我一共使用了三台ubuntu虚拟机,网络使用的是Nat模式,因为配置中涉及到IP,所以建议使用Nat模式固定的IP。
ubuntu-18.04.4 Hadoop完全分布式环境安装
系统配置
IP分配
主节点:192.168.75.128
从节点1:192.168.75.129
从节点2:192.168.75.130
主机名设置
主节点为master,从节点分别为slave1和slave2



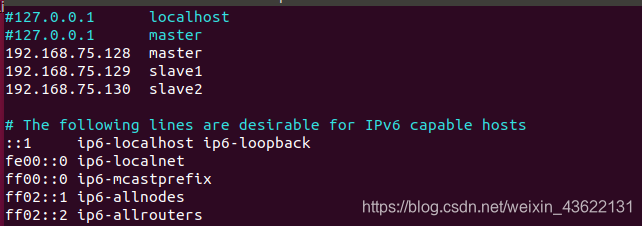
配置hosts
将各节点的IP与主机名对应,IP与主机名中间相隔一个TAB,一定要注释上面的127.0.0.1(三个节点都要配置),否则后面启动集群会检测不到节点
重启网络
sudo /etc/init.d/networking restart
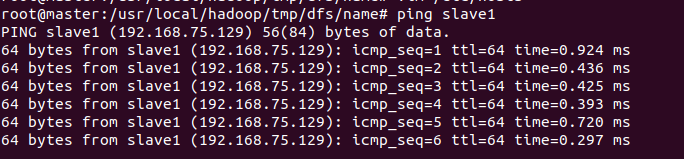
检查网络
看相互能否ping通,ping通则配置成功

创建hadoop账户
在主节点上创建hadoop账户
sudo adduser hadoop
把hadoop用户加入到hadoop用户组
sudo usermod -a -G hadoop hadoop
查看结果
cat /etc/group |grep hadoop

把hadoop用户赋予root权限
sudo vim /etc/sudoers
在root下添加下面这段
hadoop ALL=(root) NOPASSWD:ALL

然后用同样方法在slave1和slave2上创建hadoop用户
SSH免密登录
首先在master上创建ssh-key
ssh-keygen -t rsa -P ""
一直回车
然后在~/.ssh/下生成两个文件:id_rsa和id_rsa.pub
在slave1和slave2上以同样的方式生成
然后分别用(这里的目录无所谓,传到哪里都行,就是将从节点的id_rsa传到主节点上)
scp id_rsa.pub [email protected]:/home/zf/slave1_id_rsa.pub
scp id_rsa.pub [email protected]:/home/zf/slave2_id_rsa.pub
然后将slave1和slave2传过来的id_rsa文件移动到~/.ssh/目录下
sudo mv /home/zf/slave1_id_rsa.pub ~/.ssh/slave1_id_rsa.pub
sudo mv /home/zf/slave2_id_rsa.pub ~/.ssh/slave2_id_rsa.pub

将id_rsa.pub、slave1_id_rsa.pub、slave2_id_rsa.pub追加到authorized_keys授权文件中
cat *.pub >>authorized_keys
这个时候已经可以免密登录本机了
ssh localhost

将master上的公钥文件传给slave1和slave2
scp authorized_keys [email protected]:/home/zf
scp authorized_keys [email protected]:/home/zf
然后将公钥移动到~/.ssh/目录下
cp /home/zf/authorized_keys ~/.ssh/authorized_keys
修改公钥文件的权限
sudo chmod 664 authorized_keys
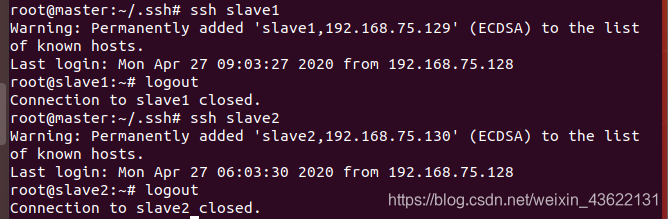
然后测试三个虚拟机是否可以免密登录
master连接slave1和slave2
slave1连接master和slave2
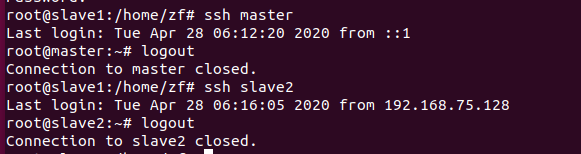
slave2连接master和slave1
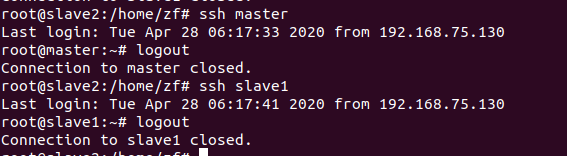
都能相互免密登录则配置成功
安装Hdoop
见我之前搭建伪分布式的博文:ubuntu-18.04.4 Hadoop伪分布式环境安装
只有core-site.xml,hdfs-site.xml,yarn-site.xml,slaves这四个文件需要重新配置其余对于安装和环境的配置都相同(配置中的路径和伪分布式博文中的路径相同,建议先按照那个配,然后将这几个配置文件改一下就可以了)
进入Hadoop的安装目录,下面操作的路径均是在此目录的基础上的相对路径
cd /usr/local/hadoop
配置core-site.xml
vim etc/hadoop/core-site.xml
将configuration替换为下面内容
vim etc/hadoop/core-site.xml
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
</configuration>

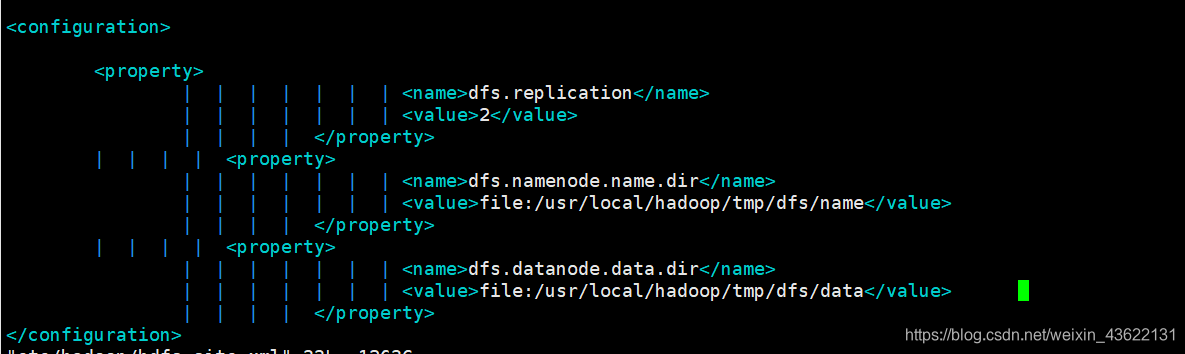
配置hdfs-site.xml
vim etc/hadoop/hdfs-site.xml
由于有两个从主机slave1、slave2,所以dfs.replication设置为2
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/data</value>
</property>
</configuration>
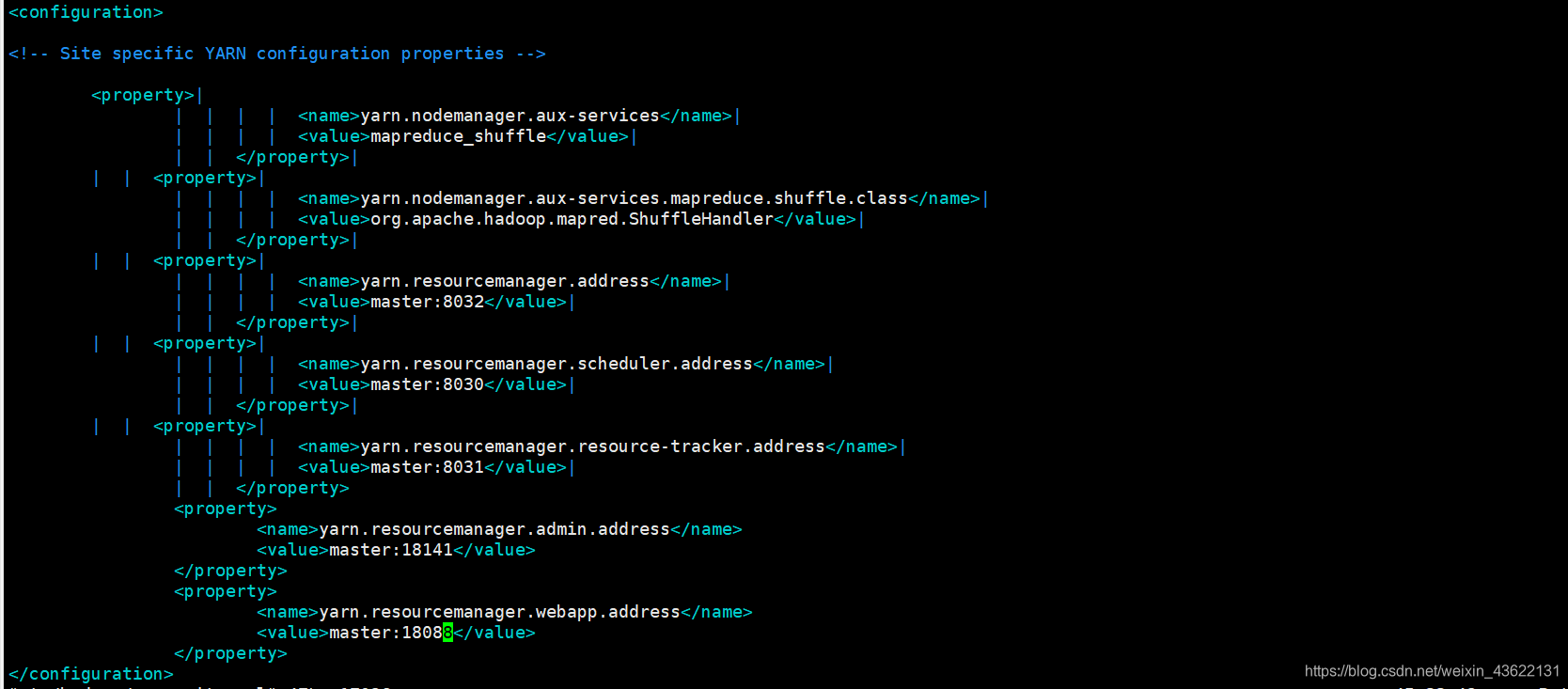
配置yarn-site.xml
vim etc/hadoop/yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<property>|
<name>yarn.nodemanager.aux-services</name>|
<value>mapreduce_shuffle</value>|
</property>|
<property>|
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>|
<value>org.apache.hadoop.mapred.ShuffleHandler</value>|
</property>|
<property>|
<name>yarn.resourcemanager.address</name>|
<value>master:8032</value>|
</property>|
<property>|
<name>yarn.resourcemanager.scheduler.address</name>|
<value>master:8030</value>|
</property>|
<property>|
<name>yarn.resourcemanager.resource-tracker.address</name>|
<value>master:8031</value>|
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master:18141</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:18088</value>
</property>
</configuration>
配置slave
vim etc/hadoop/slaves
加上两个从节点的主机名即可
slave1
slave2

这个时候master的hadoop已经完全配置好了
接下来将master的hadoop传到slave1和slave2
scp -r /usr/local/hadoop [email protected]:/home/zf
scp -r /usr/local/hadoop [email protected]:/home/zf
然后在slave1和slave2中将hadoop移到/usr/local下
mv /home/zf/hadoop /usr/local/
启动Hadoop
在master节点上执行(只在master上执行)
hdfs namenode -format
运行启动脚本
start-all.sh
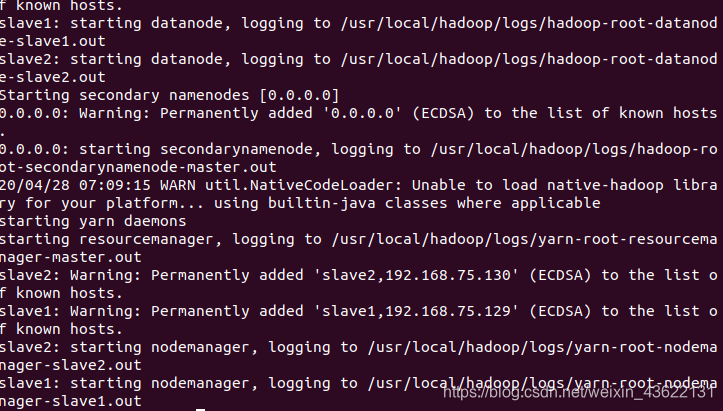
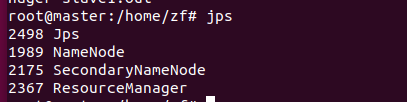
master进程
slave1进程

slave2进程
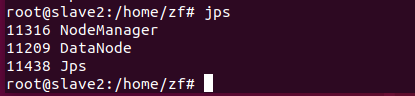
和上图一样则启动成功,如果从节点的DataNode未启动看这篇博文:解决Hadoop中多次格式化导致DataNode无法启动的问题
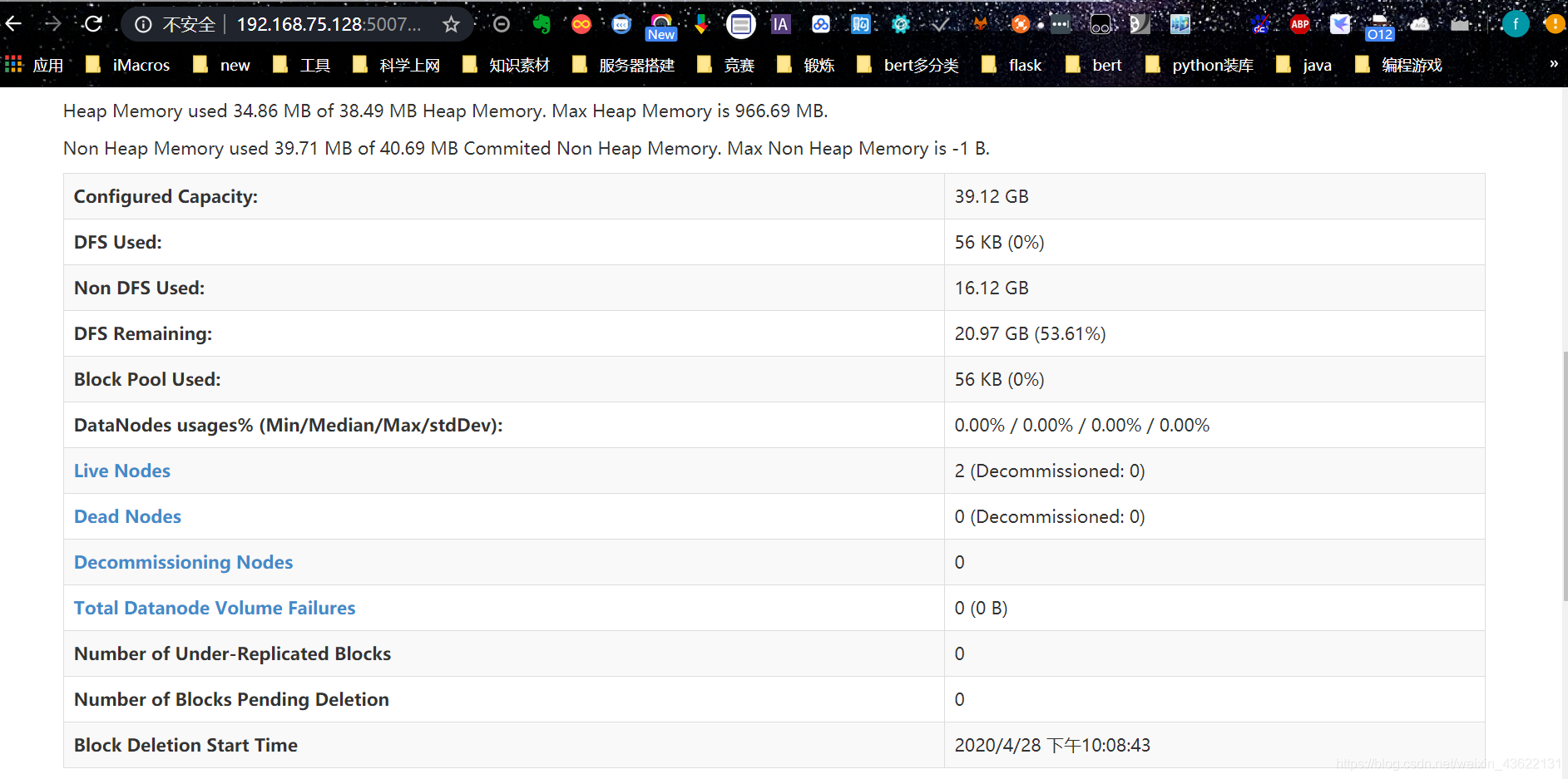
通过主节点IP+50070端口访问下面界面
可以看到有两个Live Nodes
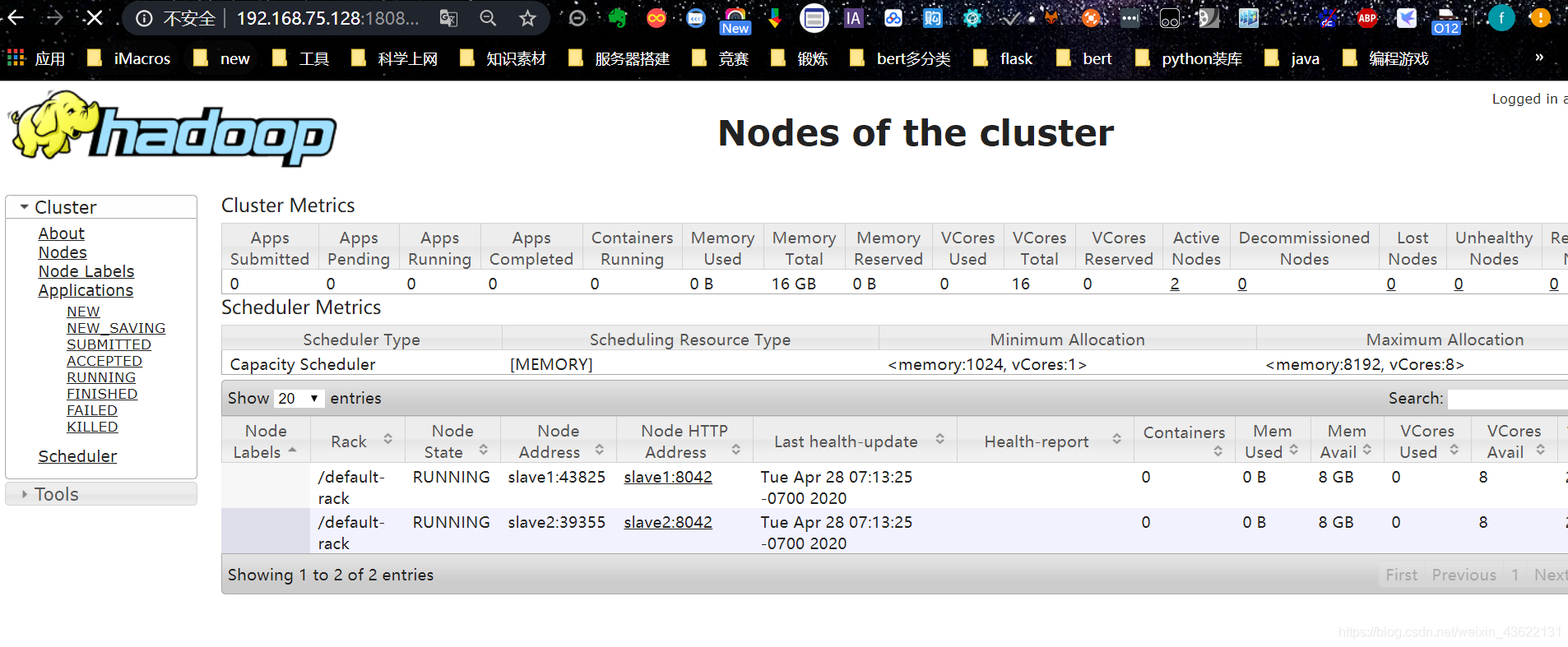
通过主节点IP+18088端口进入下面界面
可以看到slave1和slave2的详细信息
用自带的样例测试hadoop集群
hadoop jar /usr/local/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.7.jar pi 10 10
此命令是用来求圆周率,pi是类名,第一个10表示Map次数,第二个10表示随机生成点的次数
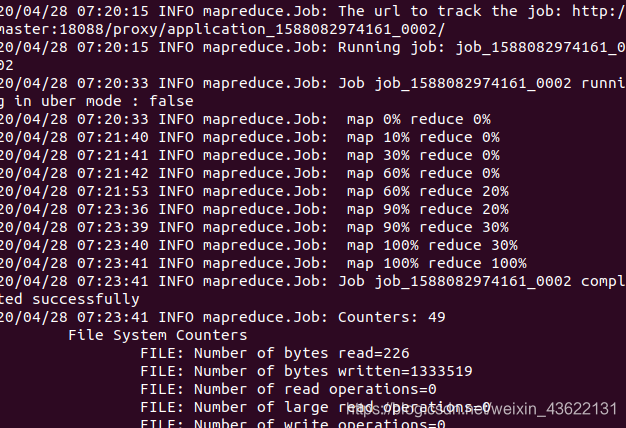
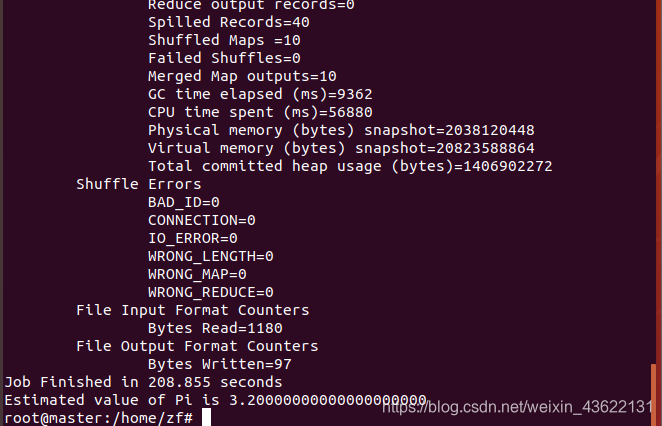
正常运行,Hadoop完全分布式搭建成功