搭建Hadoop集群
1、 安装准备
1.1、虚拟机安装
虚拟机资源下载:
点击传送门
提取码:f7fs
(1)下载并安装好VMware Workstation虚拟软件工具
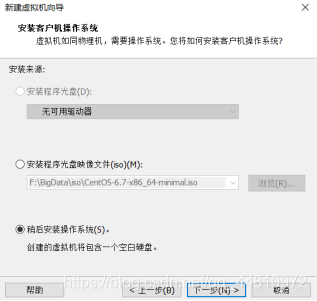
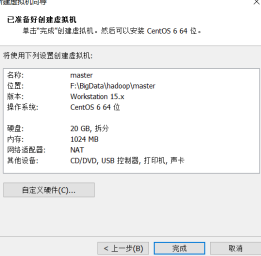
(2)创建新的虚拟机,选择好操作系统和安装位置,并完成命名
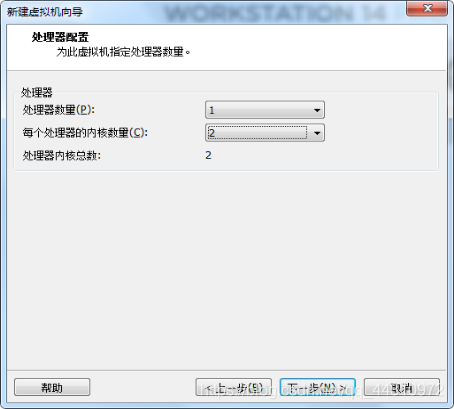
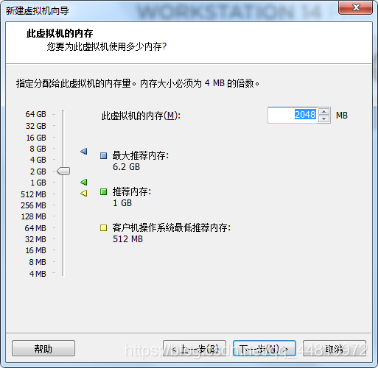
(3)选择好处理器和内存
(4)完成安装
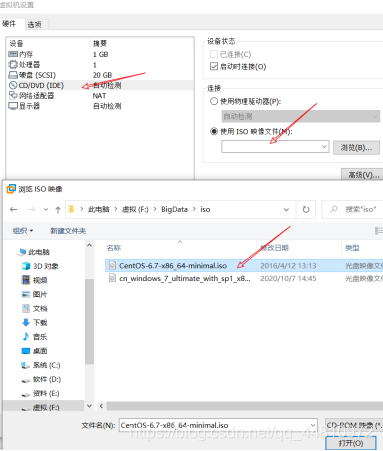
(5)选择虚拟机镜像文件
(6)启动虚拟机
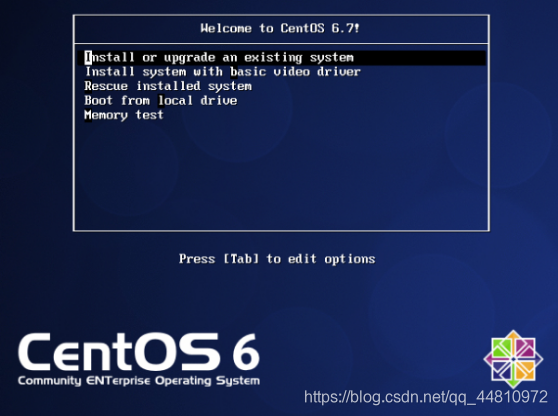
(7)完成一些基础设置
(8)命名并完成网络配置
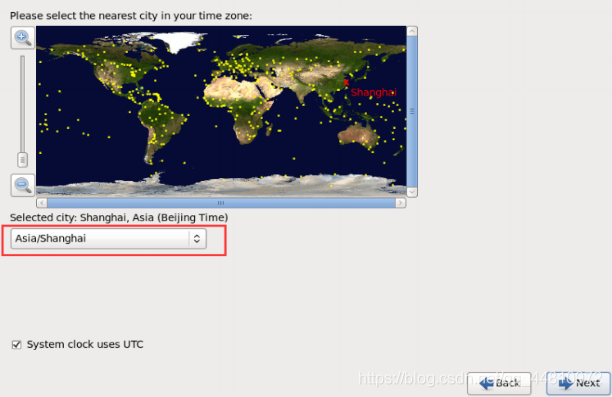
(9)选择时间
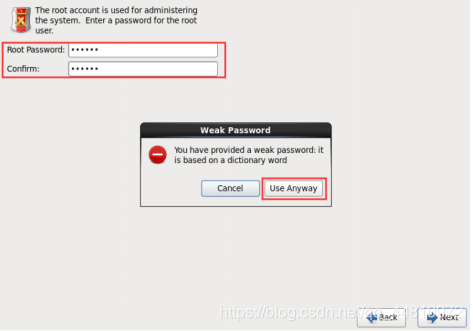
(10)设置密码
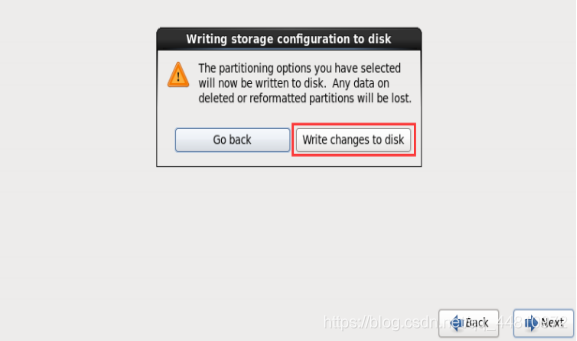
到此,虚拟机安装完毕。
1.2、 Xshell6客户端的安装
用于上传文件到虚拟机
Xshell资源下载:
点击传送门
提取码:419y
(1)双击下载好的Xshell6.exe,打开安装界面:
点击下一步:
点击下一步:
(2)选择安装路径,点击下一步:
(3)选择程序文件,点击安装:
(4)等待安装完成:
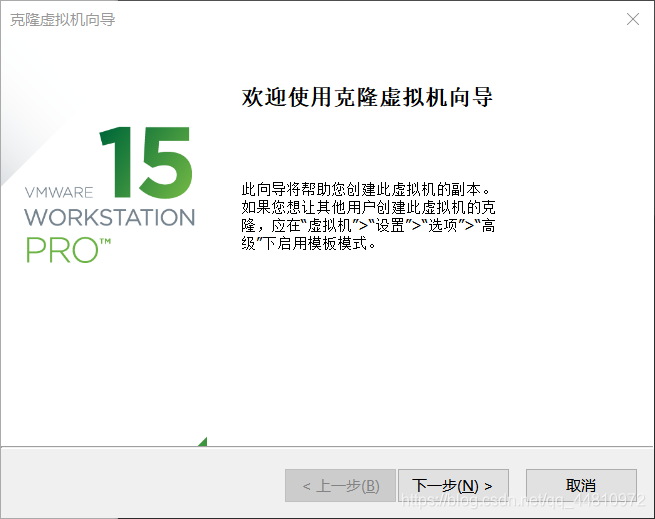
1.3、虚拟机克隆
(1)在虚拟机关机状态选择创建完整克隆
(2)虚拟机命名
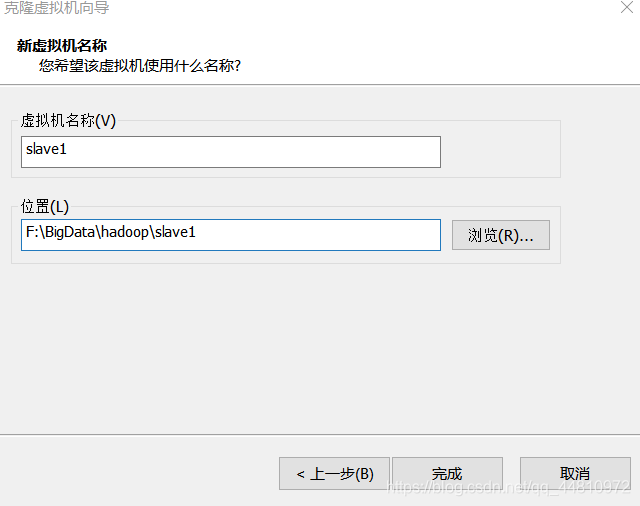
同样的,再克隆一个虚拟机slave2
最后,集群搭建所需要的三台虚拟机便克隆好了
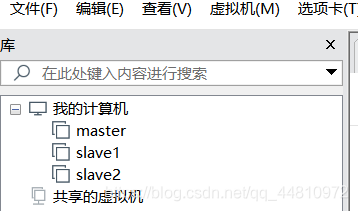
这里,题主克隆了三台虚拟机用于演示。
1.4、 虚拟机网络配置
(1)配置Linux系统网络
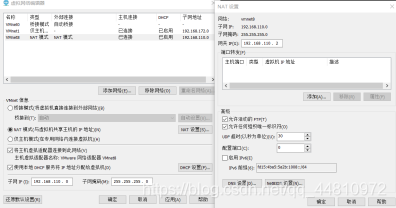
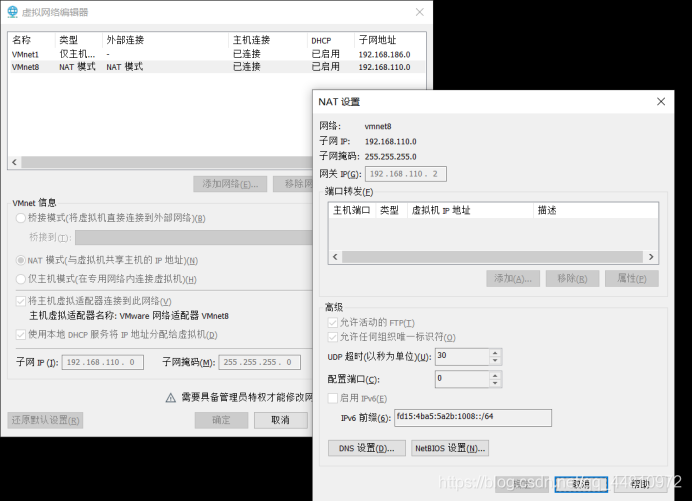
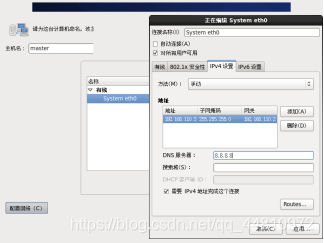
(2)打开qf1虚拟机,以root用户身份修改网卡配置
cd /etc/sysconfig/network-scripts/
vi ./ifcfg-eth0
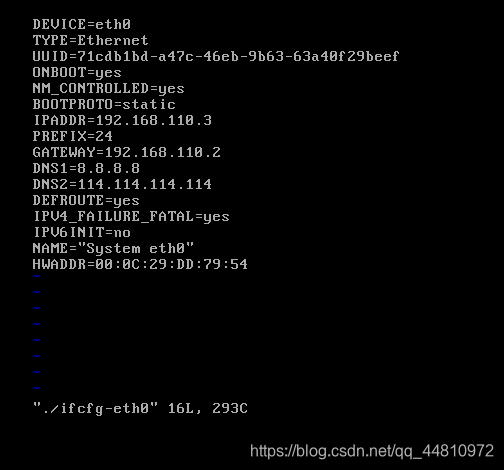
service network restart //重启网卡,将ip配置生效


Ifconfig查看网卡信息:
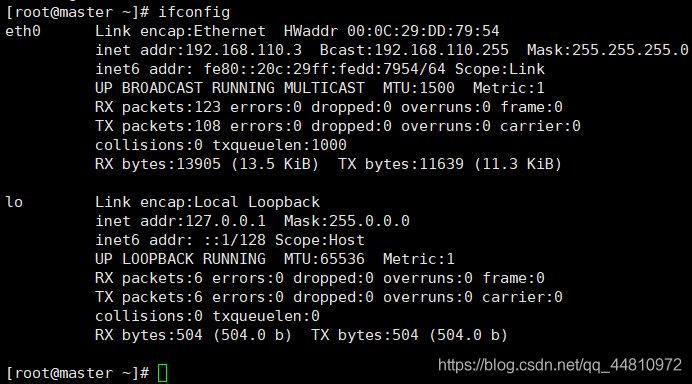
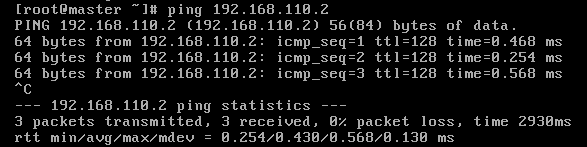
ping 192.168.142.2 //连接网关,看是否丢包
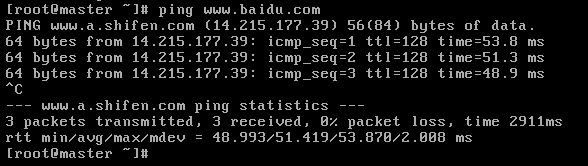
ping www.baidu.com //宿主机(window操作系统)能联网
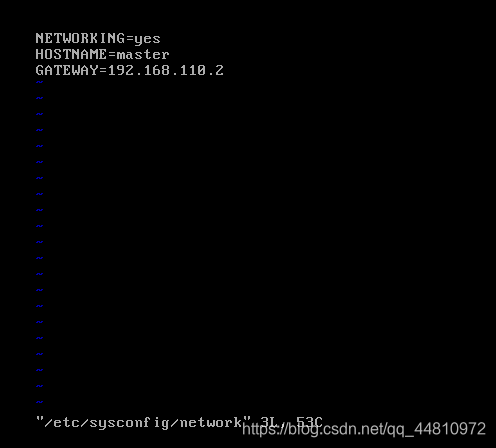
(3)设置节点的局域网访问名称
查看虚拟机的主机名: hostname
设置虚拟机主机名 hostname
vi /etc/sysconfig/network
HOSTNAME=master
设置局域网的虚拟机的主机名与IP地址的映射关系(当前机可以通过主机名访问对应的计算机)
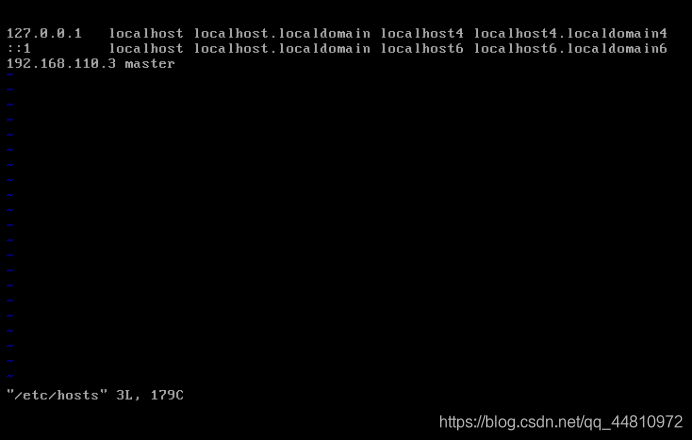
vi /etc/hosts
192.168.142.110 master
(4)关闭防火墙
service iptables stop //临时关闭防火墙
chkconfig iptables off && setenforce 0//永久关闭防火墙及军用级防火墙

(5)完成插件安装
首先,安装lrzsz插件,可以通过客户端上传文件到虚拟机端
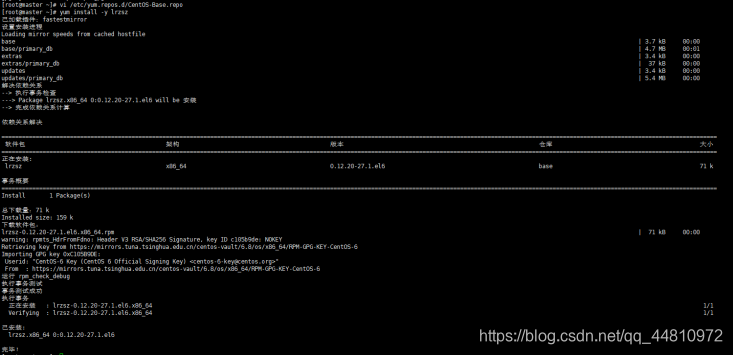
yum install -y lrzsz // 要保证宿主机能联网,虚拟机能ping www.baidu.com
其次,安装update插件,保证宿主机和虚拟机之间的时间同步
yum update
安装到这里就报错了,说是url访问不了,也就是说无法访问需要下载的资源。

网上查阅了相关文档,有的是说网络问题,有的说是DNS问题,这两块我都检查了没发现问题,然后就应该是镜像地址这块的问题了。
查看CentOS-Base.repo文件命令:
cat /etc/yum.repos.d/CentOS-Base.repo
果不其然(由于早就改好了,所以截图先欠着),由于默认的网址是国外的镜像,但是现在挂了,所以自然就无法访问了。
那就只能另寻它法了:
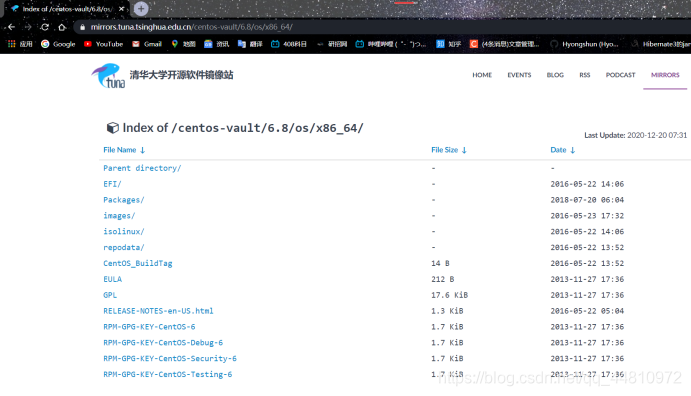
这里我给的是清华镜像的网址,里面的资源都是可以访问的(亲测有效!!)
部分需要下载的资源我也贴在了下图中(访问没有报错,确实证明此镜像网站里面的资源可以下载到虚拟机中):
然后就动手改CentOS-Base.repo文件吧!
我把完整的文件直接拿出来:
CentOS-Base.repo
[base]
name=CentOS-$releasever - Base
#mirrorlist=http://mirrorlist.centos.org/?release=6&arch=$basearch&repo=os&infra=$infra
#baseurl=http://mirror.centos.org/centos/$6/os/$basearch/
baseurl=https://mirrors.tuna.tsinghua.edu.cn/centos-vault/6.8/os/x86_64/
gpgcheck=1
#gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-CentOS-6
gpgkey=https://mirrors.tuna.tsinghua.edu.cn/centos-vault/6.8/os/x86_64/RPM-GPG-KEY-CentOS-6
#released updates
[updates]
name=CentOS-$releasever - Updates
#mirrorlist=http://mirrorlist.centos.org/?release=6&arch=$basearch&repo=updates&infra=$infra
#baseurl=http://mirror.centos.org/centos/6/updates/$basearch/
baseurl=https://mirrors.tuna.tsinghua.edu.cn/centos-vault/6.8/updates/x86_64/
gpgcheck=1
#gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-CentOS-6
gpgkey=https://mirrors.tuna.tsinghua.edu.cn/centos-vault/6.8/os/x86_64/RPM-GPG-KEY-CentOS-6
#additional packages that may be useful
[extras]
name=CentOS-$releasever - Extras
#mirrorlist=http://mirrorlist.centos.org/?release=$releasever&arch=$basearch&repo=extras&infra=$infra
#baseurl=http://mirror.centos.org/centos/$releasever/extras/$basearch/
baseurl=https://mirrors.tuna.tsinghua.edu.cn/centos-vault/6.8/extras/x86_64/
gpgcheck=1
#gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-CentOS-6
gpgkey=https://mirrors.tuna.tsinghua.edu.cn/centos-vault/6.8/os/x86_64/RPM-GPG-KEY-CentOS-6
#additional packages that extend functionality of existing packages
[centosplus]
name=CentOS-$releasever - Plus
#mirrorlist=http://mirrorlist.centos.org/?release=$releasever&arch=$basearch&repo=centosplus&infra=$infra
#baseurl=http://mirror.centos.org/centos/$releasever/centosplus/$basearch/
baseurl=https://mirrors.tuna.tsinghua.edu.cn/centos-vault/6.8/centosplus/x86_64/
gpgcheck=1
enabled=0
#gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-CentOS-6
gpgkey=https://mirrors.tuna.tsinghua.edu.cn/centos-vault/6.8/os/x86_64/RPM-GPG-KEY-CentOS-6
#contrib - packages by Centos Users
[contrib]
name=CentOS-$releasever - Contrib
#mirrorlist=http://mirrorlist.centos.org/?release=$releasever&arch=$basearch&repo=contrib&infra=$infra
#baseurl=http://mirror.centos.org/centos/$releasever/contrib/$basearch/
baseurl=https://mirrors.tuna.tsinghua.edu.cn/centos-vault/6.8/contrib/x86_64/
gpgcheck=1
enabled=0
#gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-CentOS-6
gpgkey=https://mirrors.tuna.tsinghua.edu.cn/centos-vault/6.8/os/x86_64/RPM-GPG-KEY-CentOS-6
可以直接替换使用。
其实就是把原先的国外镜像网址改成了清华镜像对应的网址。
接下来,就可以安装时间同步插件了:
yum -y install ntpdate
ntpdate -u ntp.api.bz

格式化显示时间
date "+%Y-%m-%d %H:%M:%S"

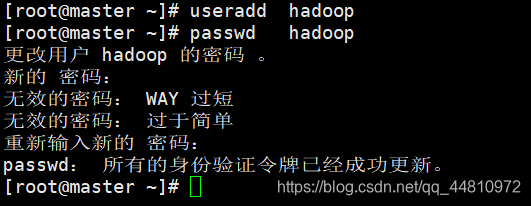
(6)新增一个普通的用户
useradd hadoop
设置用户密码
passwd hadoop
(7)同理,完成slave1和slave2的网络配置。
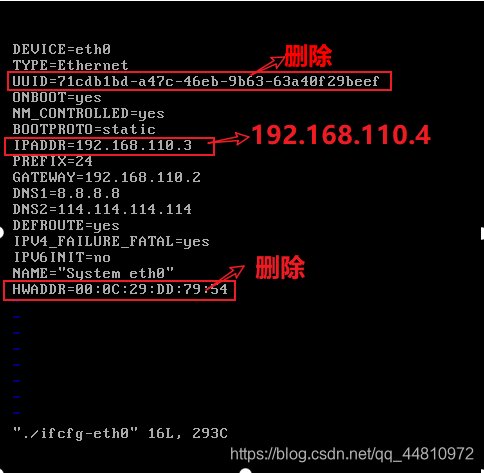
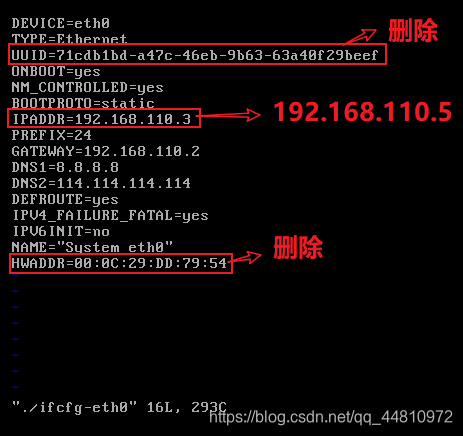
i.修改克隆机(slave1,slave2)的IP地址,在root用户下
删除/etc/sysconfig/network-scripts/ifcfg-eth0 文件中的物理地址
删除两行:UUID和HWADDR
修改IPADDR=IP地址
Slave1:

Slave2:
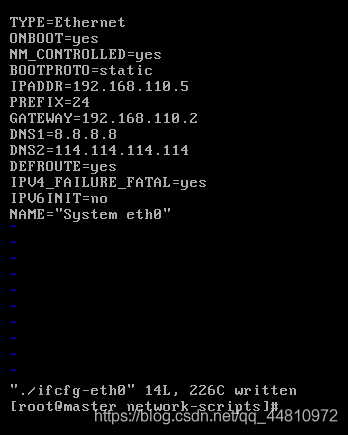
删除文件/etc/udev/rules.d/70-persistent-net.rules
rm -rf /etc/udev/rules.d/70-persistent-net.rules

ii.reboot重启
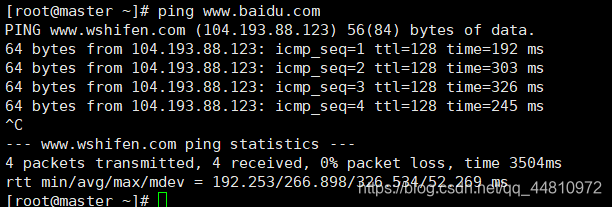
iii.检查网络是否连通
ping www.baidu.com
iv. 在root用户下修改克隆机的hostname
vi /etc/sysconfig/network
把HOSTNAME=master分别修改为HOSTNAME=slave1和slave2


Reboot重启,以使主机名修改生效
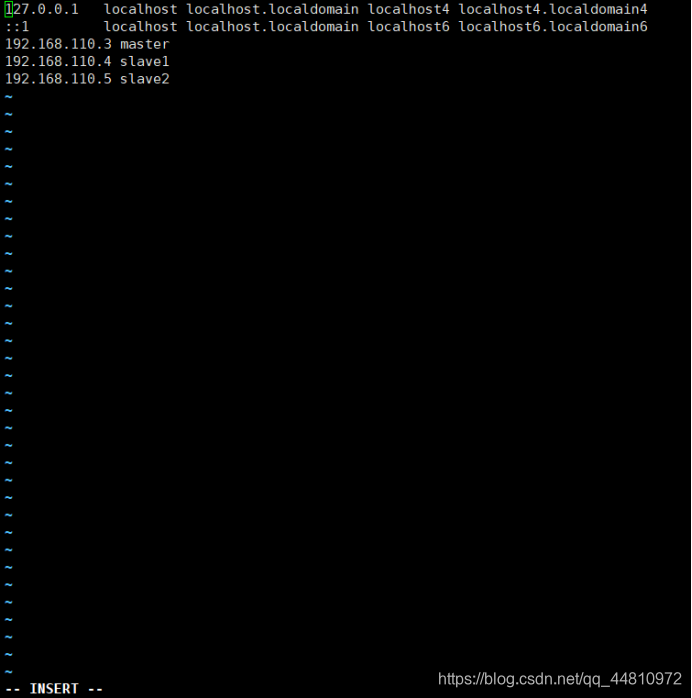
v.以root用户将所有节点(三个虚拟机)hosts文件修改
vi /etc/hosts
192.168.100.110 master
192.168.100.111 slave1
192.168.100.112 slave2
vi.服务器间文件拷贝命令scp
scp 本地文件(目录) 主机名:目标文件(目录)
scp /etc/hosts slave1:/etc/hosts
scp /etc/hosts slave2:/etc/hosts
2、 分布式环境搭建
2.1、权限设置
①Linux临时提升管理员权限(sudo方法)
Root用户下进行修改:
vi /etc/sudoers

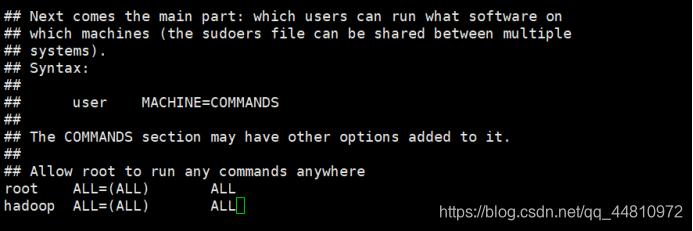
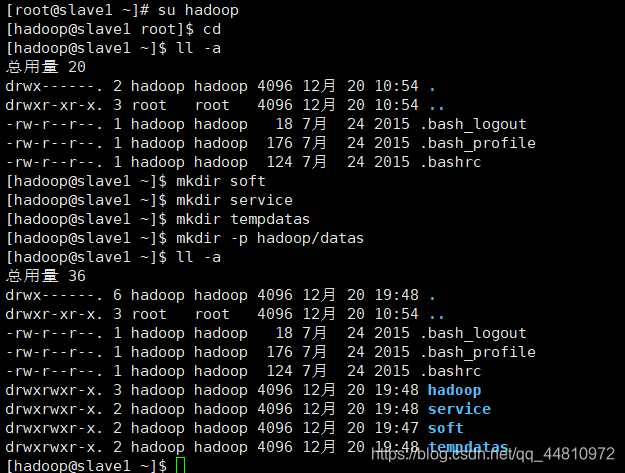
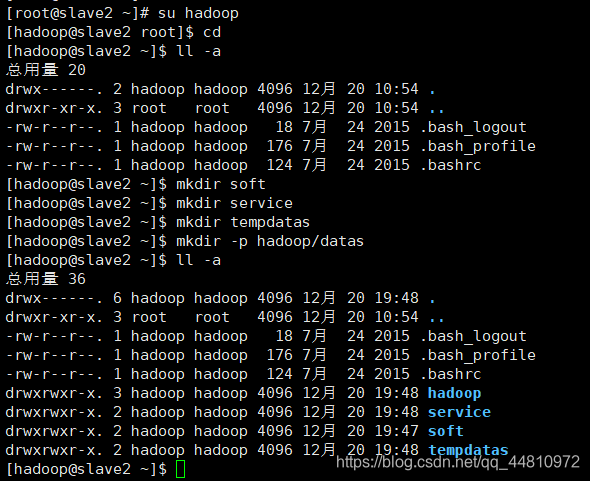
②Hadoop用户下新建目录
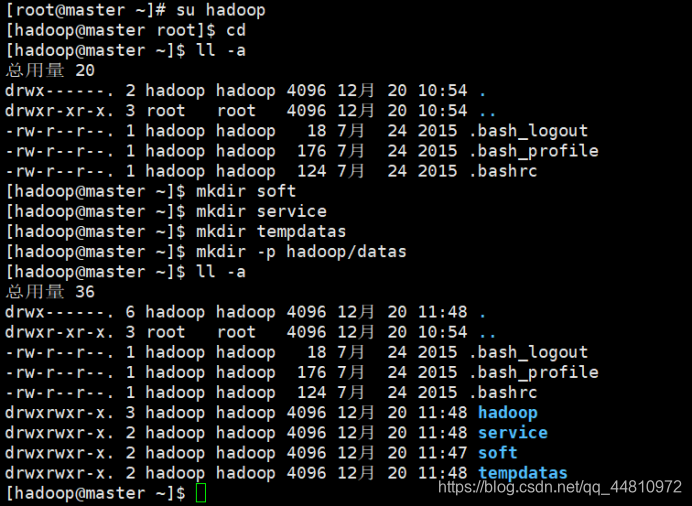
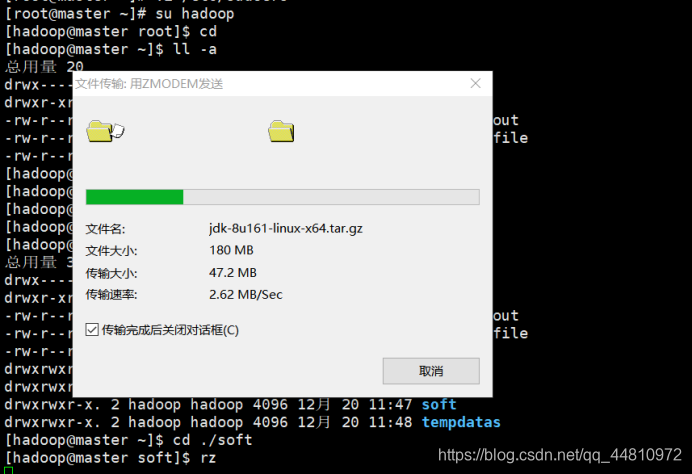
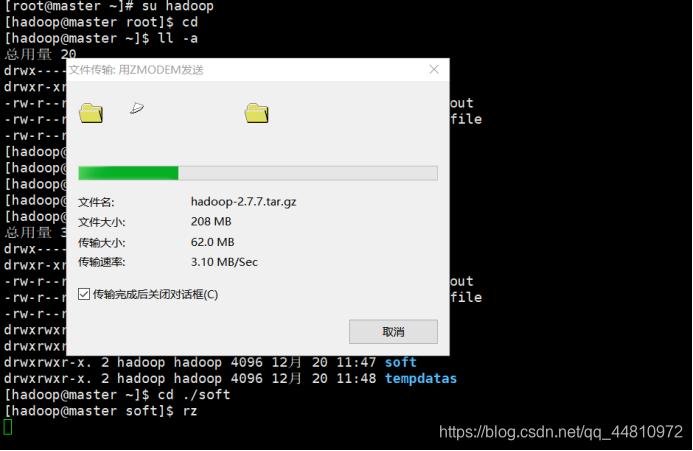
③用xshell客户端,以普通用户身份登录上传架包
④解压jdk
tar -zxvf jdk-8u141-linux-x64.tar.gz
mv jdk1.8.0_161 ~/service/jdk1.8
⑤配置用户bin的加载环境
vi ~/.bash_profile
PATH=$PATH:$HOME/bin
export JAVA_HOME=/home/hadoop/service/jdk1.8/jdk1.8.0_161/
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
PATH=$PATH:${JAVA_HOME}/bin
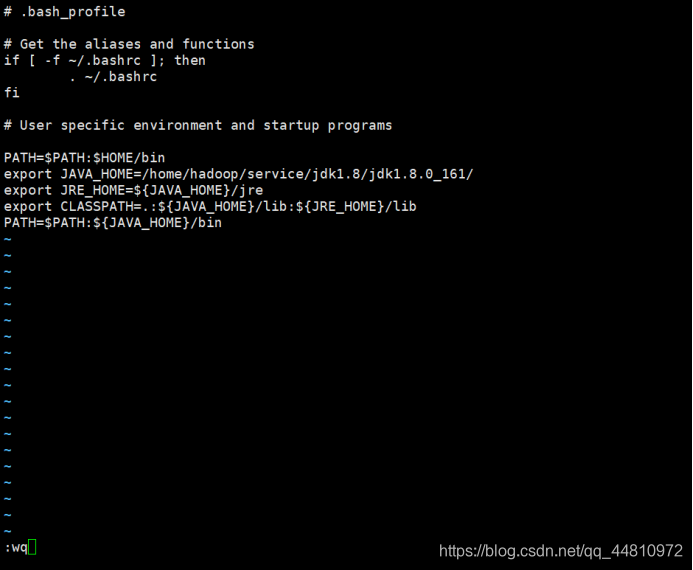
⑥加载修改的配置
source ~/.bash_profile
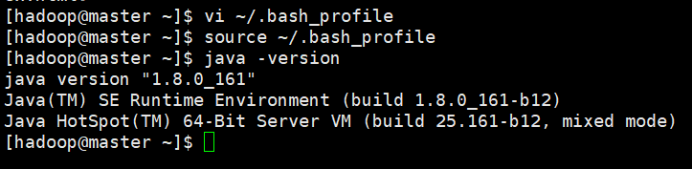
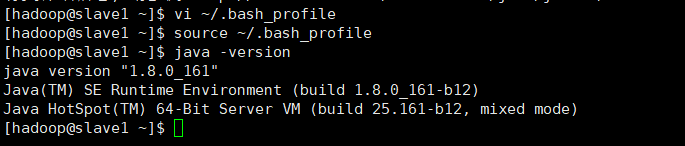
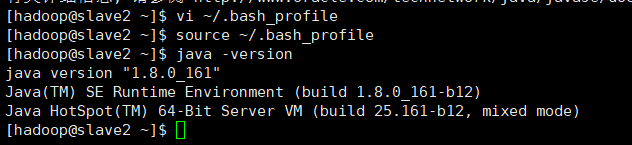
⑦查看是否成功
java –version
⑧完成hadoop2.7压缩包的上传,
⑨解压并重命令hadoop
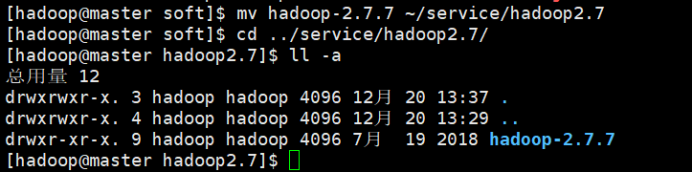
tar -zxvf hadoop-2.7.3.tar.gz -C ~/service/hadoop2.7/

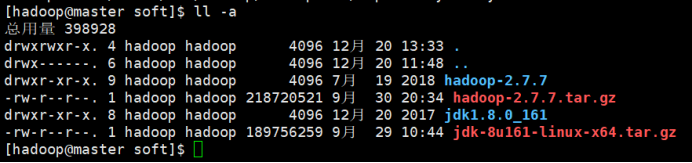
mv hadoop-2.7.3 ./hadoop2.7
2.2 、配置环境变量
①修改环境变量
vi ~/.bash_profile
export JAVA_HOME=/home/hadoop/service/jdk1.8/jdk1.8.0_161/
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=$PATH:${JAVA_HOME}/bin
export HADOOP_HOME=/home/hadoop/service/hadoop2.7/hadoop2.7.7
export PATH=$PATH:${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin
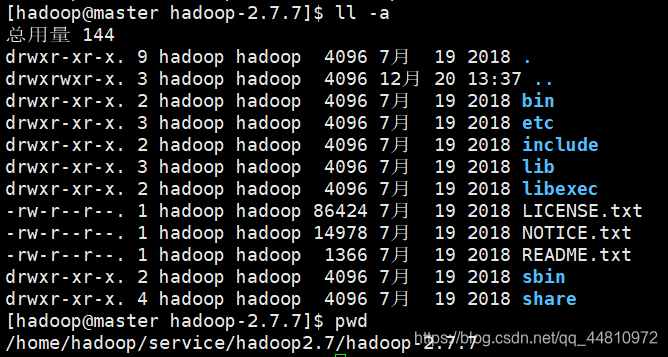

②加载配置
source ~/.bash_profile
Hadoop version

2.3、hadoop文件配置
i.mapred-env.sh
#export JAVA_HOME=/home/y/libexec/jdk1.6.0/
export JAVA_HOME=/home/hadoop/service/jdk1.8/jdk1.8.0_161/
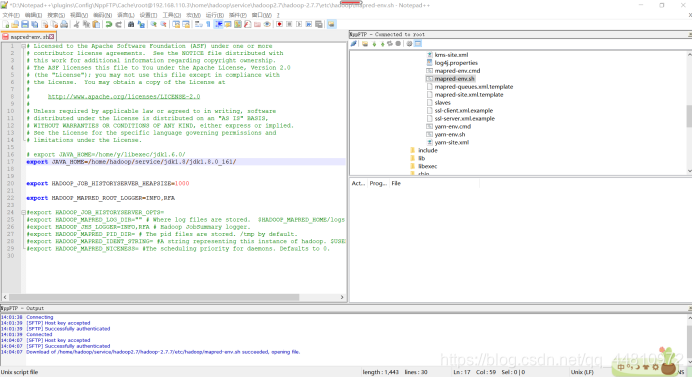
ii.hadoop-env.sh
export JAVA_HOME=${JAVA_HOME}改成自己的真实jdk
export JAVA_HOME=/home/hadoop/service/jdk1.8/jdk1.8.0_161/
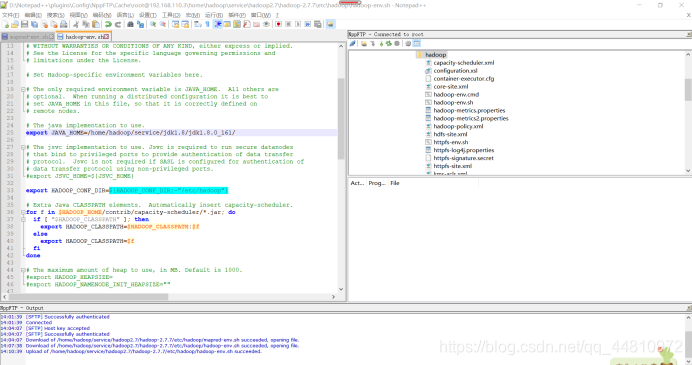
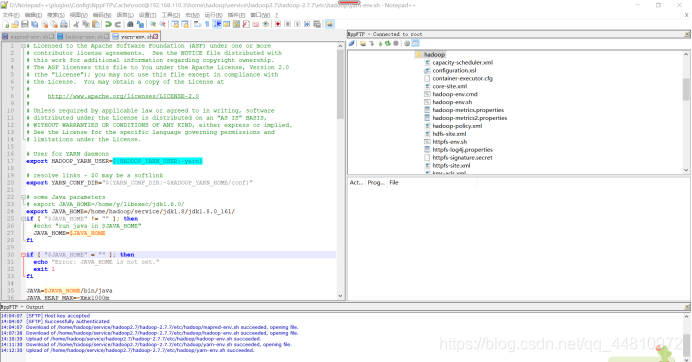
iii.yarn-env.sh,设置jdk路径:
#some Java parameters
#export JAVA_HOME=/home/y/libexec/jdk1.6.0/
export JAVA_HOME=/home/hadoop/service/jdk1.8/jdk1.8.0_161/
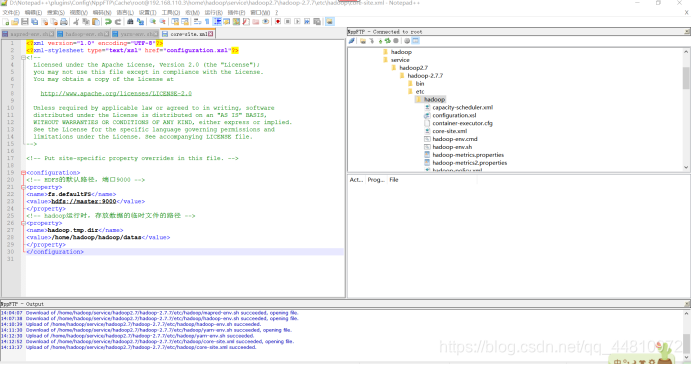
iv.打开core-site.xml
<configuration>
<!-- HDFS的默认路径,端口9000 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<!-- hadoop运行时,存放数据的临时文件的路径 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/hadoop/datas</value>
</property>
</configuration>
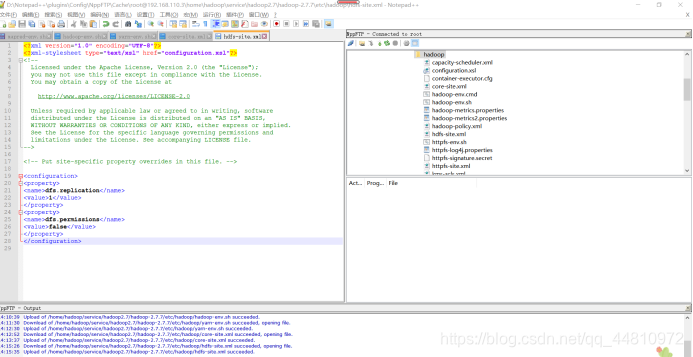
v.hdfs-site.xml:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>
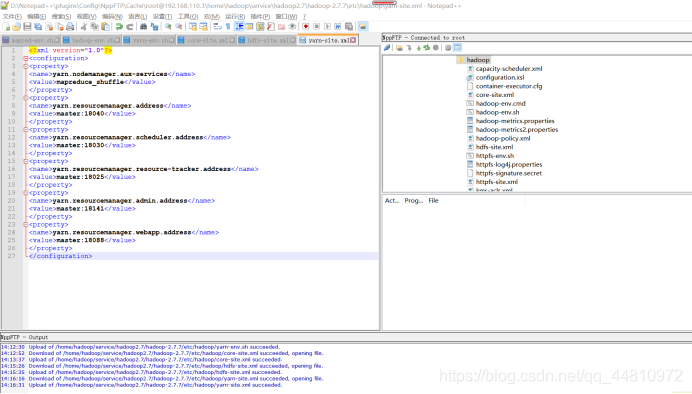
vi.yarn-site.xml:
<?xml version="1.0"?>
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>master:18040</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:18030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:18025</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master:18141</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:18088</value>
</property>
</configuration>
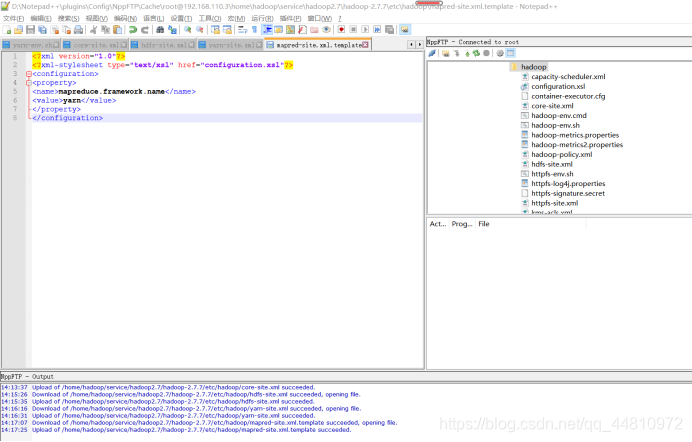
vii.mapred-site.xml.template
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
2.4、ssh服务配置
①为三台虚拟机都设置SSH免密登录,在hadoop用户下
ssh-keygen -t rsa (一些列回车)
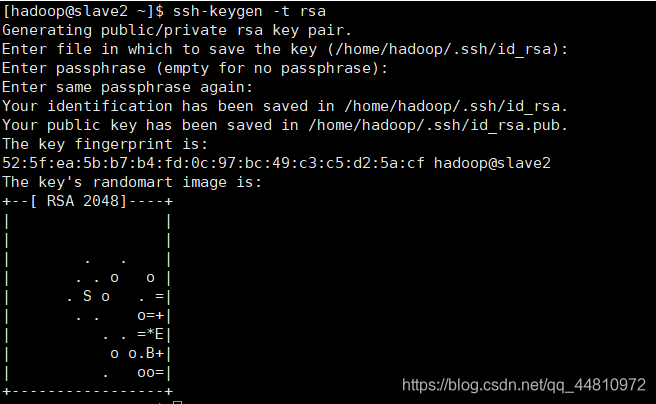
cp ~/.ssh/id_rsa.pub ~/.ssh/authorized_keys

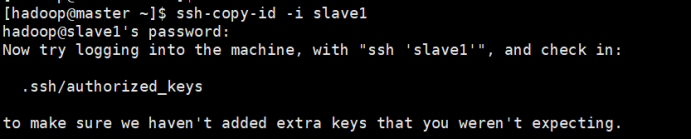
②以自定义角色(hadoop)登录master节点
将~/.ssh/id_rsa.pub的内容提供给slave1和slave2节点,如此当master节点操作slave1、slave2节点时可以免密操作
ssh-copy-id -i slave1

ssh-copy-id -i slave2
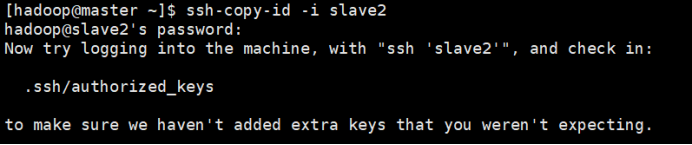

或者
scp ~/.ssh/authorized_keys slave1:~/.ssh/
scp ~/.ssh/authorized_keys slave2:~/.ssh/
③普通用户下(hadoop)修改hadoop的相关配置项
创建 datas
mkdir ~/hadoop/datas
④修改~/service/hadoop2.7/hadoop2.7.7/etc/hadoop/slaves,添加子节点信息
slave1
slave2

⑤完成服务器间文件的拷贝
scp ~/service/hadoop2.7/hadoop2.7.7/etc/hadoop/slaves
slave1: ~/service/hadoop2.7/hadoop2.7.7/etc/hadoop/slaves
scp ~/service/hadoop2.7/hadoop2.7.7/etc/hadoop/slaves
slave2: ~/service/hadoop2.7/hadoop2.7.7/etc/hadoop/slaves
⑥修改hdfs配置
在目录/home/service/hadoop2.7/hadoop2.7.7/etc/hadoop/hdfs-site.xml下
<configuration>
<!-- 数据文件存放的副本数,默认情况是3个 -->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
</configuration>
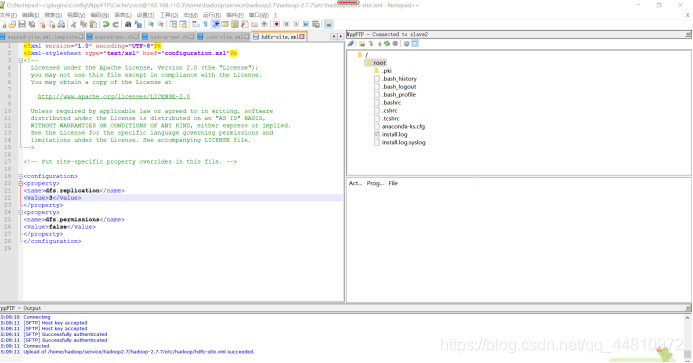
⑦完成hdfs配置修改后,将修改后的文件拷贝到slave1和slave2中
scp~/service/hadoop2.7/hadoop2.7.7/etc/hadoop/slaves
slave1: ~/service/hadoop2.7/hadoop2.7.7/etc/hadoop/slaves
scp ~/service/hadoop2.7/hadoop2.7.7/etc/hadoop/slaves
slave2: ~/service/hadoop2.7/hadoop2.7.7/etc/hadoop/slaves
⑧保证hadoop集群的时间同步
i.root用户下:
yum -y install ntpdate
ntpdate -u ntp.api.bz
ii.格式化显示时间
date "+%Y-%m-%d %H:%M:%S"
3、 启动Hadoop集群
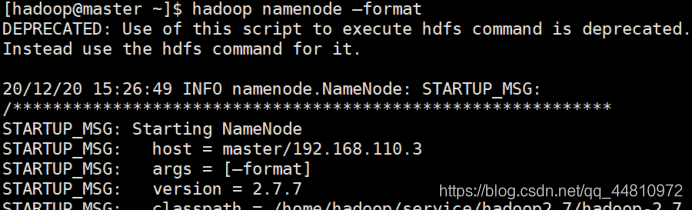
3.1、格式化集群
在master主机中执行命令
hadoop namenode –format
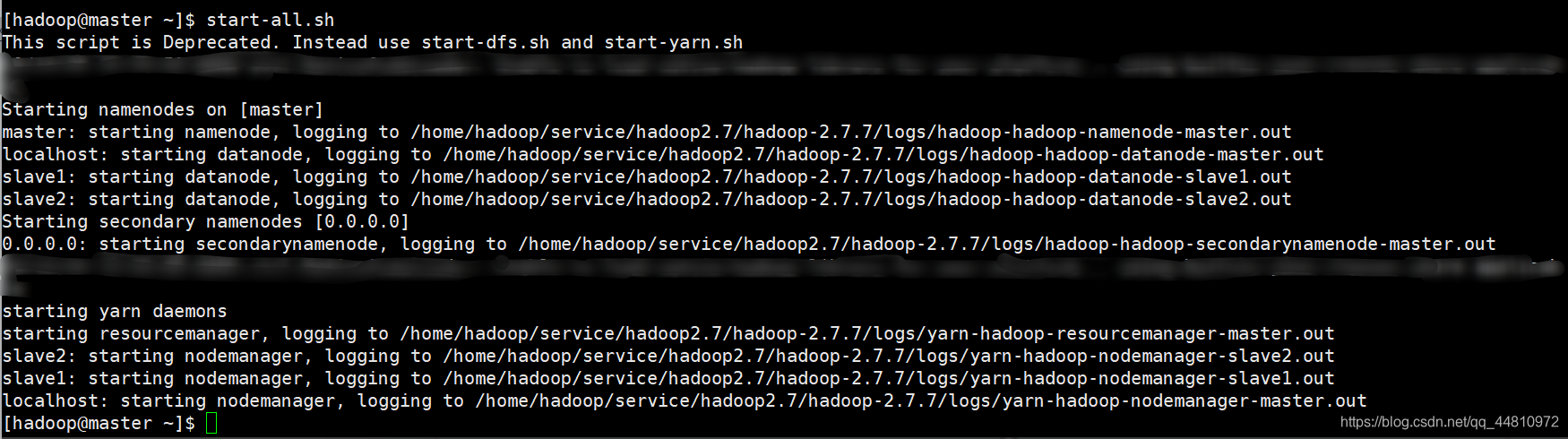
3.2、启动集群
start-all.sh
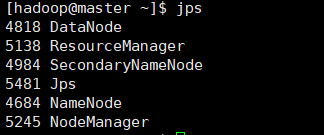
Jps
① master节点:

②Slave1从节点:
③ Slave2从节点:
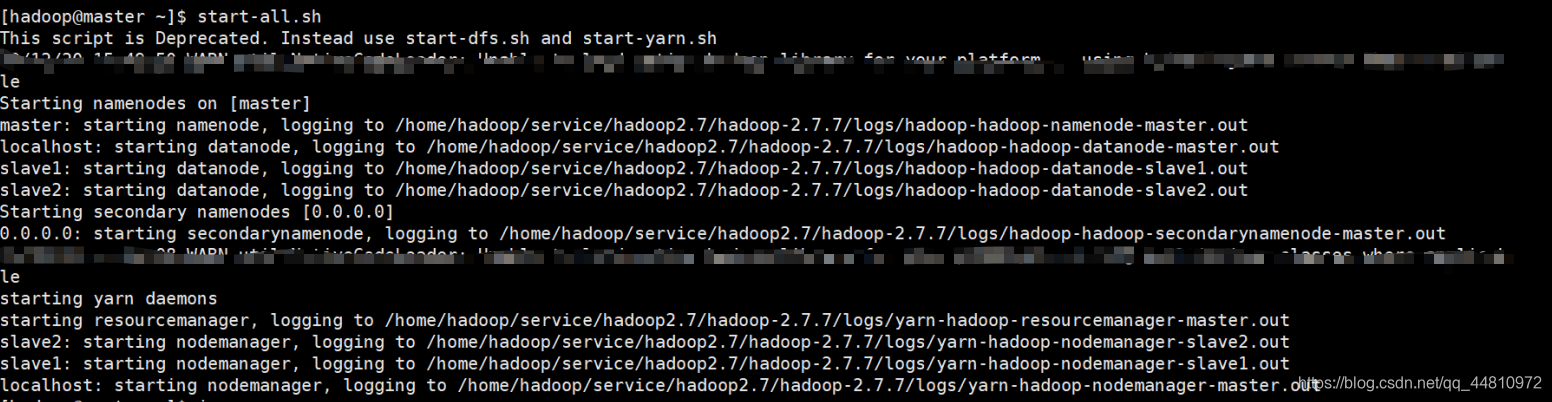
④Jps命令:
我这里是少了一个nameNode结点,原因是多次格式化造成的!
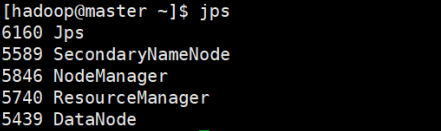
tips:
解决多次格式化集群造成的问题,可以按照下面步骤来:
1、停集群
2、清空各个节点配置的hadoop tmp目录、name目录、data目录、以及hadoop logs目录
3、最后可以格式化namenode
$ hadoop namenode -format
接着在start-all启动整个集群就ok了,可以看到有6个进程在运行了,nameNode也开起了;
码字不易,喜欢的话,不要忘了三连一波!!!
后面会不定期更新博客。
欢迎一起学习交流!