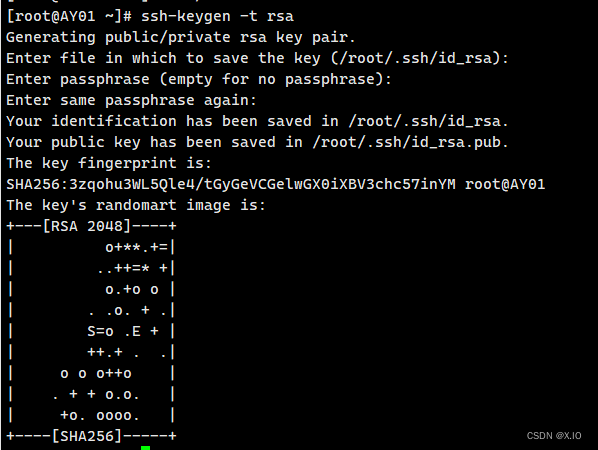
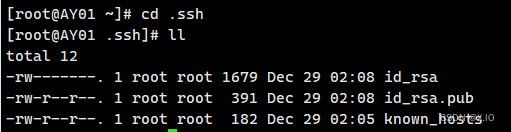
-
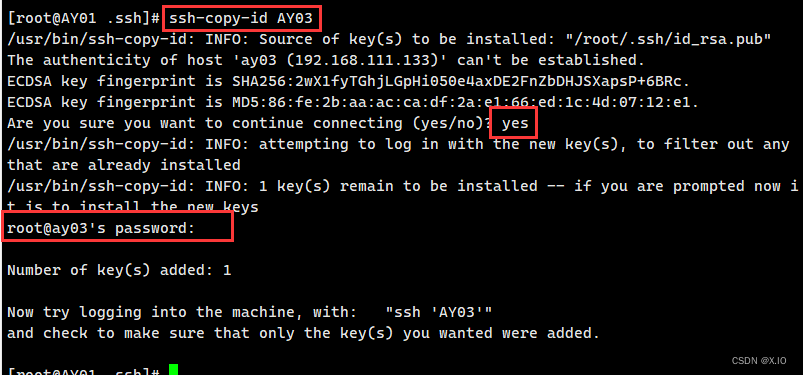
将生成的密钥分别发送给AY01、AY02、AY03
·命令1:ssh-copy-id AY01 ·命令2:ssh-copy-id AY02 ·命令3:ssh-copy-id AY03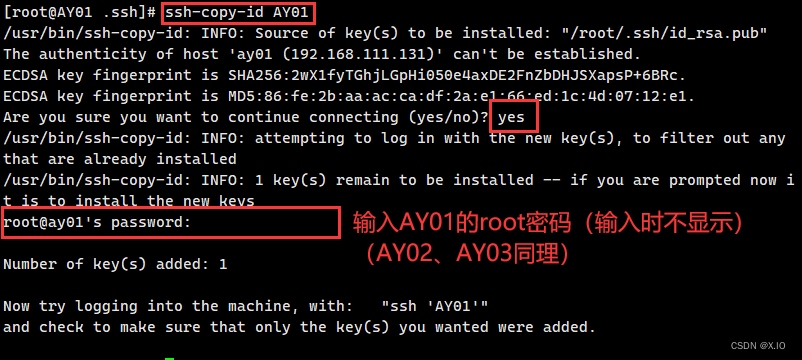
测试一下:(成功如下图 )
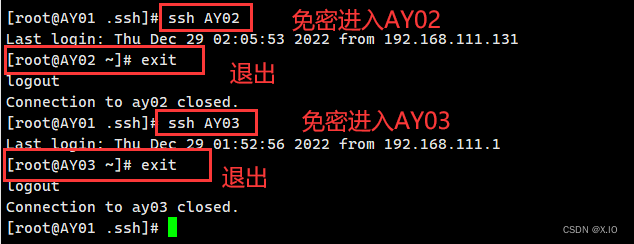
-
在 AY02 和 AY03 中重复上述操作
最终结果如下:
AY02: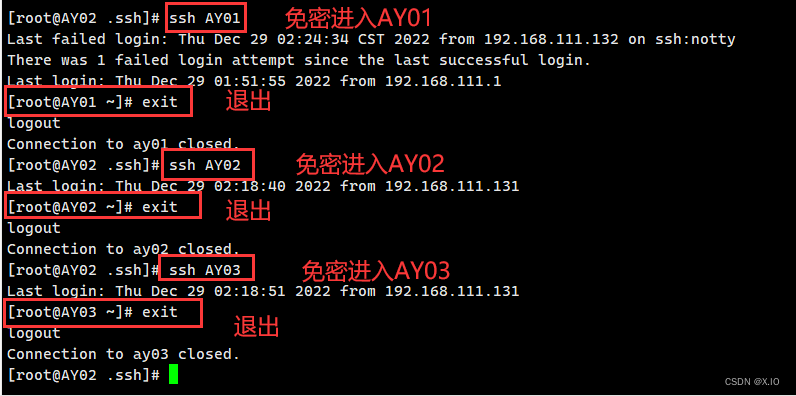
AY03:

至此,我们完成了三台系统之间的免密登陆。
5.安装Hadoop
-
利用Xshell中的Xftp,把 Windows 中的 Hadoop-2.7.2上传到 虚拟机AY01的/opt/source文件夹中
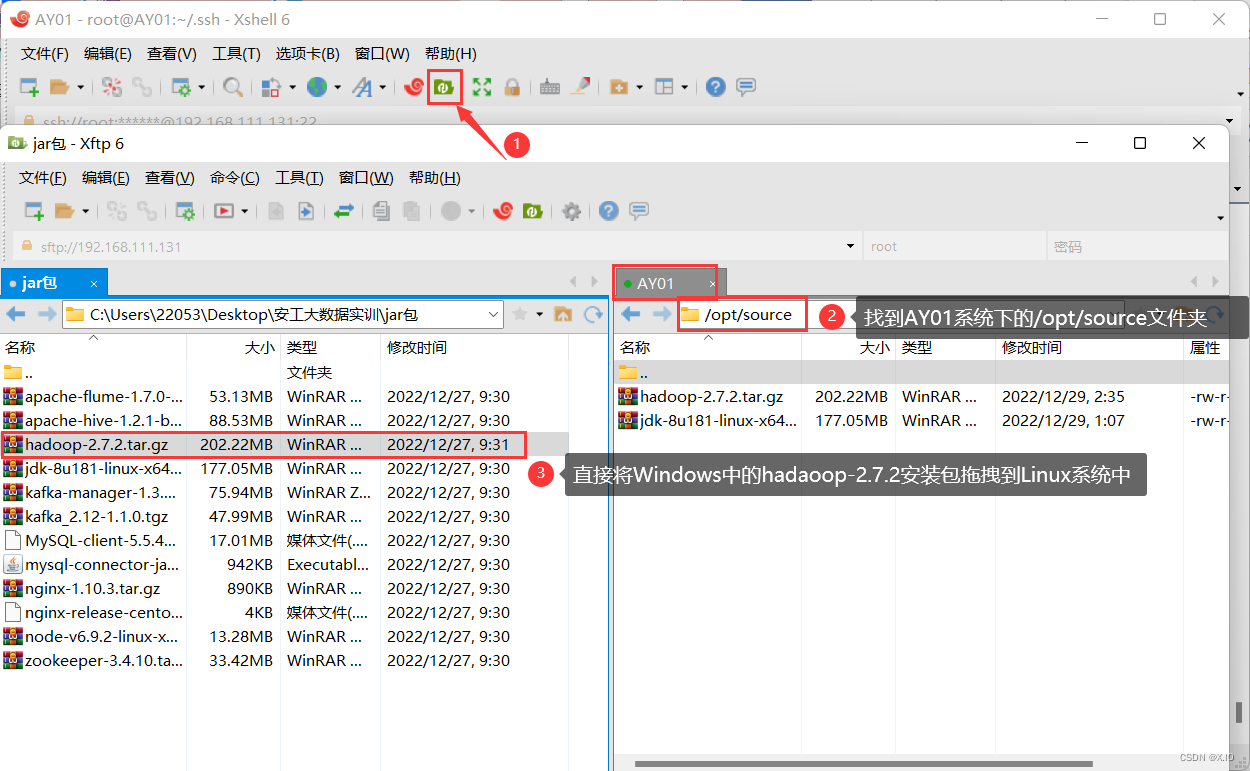
-
解压 Hadoop-2.7.2 压缩包
·解压命令:tar -zxvf hadoop-2.7.2.tar.gz ·移动到/opt/module文件夹中:mv hadoop-2.7.2 ../module解压后:

移动后:
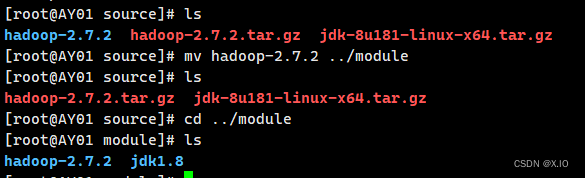
-
配置 Hadoop 环境变量
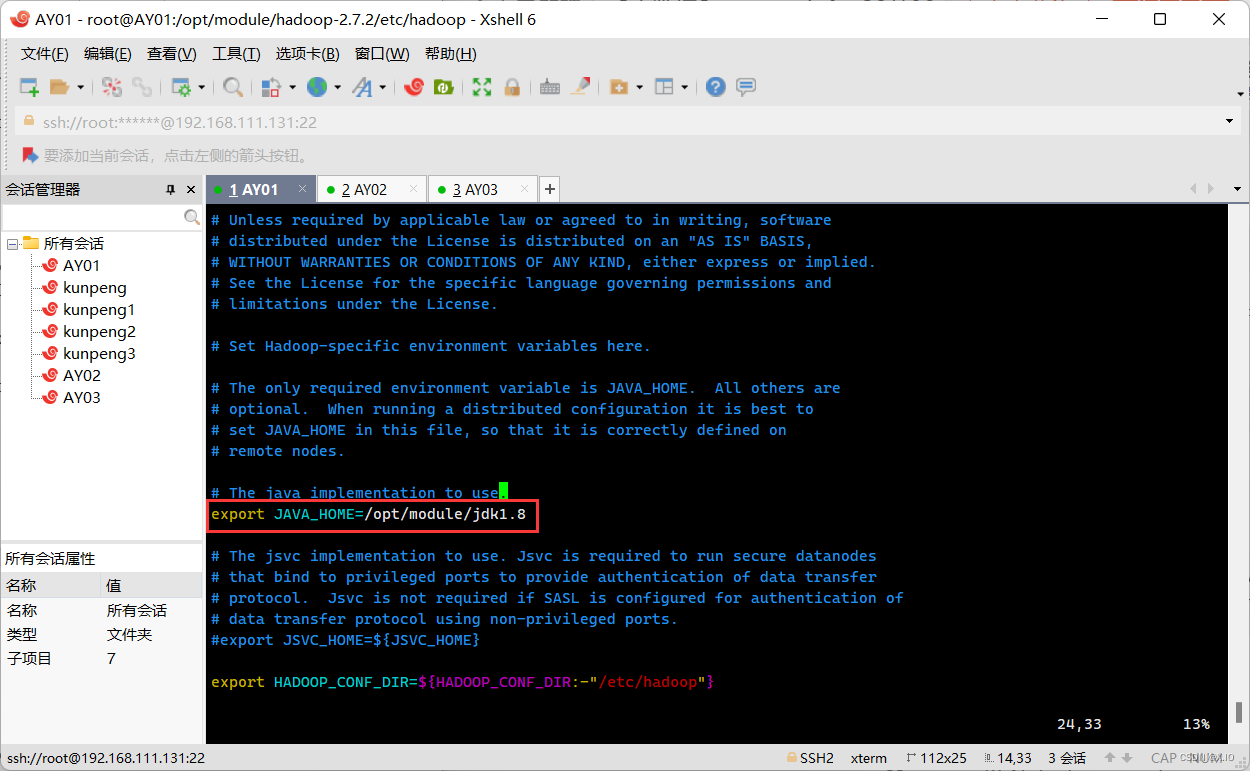
方法一: ·首先进入hadoop文件夹: cd /opt/module/hadoop-2.7.2/etc/hadoop ·配置hadoop-env.sh 配置文件 1)修改 export JAVA_HOME=${JAVA_HOME} 为 export JAVA_HOME=/opt/module/jdk1.8 2)添加以下两条语句: export HADOOP_HOME=/opt/module/hadoop-2.7.2 export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH 方法二: ·首先进入hadoop文件夹: cd /opt/module/hadoop-2.7.2/etc/hadoop ·配置hadoop-env.sh 配置文件 1)修改 export JAVA_HOME=${JAVA_HOME} 为 export JAVA_HOME=/opt/module/jdk1.8 ·其次修改/etc/profile文件,在jdk的配置语句后面添加以下两条语句: export HADOOP_HOME=/opt/module/hadoop-2.7.2 export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH这里我采用的是方法二:
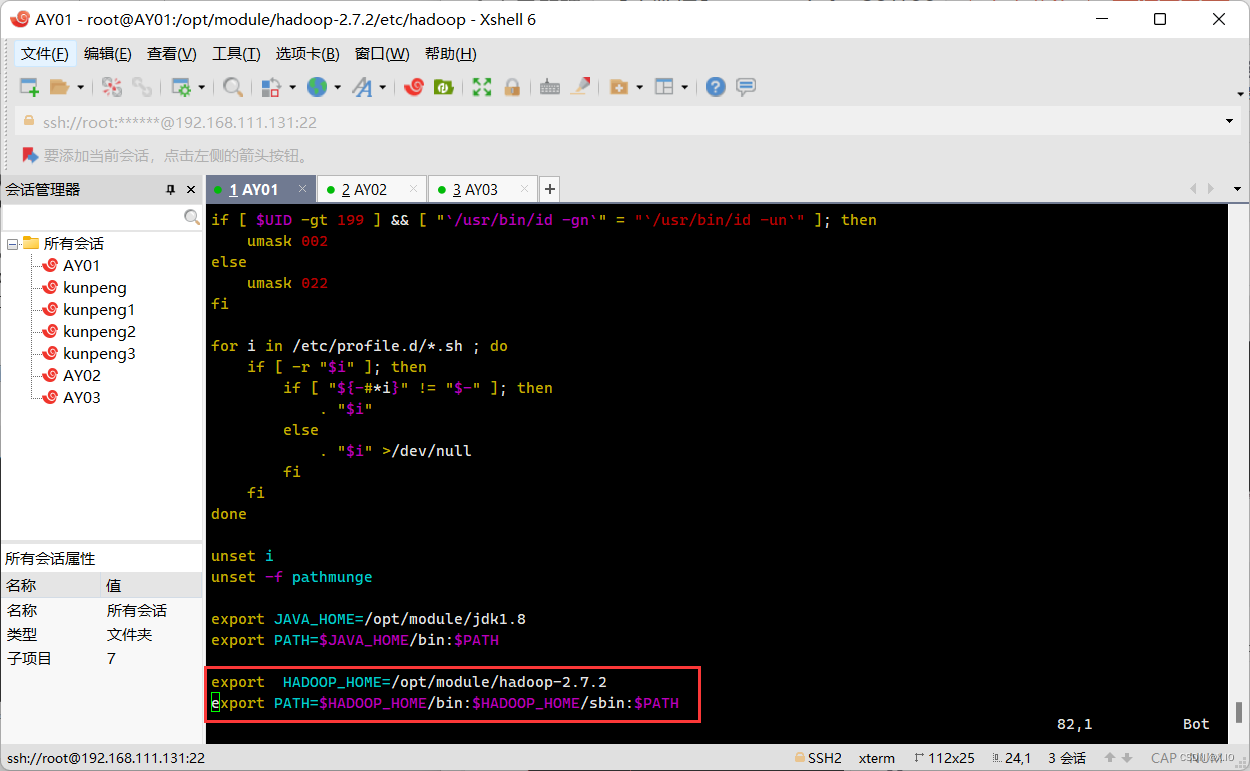
这里,我们才只是完成了AY01中的hadoop的安装和环境配置,下面我们将完善Hadoop的配置文件,然后将配置完成的 Hadoop 拷贝给 AY02 和 AY03.
集群部署:
| AY01 | AY02 | AY03 |
|---|---|---|
| HDFS | ||
| NameNode | YARN | SecondaryNameNode |
| DataNode | DataNode | DataNode |
| NodeManager | NodeManager | NodeManager |
| ResourceManager |
6.配置Hadoop配置文件
一共需要配置7个文件,这7个文件都在/opt/module/hadoop-2.7.2/etc/hadoop 文件夹下。
把配置信息写在文件的<configuration></configuration>之间
-
core-site.xml
·vim core-site.xml 在该文件中的<configuration></configuration>之间复制下列内容,注释不要复制,只复制<property></property>部分。 <!-- 指定HDFS中NameNode的地址 --> <property> <name>fs.defaultFS</name> <value>hdfs://AY01:9000</value> </property> <!-- 指定hadoop运行时产生文件的存储目录 --> <property> <name>hadoop.tmp.dir</name> <value>/opt/module/hadoop-2.7.2/data/tmp</value> </property>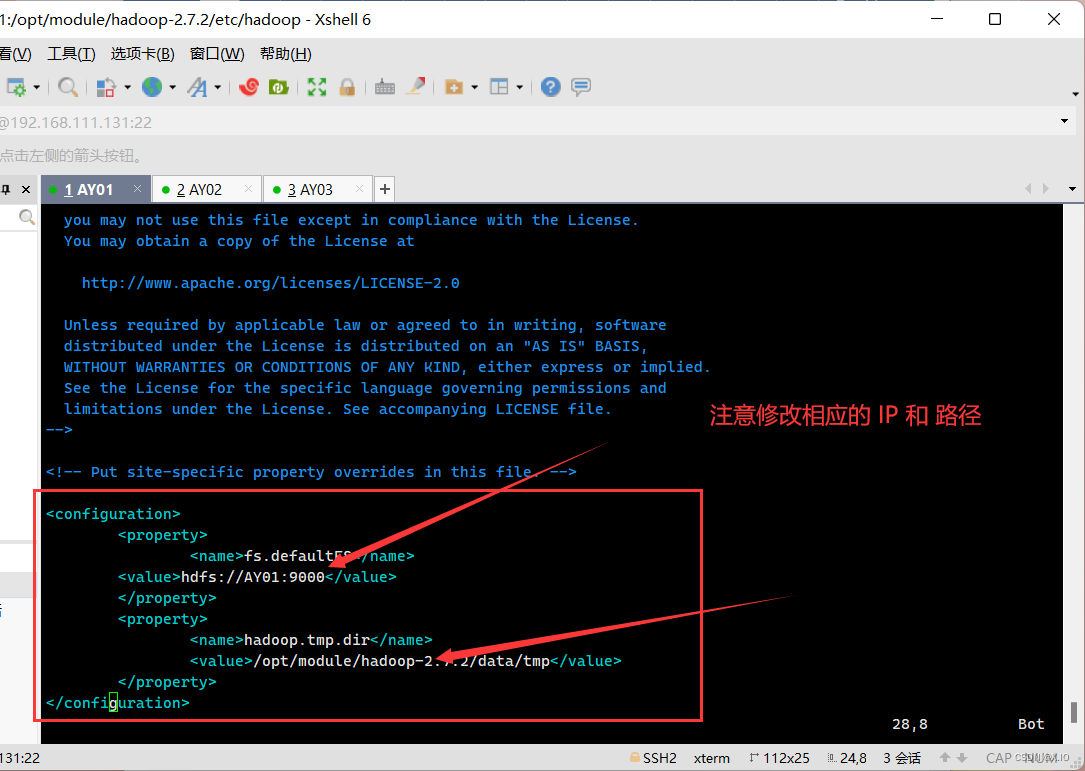
-
Hdfs 部分有3个文件:
(2.1)hadoop-env.sh(此文件在安装Hadoop时已配置过,故可以省略) ·修改内容:export JAVA_HOME=/opt/module/jdk1.8(2.2)hdfs-site.xml
·vim hdfs-site.xml ·添加的内容如下: <property> <name>dfs.replication</name> <value>3</value> </property> <property> <name>dfs.namenode.secondary.http-address</name> <value>AY03:50090</value> </property>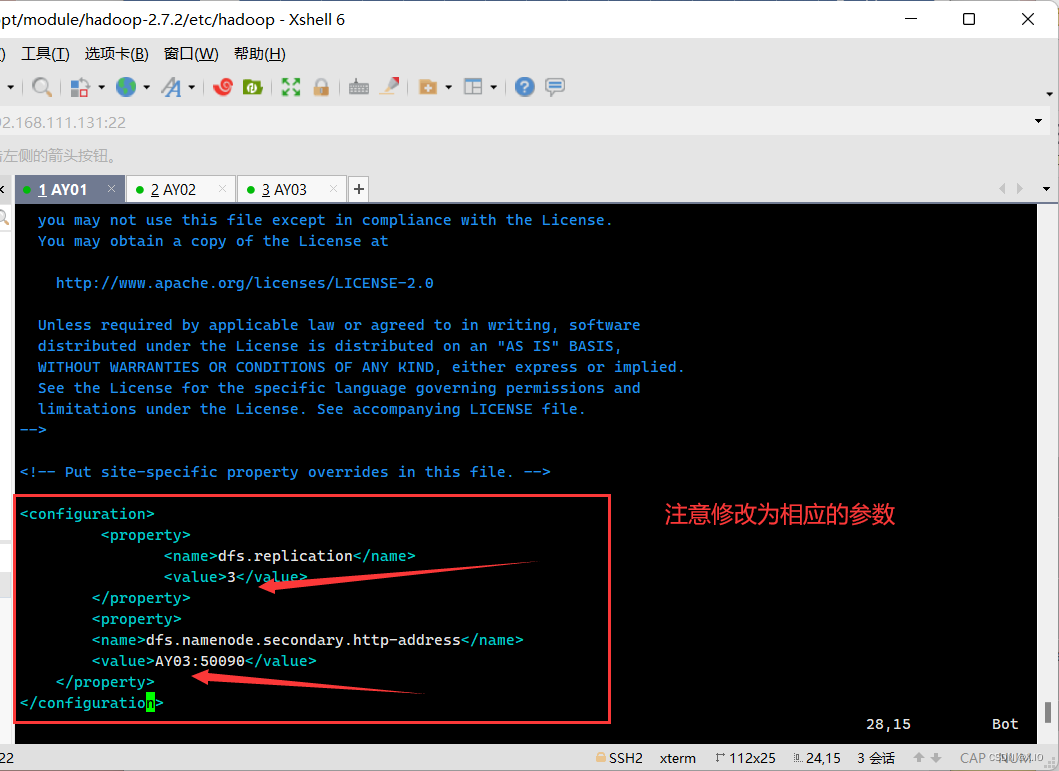
(2.3)slaves
·vim slaves ·把原文件中的localhost删除掉,输入集群节点名: AY01 AY02 AY03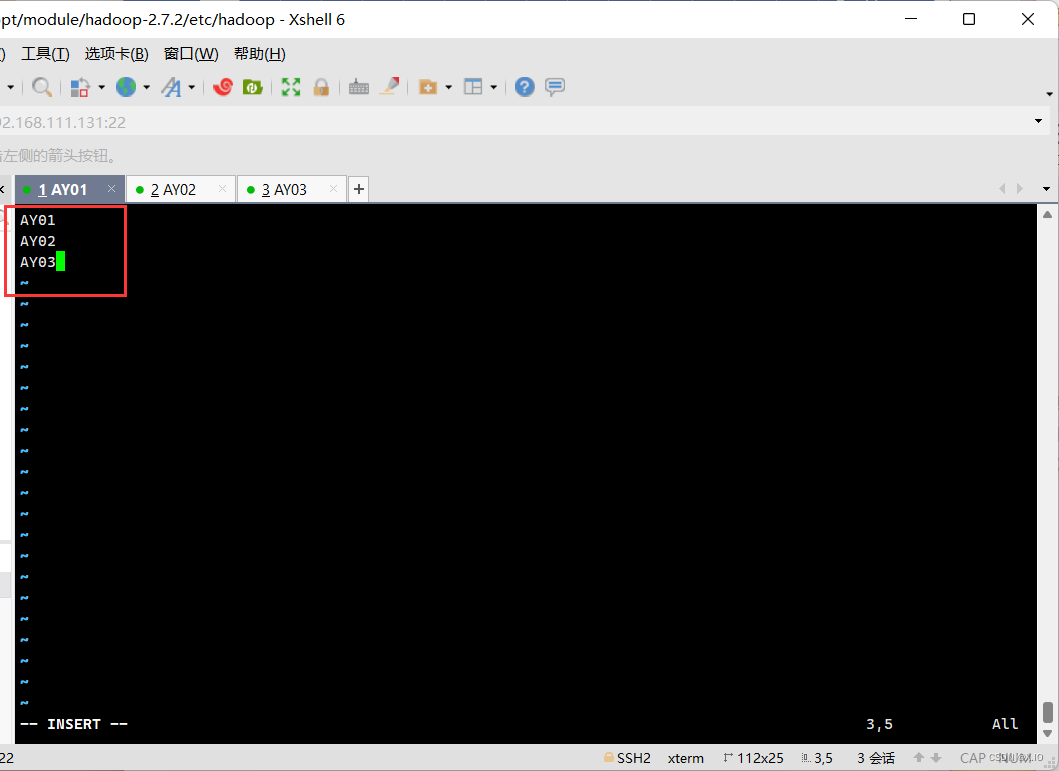
-
yarn
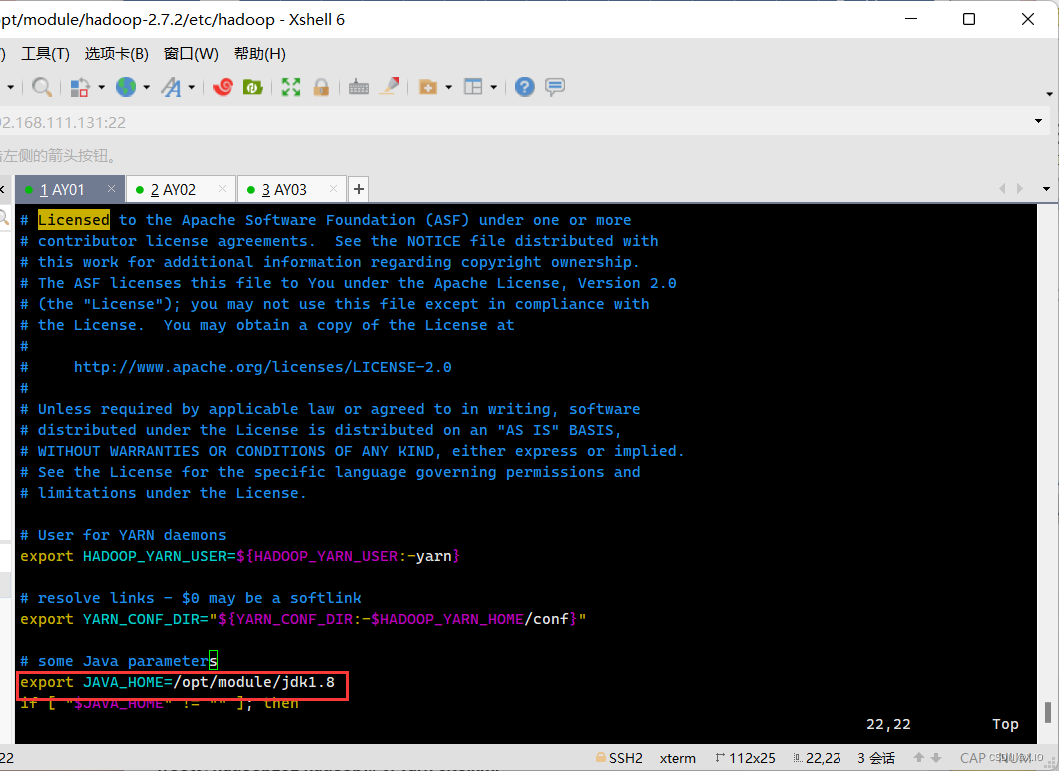
(3.1)yarn-env.sh·vim yarn-env.sh ·修改内容如下: 将 # export JAVA_HOME=/home/y/libexec/jdk1.6.0/ 修改为 export JAVA_HOME=/opt/module/jdk1.8 (JDK的实际路径)修改前:
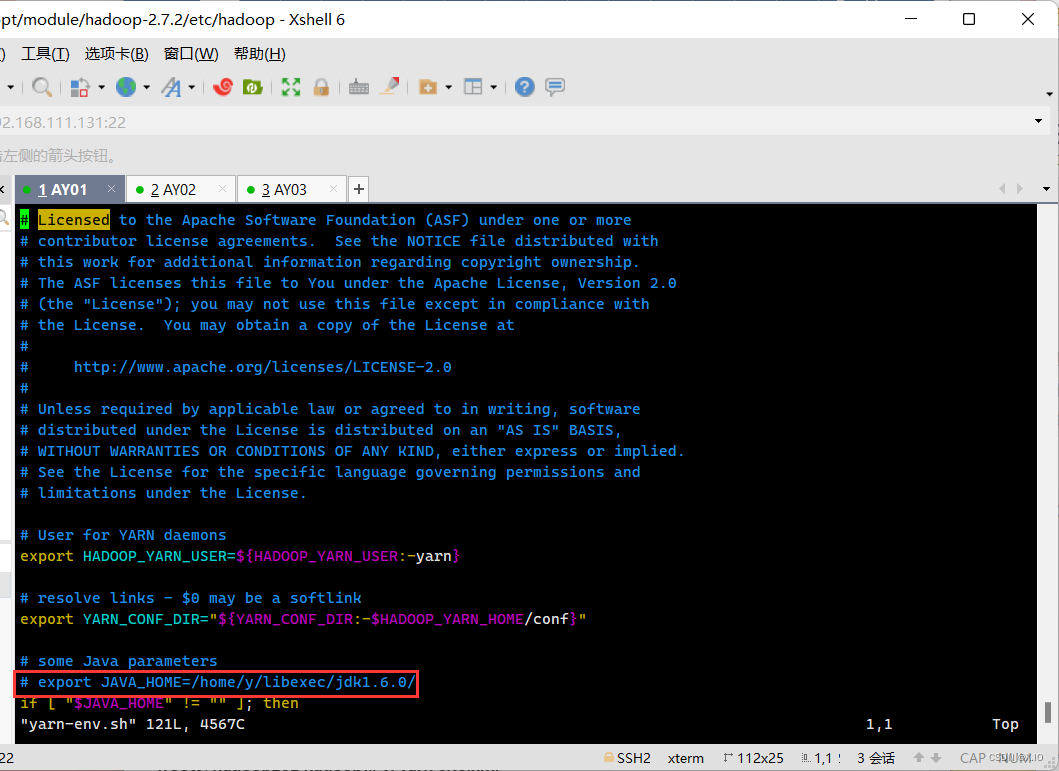
修改后:
(3.2)yarn-site.xml
·vim yarn-site.xml ·添加下面<property></property>部分: <!-- reducer获取数据的方式 --> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <!-- 指定YARN的ResourceManager的地址 --> <property> <name>yarn.resourcemanager.hostname</name> <value>AY02</value> </property>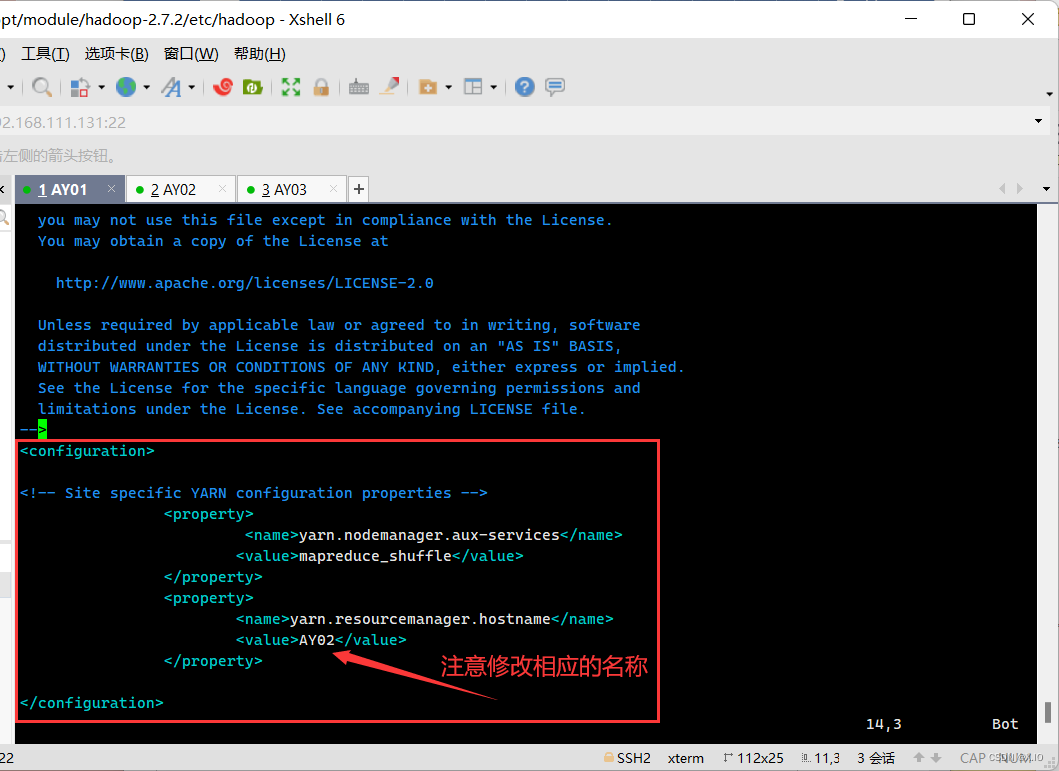
-
mapreduce
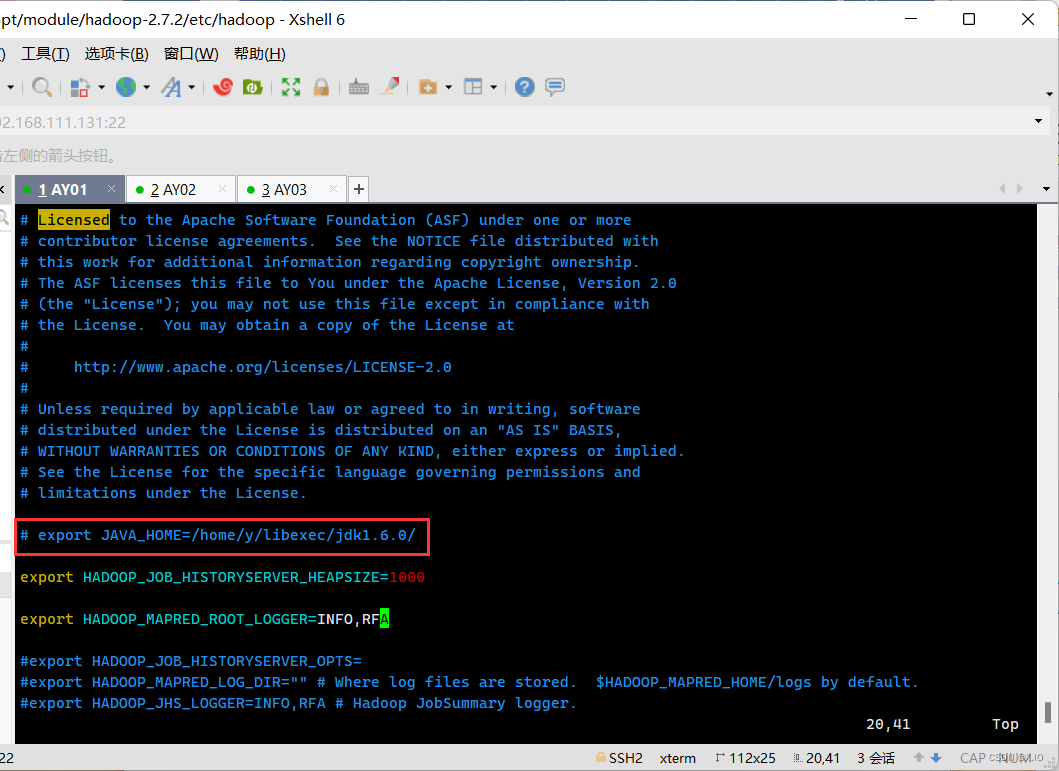
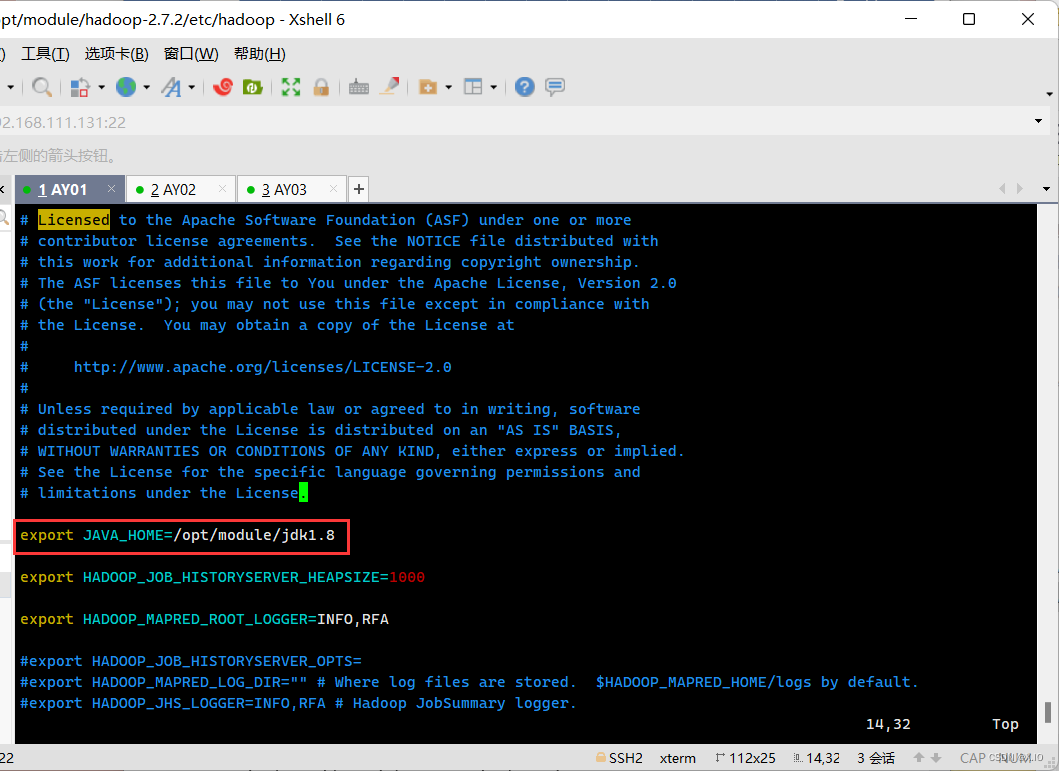
(4.1)mapred-env.sh·vim mapred-env.sh ·修改内容如下: 将# export JAVA_HOME=/home/y/libexec/jdk1.6.0/ 修改为 export JAVA_HOME=/opt/module/jdk1.8修改前:
修改后:
(4.2)mapred-site.xml·hadoop文件夹下没有mapred-site.xml文件,但有一个mapred-site.xml.template文件, 拷贝一份该文件,并把新拷贝的文件命名为mapred-site.xml 命令为:cp mapred-site.xml.template mapred-site.xml ·然后再打开mapred-site.xml ·添加<property></property>部分: <!-- 指定mr运行在yarn上 --> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property>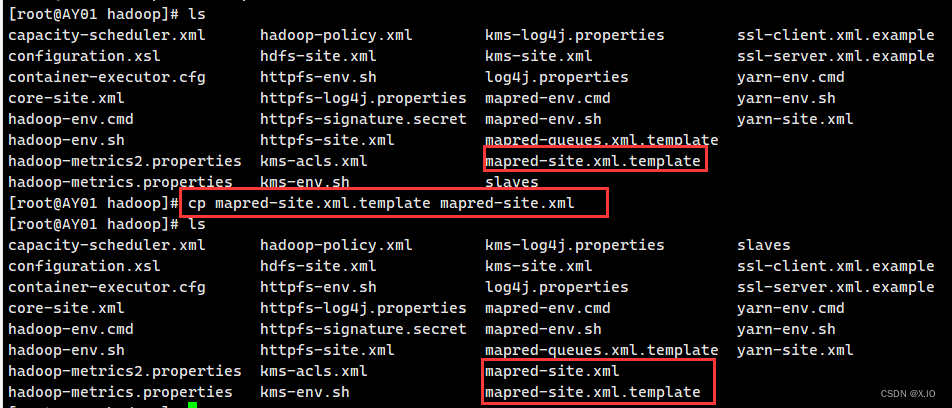
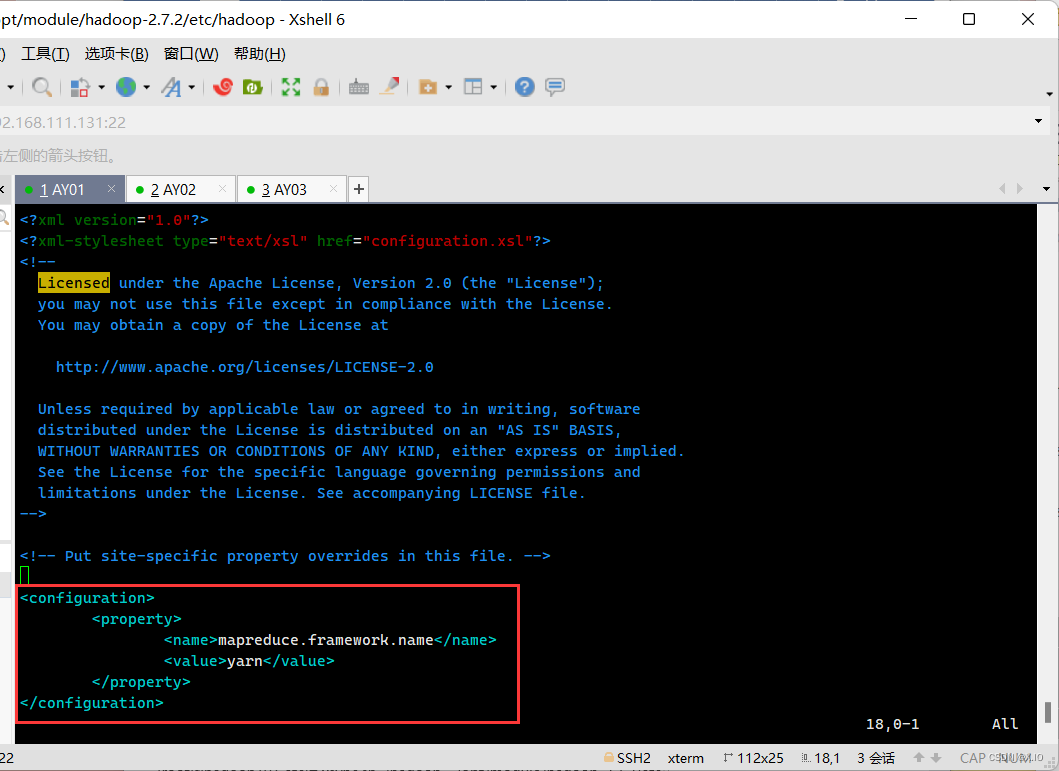
-
分发 Hadoop文件夹
自此,所有文件全部配置完毕,接下来我们需要把AY01节点的hadoop文件夹远程分发到AY02、AY03上的对应位置 ·首先回到/opt/module文件夹下 cd /opt/module ·然后执行如下命令: scp -r ./hadoop-2.7.2/ AY02:/opt/module scp -r ./hadoop-2.7.2/ AY03:/opt/module
至此,三台系统的Hadoop配置完全一致。
7.启动服务
-
格式化 namenode
根据前面的集群部署图可知,namenode在AY01节点上,因此只需要在AY01节点上进行格式化即可。 ·首先,进入到hadoop目录下:cd/opt/module/hadoop-2.7.2 ·格式化命令:bin/hdfs namenode -format
-
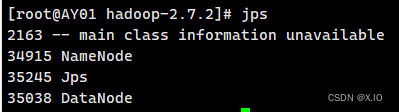
启动 namenode
·启动命令:sbin/start-dfs.sh ·可通过jps命令查看是否启动
-
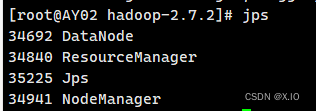
启动 yarn
根据之前集群部署的情况可知,我们把yarn部署在了AY02节点上,因此我们需要在AY02节点上启动yarn。 ·启动yarn命令:sbin/start-yarn.sh ·通过jps命令查看是否启动
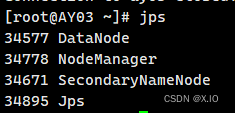
AY03启动的服务有:
-
关闭命令
·yarn关闭命令:sbin/stop-yarn.sh ·hadoop关闭命令:sbin/stop-dfs.shHadoop启动和关闭命令: 1.start-all.sh 启动所有的Hadoop守护进程。(包括NameNode、Secondary NameNode、DataNode、JobTracker、TaskTrack) 2.stop-all.sh 停止所有的Hadoop守护进程。(包括NameNode、Secondary NameNode、DataNode、JobTracker、TaskTrack) 3.start-dfs.sh 启动Hadoop HDFS守护进程NameNode、Secondary NameNode 和 DataNode。 4.stop-dfs.sh 停止Hadoop HDFS守护进程NameNode、Secondary NameNode 和 DataNode。 5.hadoop-daemons.sh start namenode 单独启动NameNode守护进程 6.hadoop-daemons.sh stop namenode 单独停止NameNode守护进程 7.hadoop-daemons.sh start datanode 单独启动DataNode守护进程 8.hadoop-daemons.sh stop datanode 单独停止DataNode守护进程 9.hadoop-daemons.sh start secondarynamenode 单独启动SecondaryNameNode守护进程 10.hadoop-daemons.sh stop secondarynamenode 单独停止SecondaryNameNode守护进程 11.start-mapred.sh 启动Hadoop MapReduce守护进程JobTracker和TaskTracker 12.stop-mapred.sh 停止Hadoop MapReduce守护进程JobTracker和TaskTracker 13.hadoop-daemons.sh start jobtracker 单独启动jobtracker守护进程 14.hadoop-daemons.sh stop jobtracker 单独停止jobtracker守护进程 15.hadoop-daemons.sh start tasktracker 单独启动TaskTracker守护进程 16.hadoop-daemons.sh stop tasktracker 单独停止TaskTracker守护进程
至此,我们就算是完成了Hadoop集群完全分布式的搭建!!
8.在集群上测试一个jar包-单词统计的功能
-
在本地创建一个 word.txt 文件
·命令1:touch word.txt ·命令2:vi word.txt 输入: 小明 小张 小李 小明 张三 王五 张三 小李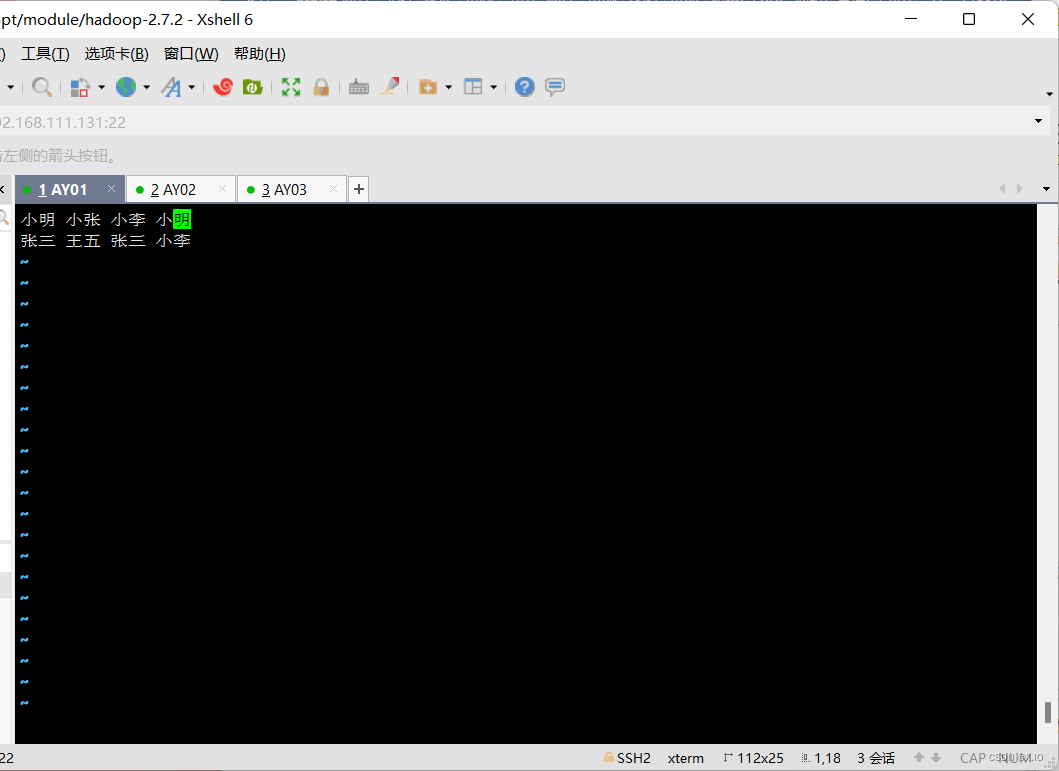
-
在根目录下创建一个 input 的文件夹
·命令:bin/hdfs dfs -mkdir /input -
把 word.txt 文件上传到服务器中的 input 文件夹中
·命令:bin/hdfs dfs -put ./word.txt /input -
查看是否上传成功
·命令:bin/hdfs dfs -ls /input
-
执行 wordcount 单词统计功能
在执行此命令前,再次确认集群中所有节点的防火墙都已经关闭!·命令:bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar wordcount /input /output·output文件夹内有2个文件 查看命令:bin/hdfs dfs -ls /output ·输出output文件夹文件的内容: bin/hdfs dfs -cat /output/*
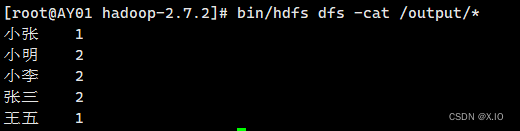
至此,基本的完全分布式已经建立成功!!
- 删除文件系统上的 output 文件夹(了解)
·删除命令:bin/hdfs dfs -rm -r /output - 删除output 文件夹的part-r-00000文件(了解)
·删除命令:bin/hdfs dfs -rm /output/part-r-00000 - yarn的浏览器页面查看(集群中已执行的任务)
由于我们的yarn部署在 AY02 节点,该节点的固定IP为:192.168.111.132 所以我们可以通过浏览器:http://192.168.111.132:8088/cluster 查看yarn上已执行的任务。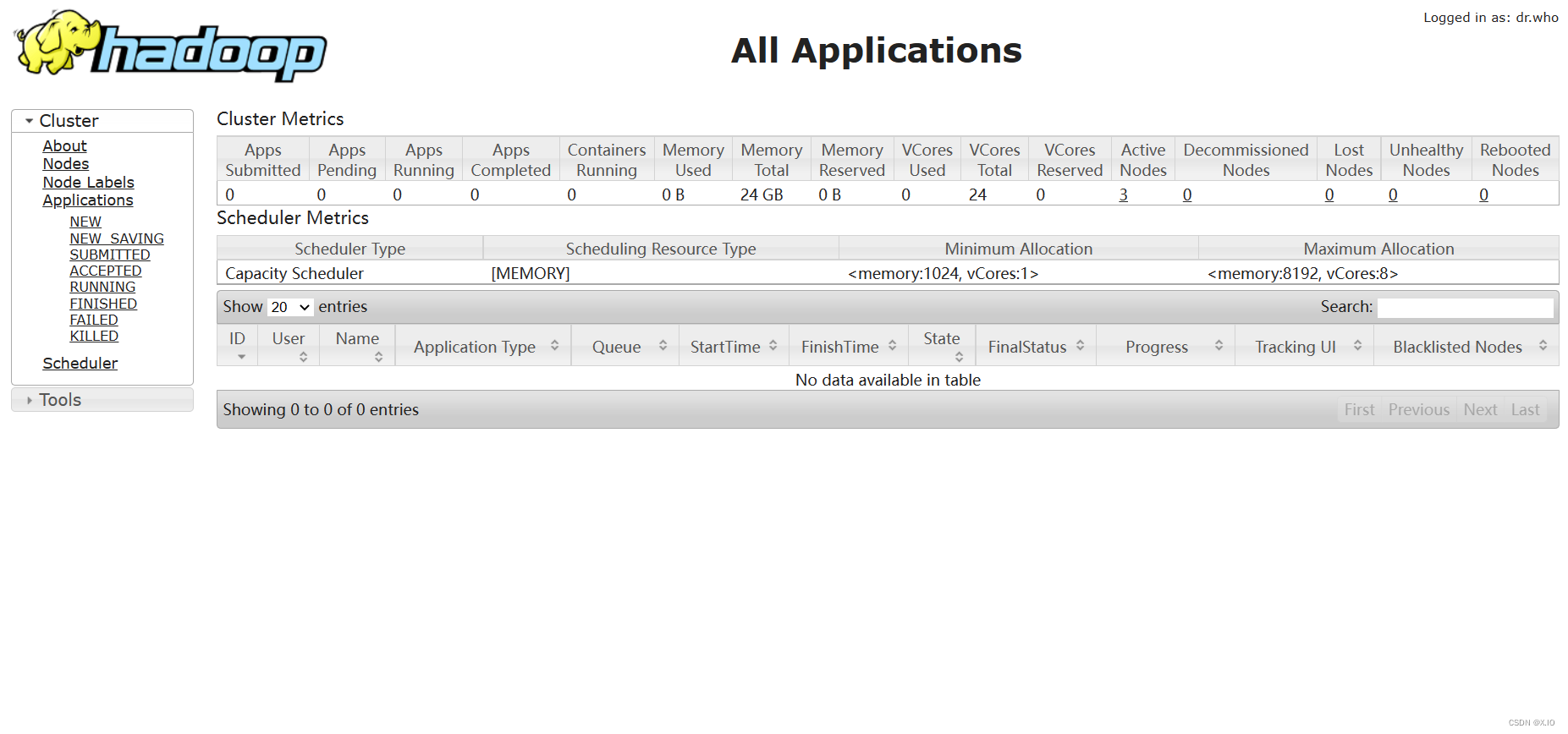
问题总结
- 整理流程我参考的是centos6的文档,centos7的命令与其不同。如修改主机名、关闭防火墙等
- centos7无法连接Xshell的情况