超详细版本的Linux从零搭建Hadoop集群(CentOS7+hadoop 3.2.0+JDK1.8+Mapreduce完全分布式集群案例+详细源码图文讲解)
关键字和相关配置版本
关键字:Linux CentOS Hadoop Java
版本: CentOS7 Hadoop3.2.0 JDK1.8
虚拟机参数信息内存3.2G、处理器2x2、内存50G
ISO:CentOS-7-x86_64-DVD-2009.iso
基本主从思路:
先把基础的设置(SSH、JDK、Hadooop、环境变量、Hadoop和MapReduce配置信息)在一台虚拟机(master)上配好,通过克隆修改节点IP、主机名、添加主从ip与对应的主机名,获得剩下一台虚拟机(node1)!
此次搭建的集群的一台主机,一台从机的主从结构。
(可以根据自己的实际情况设置多台从机,本文内容我这个从机是一个,多加几个节点也很简单,看个人爱好或者个人需求。)
说明:Hadoop从版本2开始加入了Yarn这个资源管理器,Yarn并不需要单独安装。只要在机器上安装了JDK就可以直接安装Hadoop,单纯安装Hadoop并不依赖Zookeeper之类的其他东西。
文章目录
一、首先要先在虚拟机搭建Linux CentOS7
不懂如何搭建的小伙伴可以在看我之前写的博客:
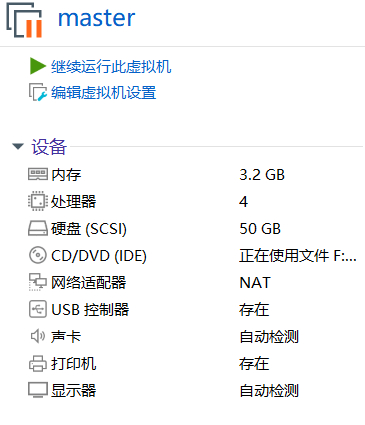
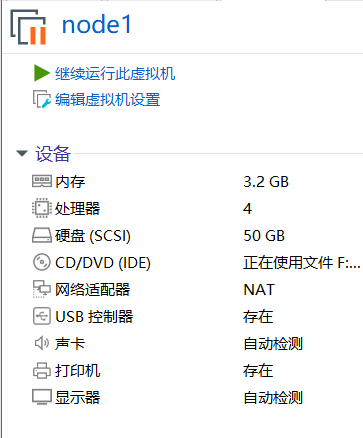
我配置好的master和node1节点的虚拟机内存和处理器等参数信息如下。
二、直接选择root用户登录并关闭防火墙
(根据个人需求可选可不选,我选择root直接登录更简单省事)
我直接选择root用户登录,避免了普通用户授权和切换用户导致的一些环境问题,简单来说就是高效、方便。
这样的好处就是进来直接就是root用户,不用再那么麻烦输入密码授权认证啥的:
然后我们先关闭防火墙:
systemctl stop firewalld //关闭防火墙
systemctl disable firewalld //关闭开机自启
systemctl status firewalld //查看防火墙状态
systemctl status firewalld
//查看防火墙状态
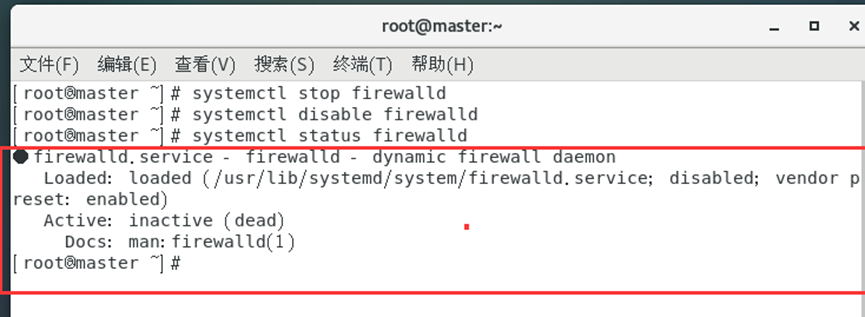
当防火墙处于关闭状态时候我们继续往下进行。
三、实现ssh免密码登录
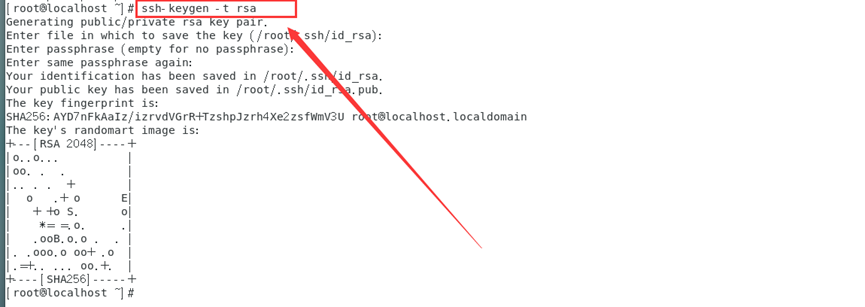
配置ssh的无密码访问
ssh-keygen -t rsa
连续按回车
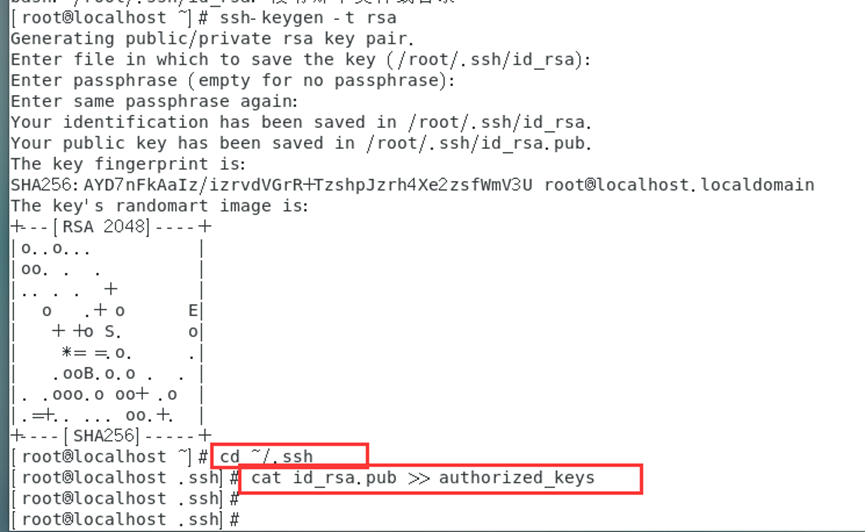
cd ~/.ssh
cat id_rsa.pub >> authorized_keys
让ssh服务器自动启动
vi ~/.bashrc
在文件的最末尾按O进入编辑模式,加上:
/etc/init.d/ssh start
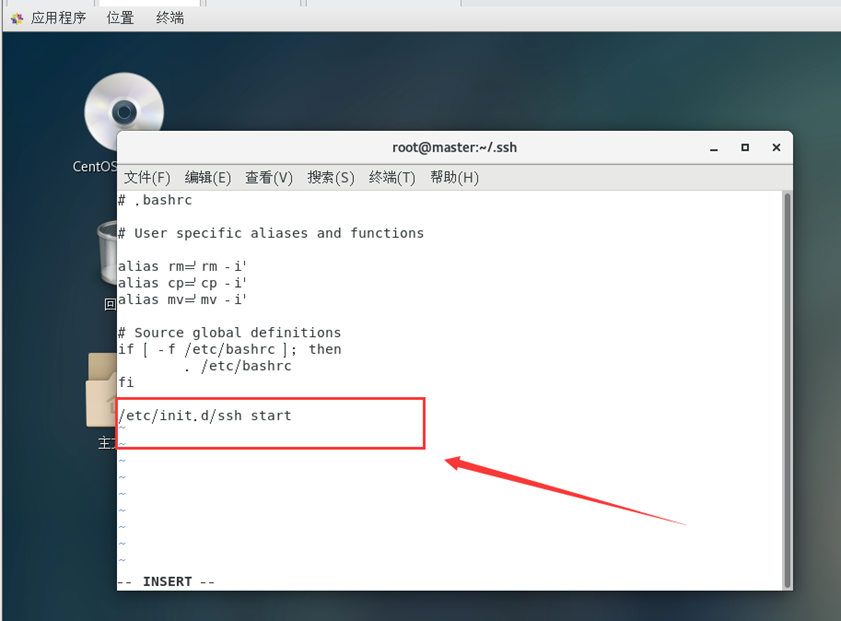
按ESC返回命令模式,输入:wq保存并退出。
让修改即刻生效
source ~/.bashrc

四、CentOS7 安装jdk1.8
1、yum安装
- 安装之前先查看一下有无系统自带jdk,有的话先卸载。
rpm -qa | grep jdk
[root@master ~]#rpm -qa | grep jdk
copy-jdk-configs-3.3-10.el7_5.noarch
java-1.8.0-openjdk-headless-1.8.0.322.b06-1.el7_9.x86_64
java-1.8.0-openjdk-devel-1.8.0.322.b06-1.el7_9.x86_64
java-1.8.0-openjdk-javadoc-zip-1.8.0.322.b06-1.el7_9.noarch
java-1.8.0-openjdk-1.8.0.322.b06-1.el7_9.x86_64
java-1.8.0-openjdk-accessibility-1.8.0.322.b06-1.el7_9.x86_64
java-1.8.0-openjdk-demo-1.8.0.322.b06-1.el7_9.x86_64
java-1.8.0-openjdk-src-1.8.0.322.b06-1.el7_9.x86_64
java-1.8.0-openjdk-javadoc-1.8.0.322.b06-1.el7_9.noarch
卸载jdk:
rpm -e --nodeps 上步查询出的所有jdk
例如:
[root@master ~]# rpm -e --nodeps copy-jdk-configs-3.3-10.el7_5.noarch
[root@master ~]# rpm -e --nodeps java-1.8.0-openjdk-headless-1.8.0.322.b06-1.el7_9.x86_64
[root@master ~]# rpm -qa | grep jdk
java-1.8.0-openjdk-devel-1.8.0.322.b06-1.el7_9.x86_64
java-1.8.0-openjdk-javadoc-zip-1.8.0.322.b06-1.el7_9.noarch
java-1.8.0-openjdk-1.8.0.322.b06-1.el7_9.x86_64
java-1.8.0-openjdk-accessibility-1.8.0.322.b06-1.el7_9.x86_64
java-1.8.0-openjdk-demo-1.8.0.322.b06-1.el7_9.x86_64
java-1.8.0-openjdk-src-1.8.0.322.b06-1.el7_9.x86_64
java-1.8.0-openjdk-javadoc-1.8.0.322.b06-1.el7_9.noarch
[root@test ~]#
rpm -e --nodeps 我这只执行了两次,剩下的7个卸载同样的操作,在此不在执行。
验证是否已经卸载干净:
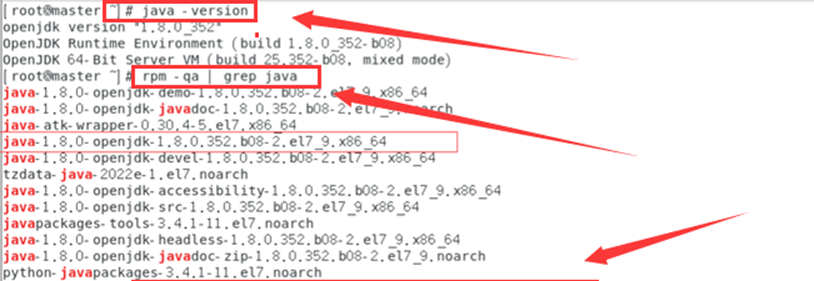
rpm -qa|grep java
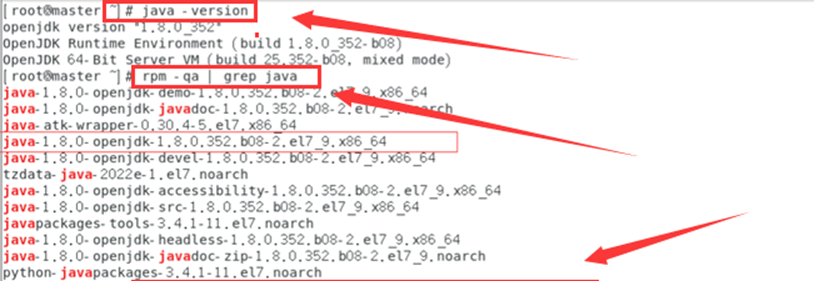
java -version

卸载完之后开始安装jdk1.8:
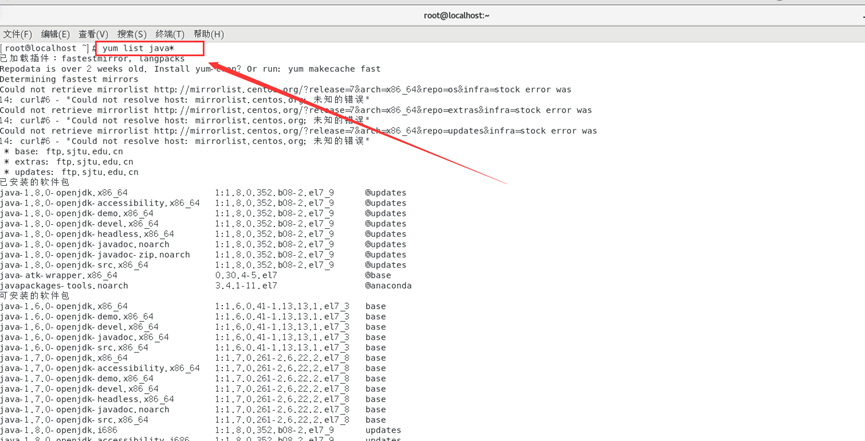
查看可安装的版本
yum list java*
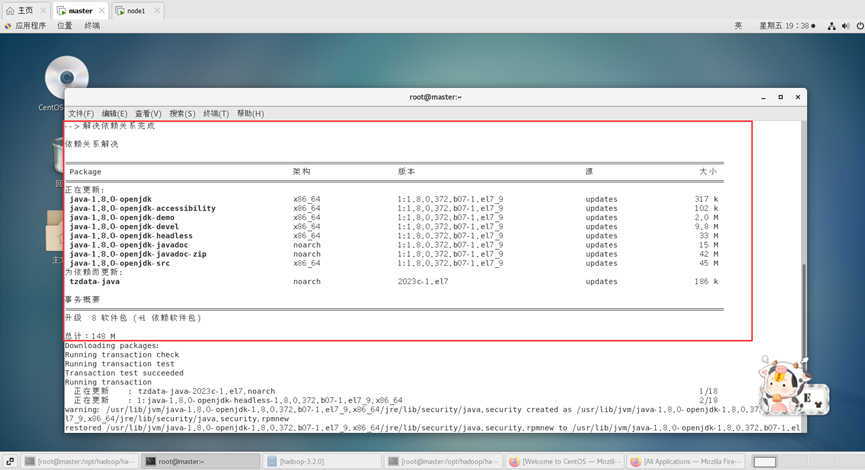
安装1.8.0版本openjdk
yum -y install java-1.8.0-openjdk*
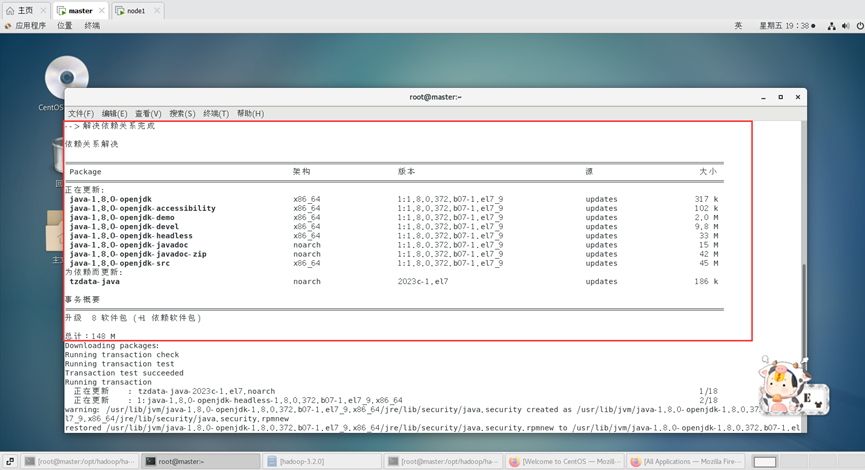
安装位置查看:
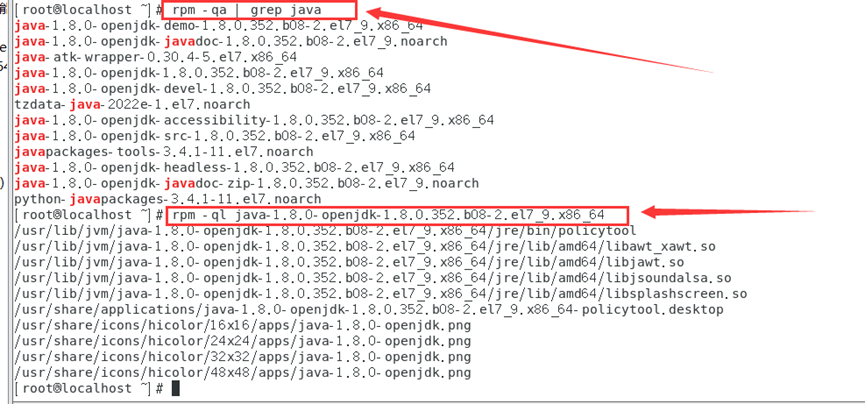
rpm -qa | grep java
rpm -ql java-1.8.0-openjdk-1.8.0.352.b08-2.el7_9.x86_64
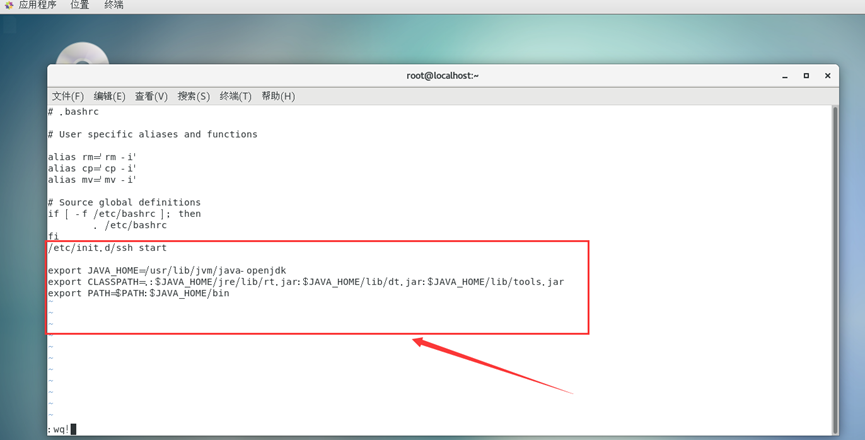
环境变量配置:
当前用户使用:
vi ~/.bashrc
或者全局用户使用:
vi /etc/profile
添加:
export JAVA_HOME=/usr/lib/jvm/java-openjdk
export CLASSPATH=.:$JAVA_HOME/jre/lib/rt.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$PATH:$JAVA_HOME/bin
然后执行
source ~/.bashrc
或者
source /etc/profile
命令使修改的配置文件生效。
验证安装:
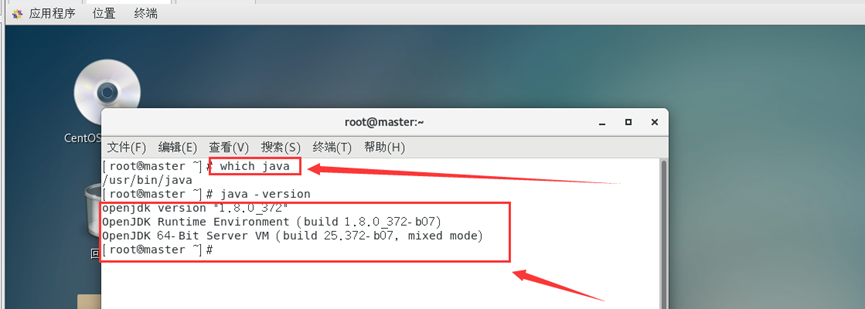
which java
java -version
五、下载hadoop
这里我使用的hadoop是3.2.0版本
打开下载地址选择页面:http://www.apache.org/dyn/closer.cgi/hadoop/common/hadoop-3.2.0/hadoop-3.2.0.tar.gz
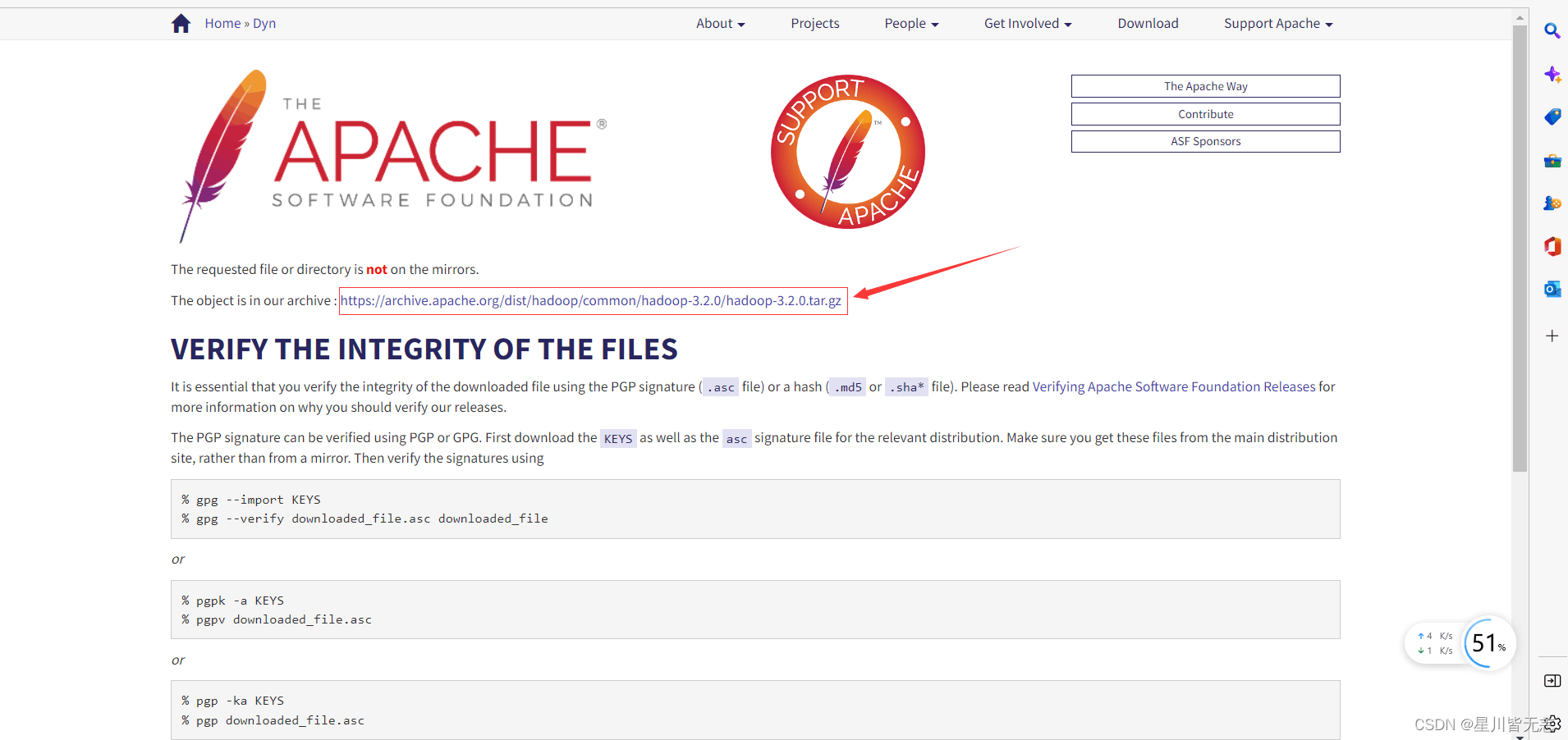
这个链接也有更多3.2.0版本其它的hadoop文件:https://archive.apache.org/dist/hadoop/common/hadoop-3.2.0/
下载hadoop文件:
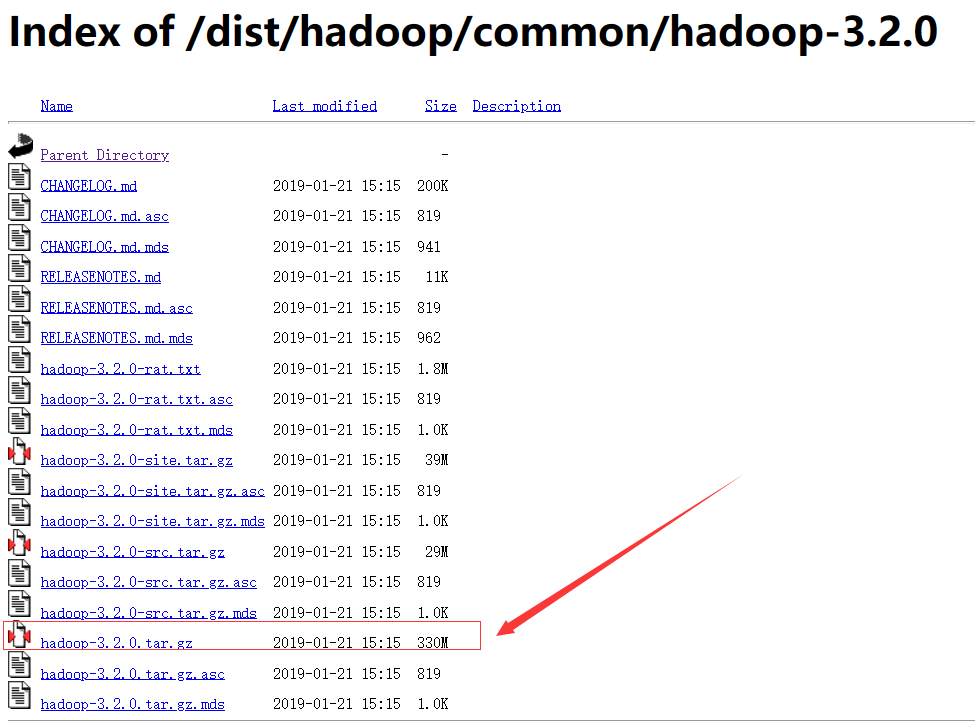
可以根据个人需求,选择自己想要的hadoop版本号文件直接去下载:
附网址:
https://archive.apache.org/dist/hadoop/common/
然后上传文件并解压缩
1.在opt目录下新建一个名为hadoop的目录,并将下载得到的hadoop-3.2.0.tar上载到该目录下
mkdir /opt/hadoop

解压安装:
tar -zxvf hadoop-3.2.0.tar.gz
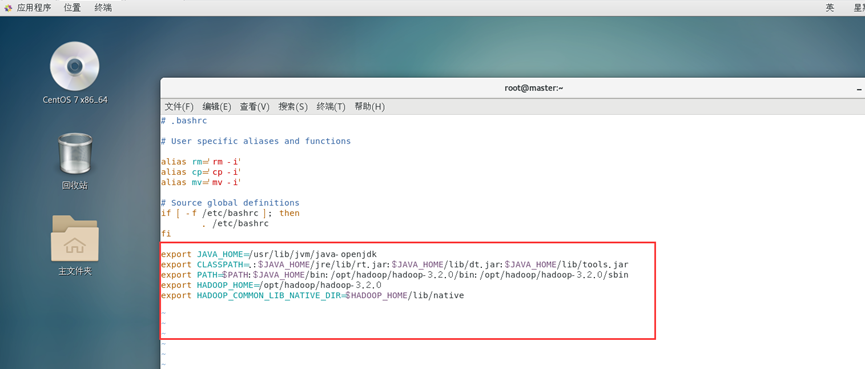
配置Hadoop环境变量:
vim ~/.bashrc

添加hadoop环境变量:
export JAVA_HOME=/usr/lib/jvm/java-openjdk
export CLASSPATH=.:$JAVA_HOME/jre/lib/rt.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$PATH:$JAVA_HOME/bin:/opt/hadoop/hadoop-3.2.0/bin:/opt/hadoop/hadoop-3.2.0/sbin
export HADOOP_HOME=/opt/hadoop/hadoop-3.2.0
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
注意:这里的$PATH:$JAVA_HOME/bin:/opt/hadoop/hadoop-3.2.0/bin:/opt/hadoop/hadoop-3.2.0/sbin表示在保留原来的$PATH环境变量的基础上,再增加$JAVA_HOME/bin和/opt/hadoop/hadoop-3.2.0/bin和/opt/hadoop/hadoop-3.2.0/sbin这些路径作为新的$PATH环境变量。
然后我们执行
source ~/.bashrc
使修改的配置文件生效。
六、Hadoop配置文件修改
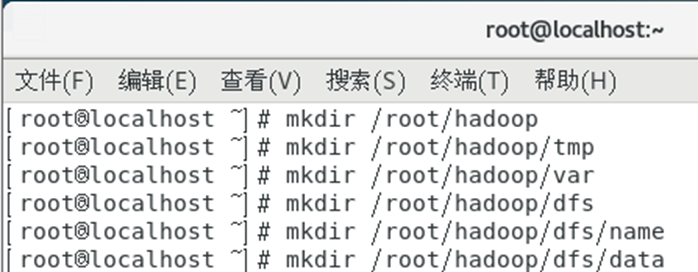
新建几个目录:
mkdir /root/hadoop
mkdir /root/hadoop/tmp
mkdir /root/hadoop/var
mkdir /root/hadoop/dfs
mkdir /root/hadoop/dfs/name
mkdir /root/hadoop/dfs/data
修改etc/hadoop中的一系列配置文件
vi /opt/hadoop/hadoop-3.2.0/etc/hadoop/core-site.xml
在节点内加入配置:
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>/root/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.default.name</name>
<value>hdfs://master:9000</value>
</property>
</configuration>

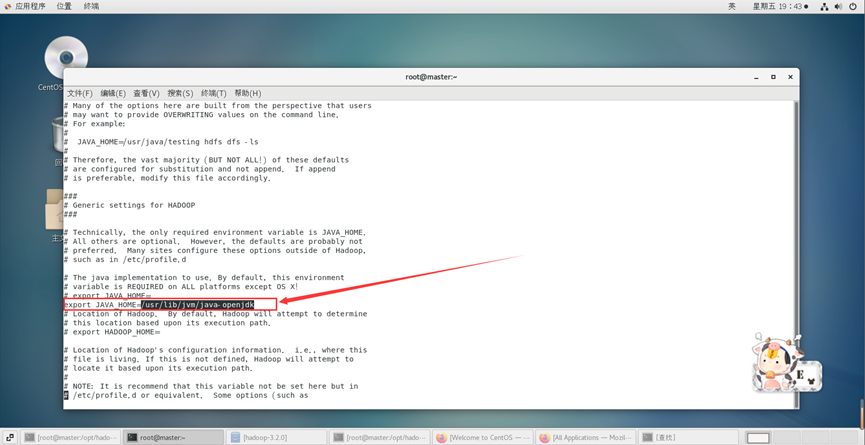
修改hadoop-env.sh
vi /opt/hadoop/hadoop-3.2.0/etc/hadoop/hadoop-env.sh
将 export JAVA_HOME=${JAVA_HOME}
修改为: export JAVA_HOME=/usr/lib/jvm/java-openjdk
说明:修改为自己的JDK路径
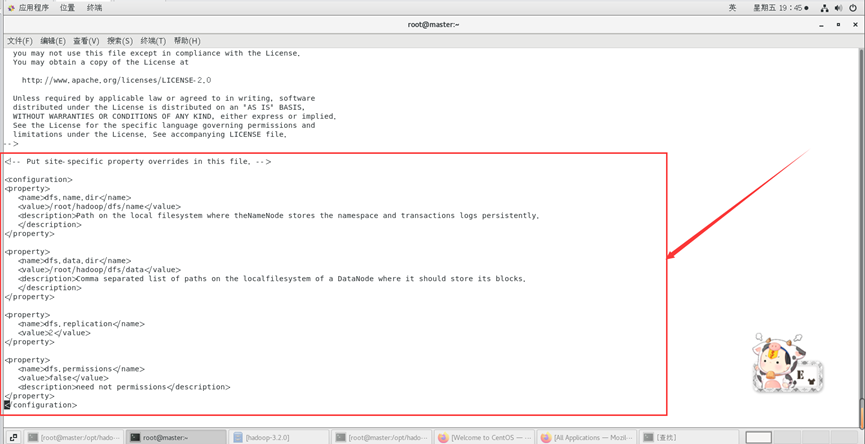
修改hdfs-site.xml
vi /opt/hadoop/hadoop-3.2.0/etc/hadoop/hdfs-site.xml
在节点内加入配置:
<configuration>
<property>
<name>dfs.name.dir</name>
<value>/root/hadoop/dfs/name</value>
<description>Path on the local filesystem where theNameNode stores the namespace and transactions logs persistently.
</description>
</property>
<property>
<name>dfs.data.dir</name>
<value>/root/hadoop/dfs/data</value>
<description>Comma separated list of paths on the localfilesystem of a DataNode where it should store its blocks.
</description>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
<description>need not permissions</description>
</property>
</configuration>
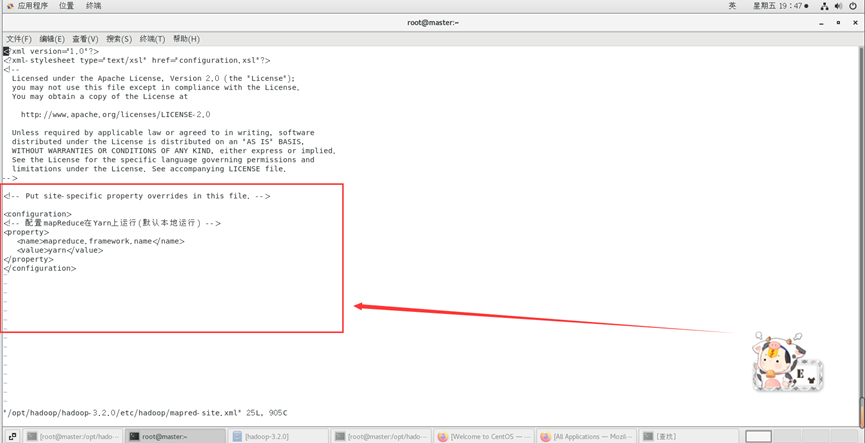
新建并且修改mapred-site.xml:
vi /opt/hadoop/hadoop-3.2.0/etc/hadoop/mapred-site.xml
在节点内加入配置:
<configuration>
<!-- 配置mapReduce在Yarn上运行(默认本地运行) -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
修改workers文件:
vi /opt/hadoop/hadoop-3.2.0/etc/hadoop/workers
将里面的localhost删除,添加以下内容(master和node1节点都要修改):
master
node1

注意:这里面不能有多余空格,文件中不允许有空行。
也可以修改好master节点的/opt/hadoop/hadoop-3.2.0/etc/hadoop/workers文件,然后一条命令直接分发给集群,这样就不用再修改其它节点的workers文件:
xsync /opt/hadoop/hadoop-3.2.0/etc
修改yarn-site.xml文件:
HADOOP_CLASSPATH 是设置要运行的类的路径。否则当你用hadoop classname [args]方式运行程序时会报错,说找不到要运行的类。用hadoop jar jar_name.jar classname [args]方式运行程序时没问题
这边需要设置hadoop classpath否则后面mapreduce会报错找不到主类:
hadoop classpath
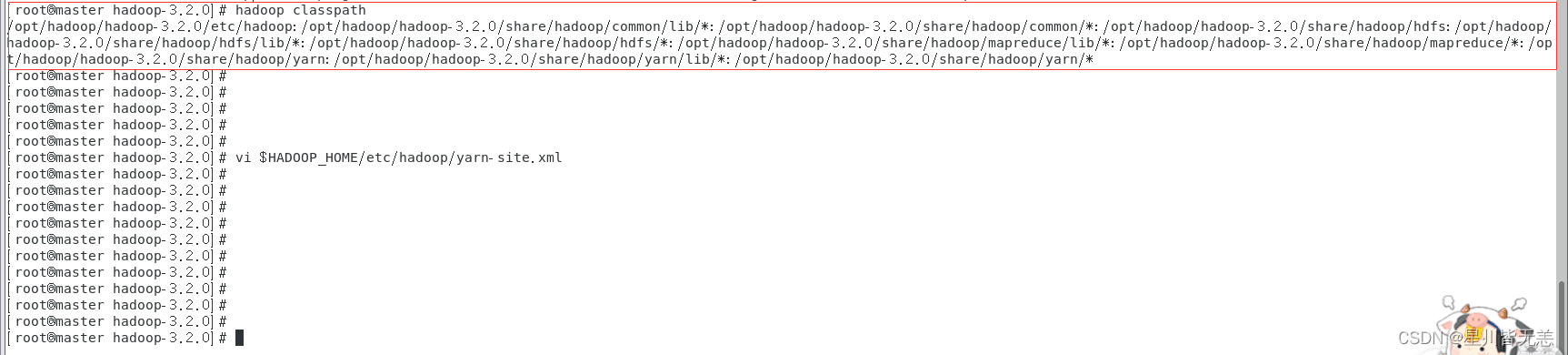
记下返回的结果
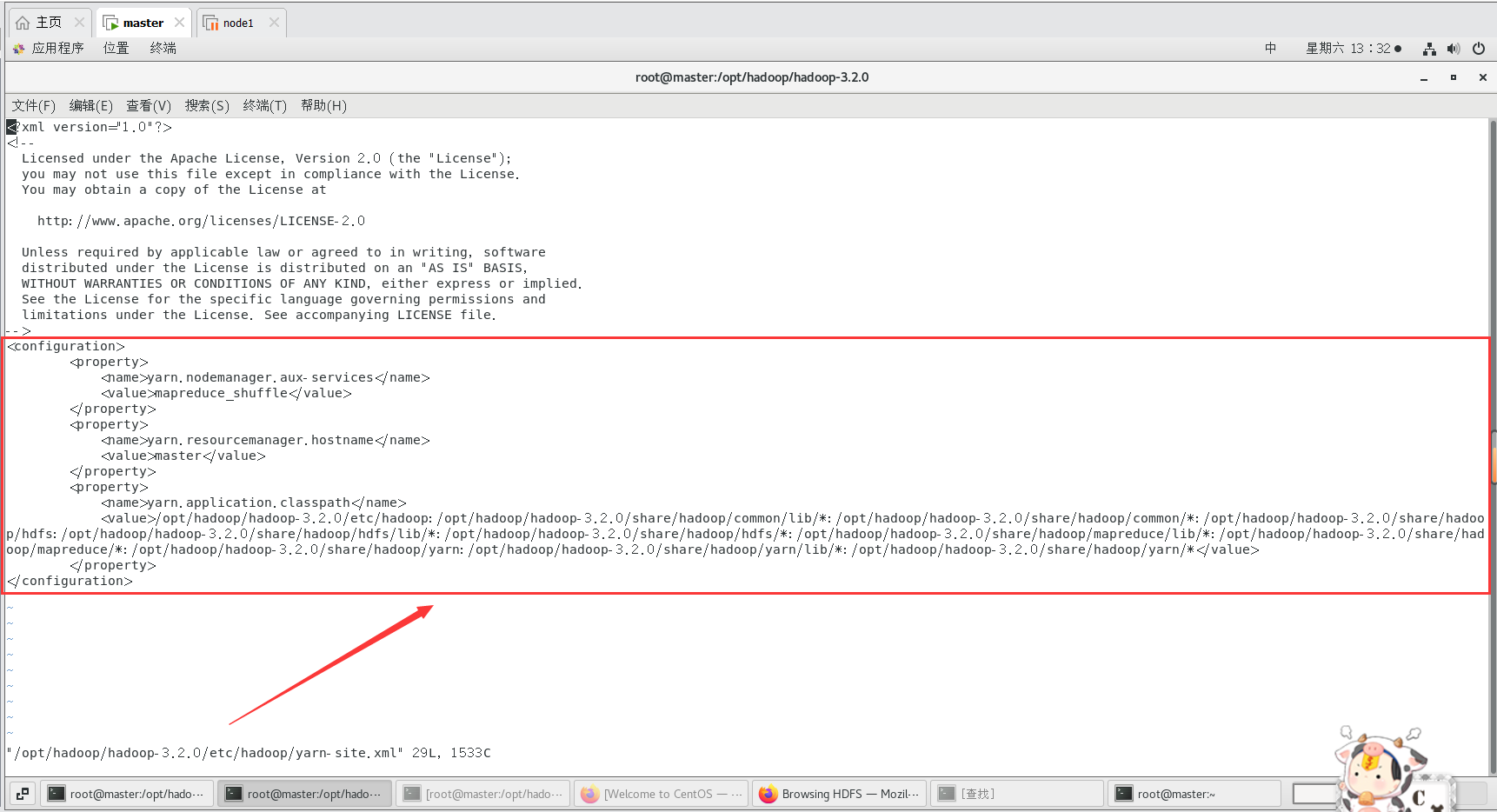
vi /opt/hadoop/hadoop-3.2.0/etc/hadoop/yarn-site.xml
添加一个配置
<property>
<name>yarn.application.classpath</name>
<value>hadoop classpath返回信息</value>
</property>
这是我的yarn-site.xml配置:
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<property>
<name>yarn.application.classpath</name>
<value>/opt/hadoop/hadoop-3.2.0/etc/hadoop:/opt/hadoop/hadoop-3.2.0/share/hadoop/common/lib/*:/opt/hadoop/hadoop-3.2.0/share/hadoop/common/*:/opt/hadoop/hadoop-3.2.0/share/hadoop/hdfs:/opt/hadoop/hadoop-3.2.0/share/hadoop/hdfs/lib/*:/opt/hadoop/hadoop-3.2.0/share/hadoop/hdfs/*:/opt/hadoop/hadoop-3.2.0/share/hadoop/mapreduce/lib/*:/opt/hadoop/hadoop-3.2.0/share/hadoop/mapreduce/*:/opt/hadoop/hadoop-3.2.0/share/hadoop/yarn:/opt/hadoop/hadoop-3.2.0/share/hadoop/yarn/lib/*:/opt/hadoop/hadoop-3.2.0/share/hadoop/yarn/*</value>
</property>
</configuration>
配置hadoop-3.2.0/sbin/目录下start-dfs.sh、start-yarn.sh、stop-dfs.sh、stop-yarn.sh文件
服务启动权限配置
cd /opt/hadoop/hadoop-3.2.0
配置start-dfs.sh与stop-dfs.sh文件
vi sbin/start-dfs.sh
和
vi sbin/stop-dfs.sh
加入下面内容
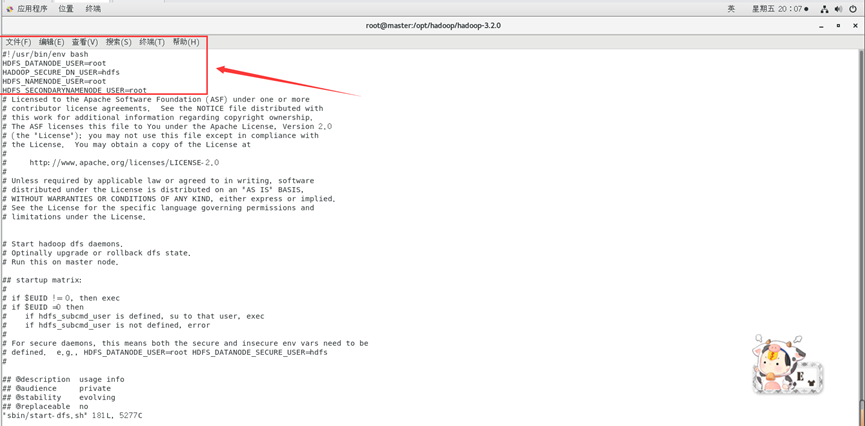
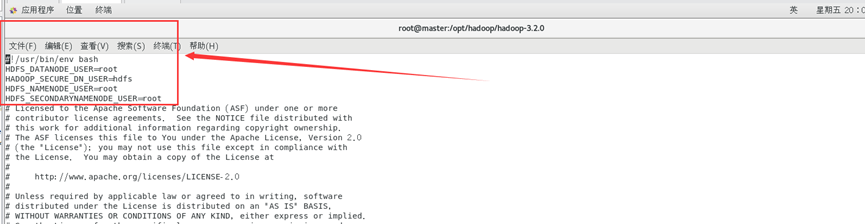
HDFS_DATANODE_USER=root
HADOOP_SECURE_DN_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
配置start-yarn.sh与stop-yarn.sh文件
vi sbin/start-yarn.sh
和
vi sbin/stop-yarn.sh
加入下面内容
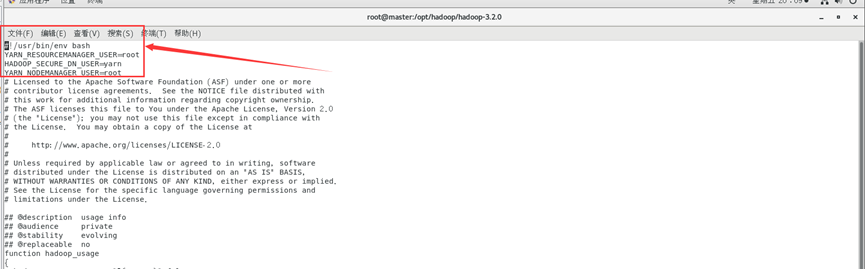
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root

配置好基础设置(SSH、JDK、Hadooop、环境变量、Hadoop和MapReduce配置信息)后,克隆虚拟机,获得从机node1节点。
如果已经复制master为node1节点虚拟机了,但是node1节点的Hadoop配置文件信息还没修改,那么我们直接可以在master节点中运行下面这条命令,将已经配置好的Hadoop配置信息分发给集群各节点,这样我们就不用再修改其它节点的Hadoop配置文件了:
xsync /opt/hadoop/hadoop-3.2.0/etc/hadoop
克隆master主机后,获得从机node1节点。
然后开始修改网卡信息:
vim /etc/sysconfig/network-scripts/ifcfg-ens33
修改node1节点ip信息:
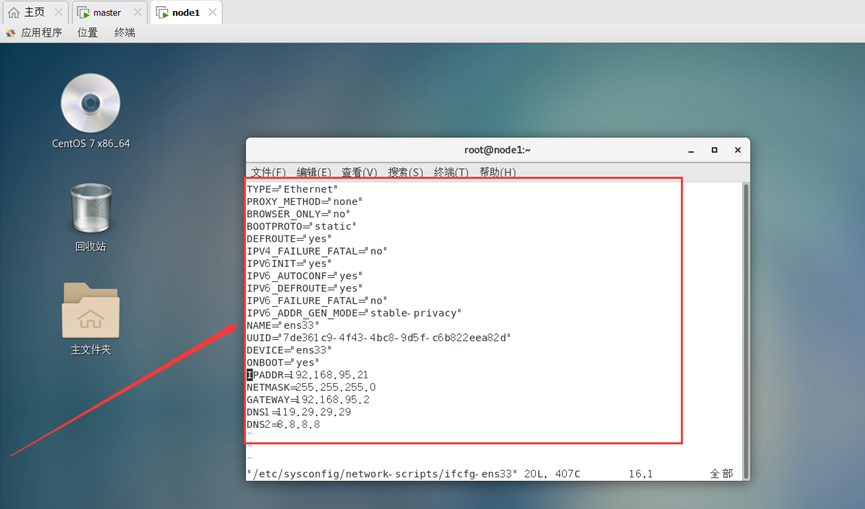
修改node1节点主机名:
vi /etc/hostname
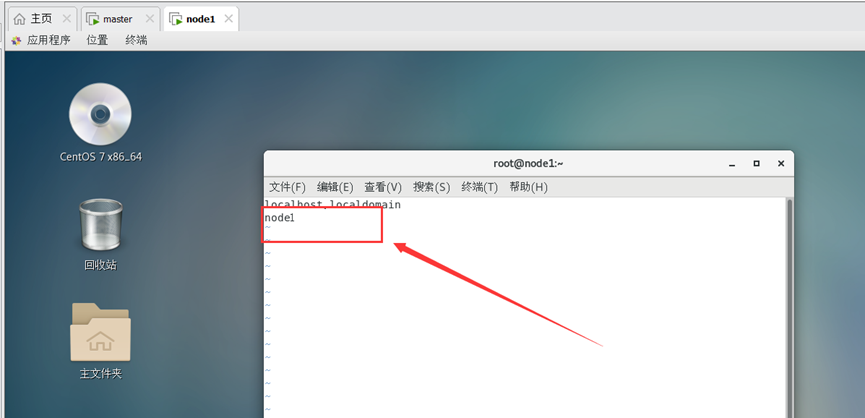
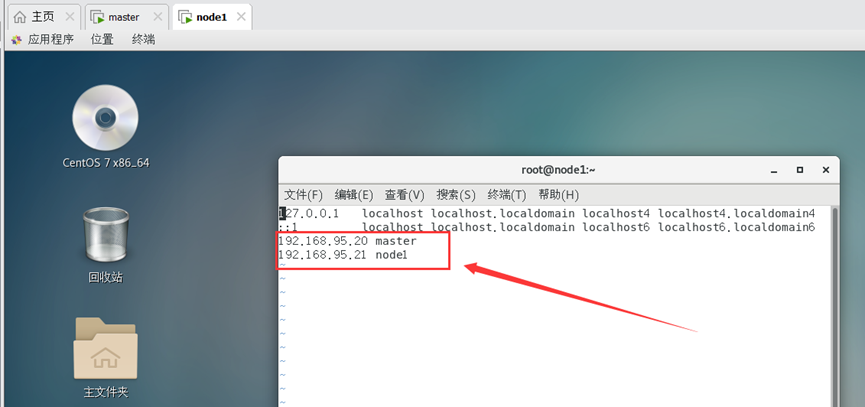
修改node1节点对应的ip 和主机名(主从节点保持一致)
vim /etc/hosts
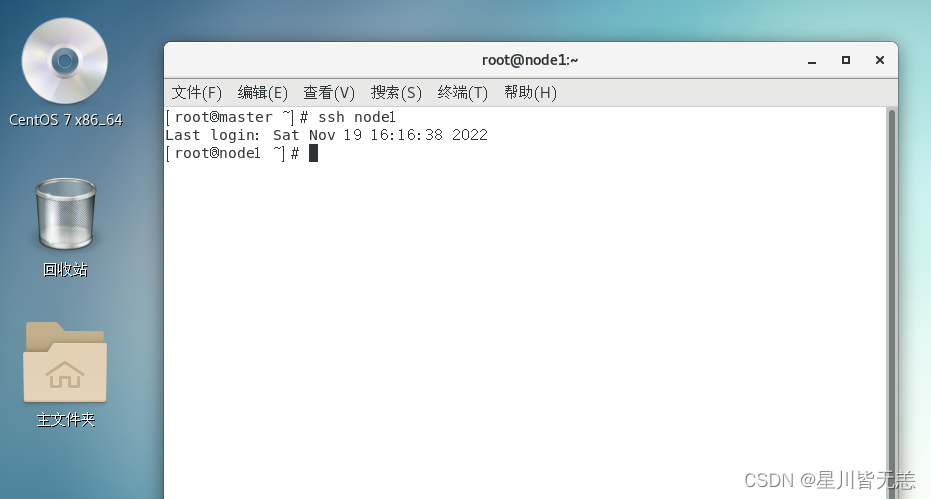
主从节点互连ssh试试:
先试试master节点连接node1节点
ssh node1
再试试node1节点连接master节点:
ssh master
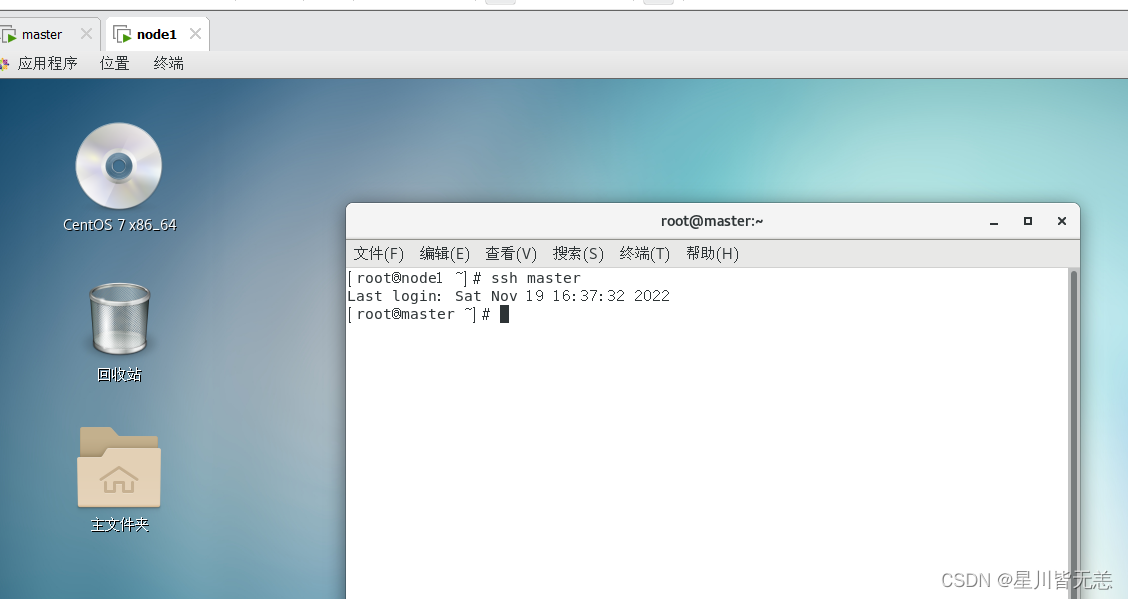
OK,互连成功。(按exit可以退出)
七、启动Hadoop
因为master是namenode,node1是datanode,所以只需要对master进行初始化操作,也就是对hdfs进行格式化。
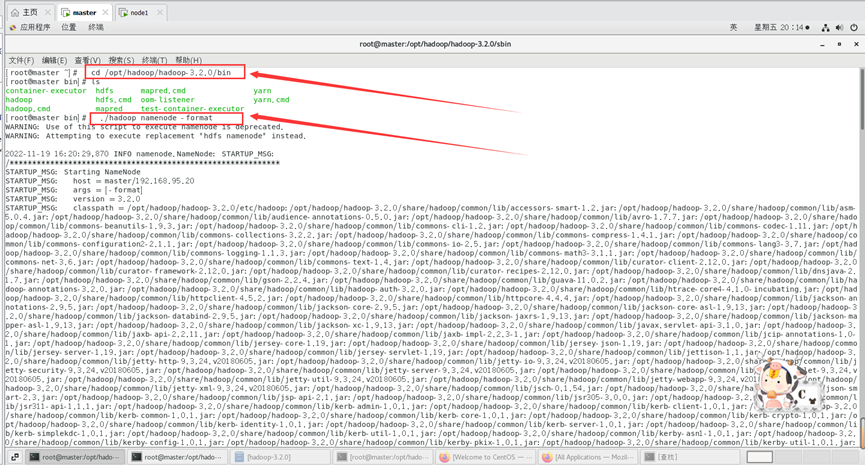
进入到master这台机器/opt/hadoop/hadoop-3.2.0/bin目录:
cd /opt/hadoop/hadoop-3.2.0/bin
执行初始化脚本
./hadoop namenode -format
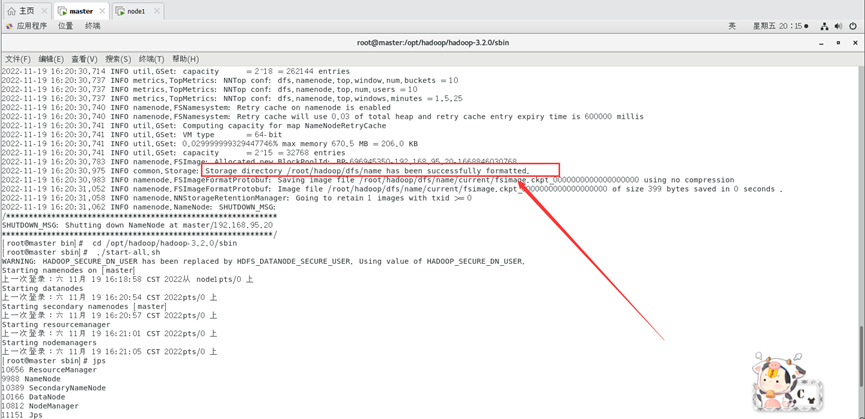
然后执行启动进程:
./sbin/start-all.sh
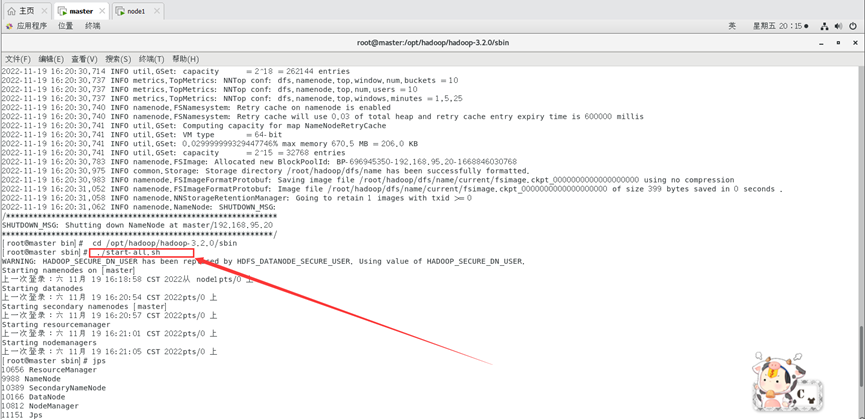
查看启动进程情况。
jps
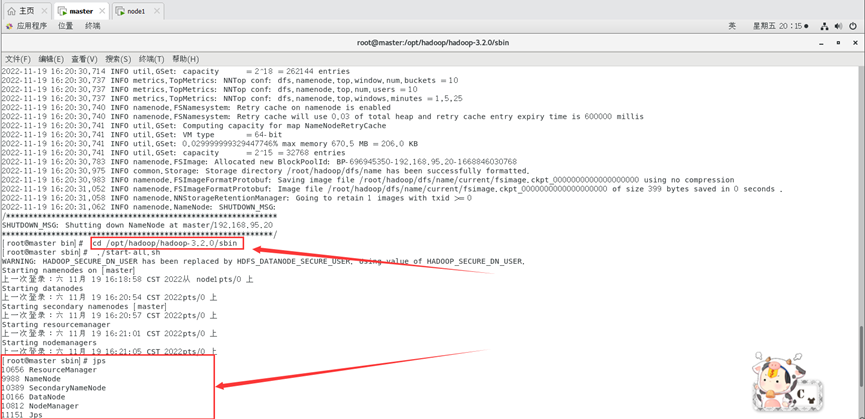
运行结果:
master是我们的namenode,该机器的IP是192.168.95.20,在本地电脑访问如下地址:
http://192.168.95.20:9870/
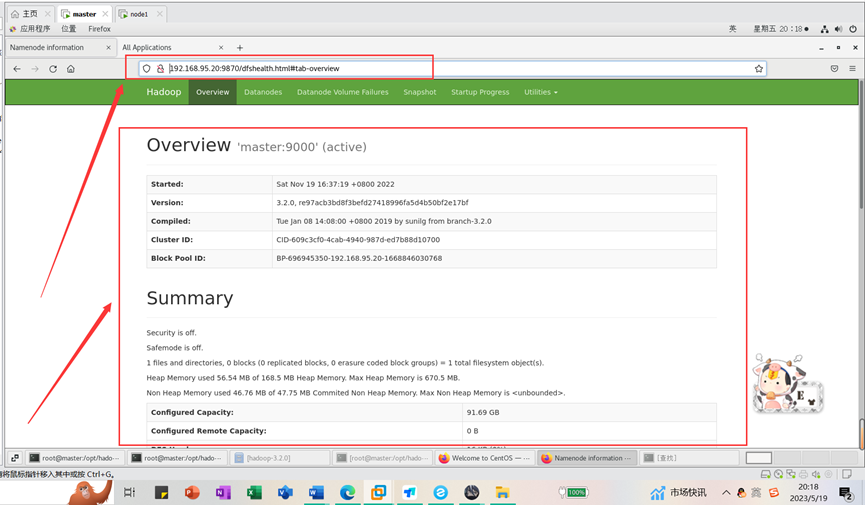
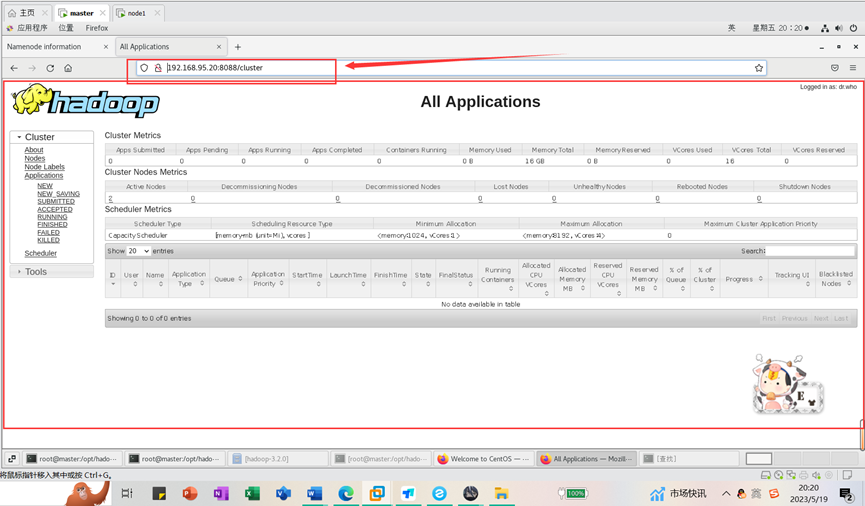
在本地浏览器里访问如下地址:
http://192.168.95.20:8088/cluster
自动跳转到cluster页面
在hdfs上建立一个目录存放文件
./bin/hdfs dfs -mkdir -p /home/hadoop/myx/wordcount/input
查看分发复制是否正常
./bin/hdfs dfs -ls /home/hadoop/myx/wordcount/input

八、运行MapReduce集群
Mapreduce运行案例:
在hdfs上建立一个目录存放文件
例如
./bin/hdfs dfs -mkdir -p /home/hadoop/myx/wordcount/input
可以先简单地写两个小文件分别为text1和text2,如下所示。
file:text1.txt
hadoop is very good
mapreduce is very good
vim text1
加入下面内容:
hadoop is very good
mapreduce is very good

然后可以把这两个文件存入HDFS并用WordCount进行处理.
./bin/hdfs dfs -put text1 /home/hadoop/myx/wordcount/input

查看分发情况
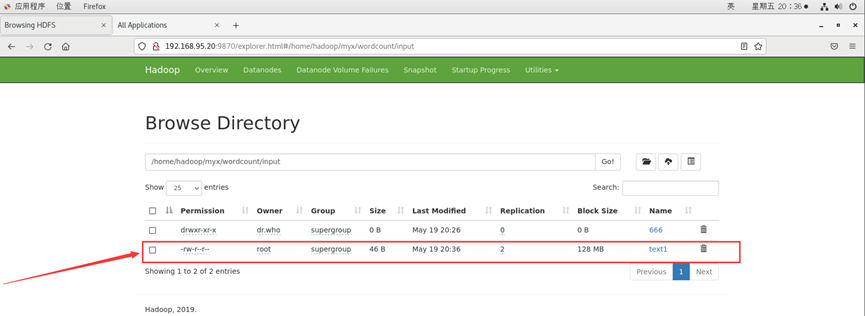
运行MapReduce用WordCount进行处理
./bin/hadoop jar /opt/hadoop/hadoop-3.2.0/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.0.jar wordcount /home/hadoop/myx/wordcount/input /home/hadoop/myx/wordcount/output
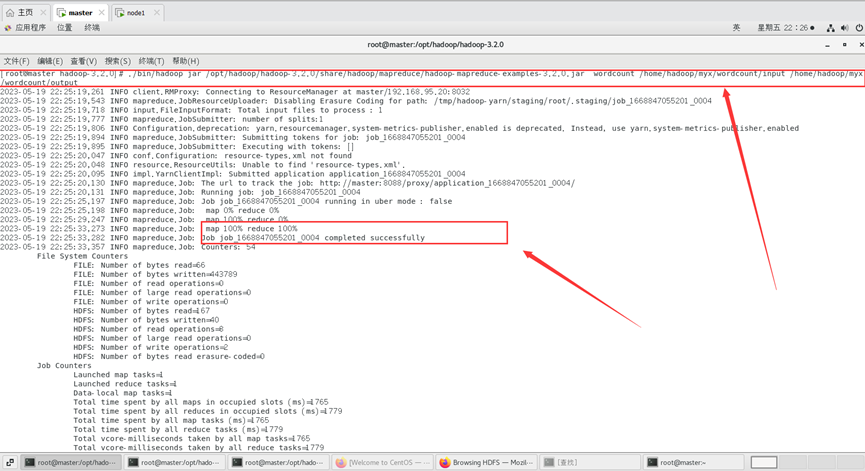
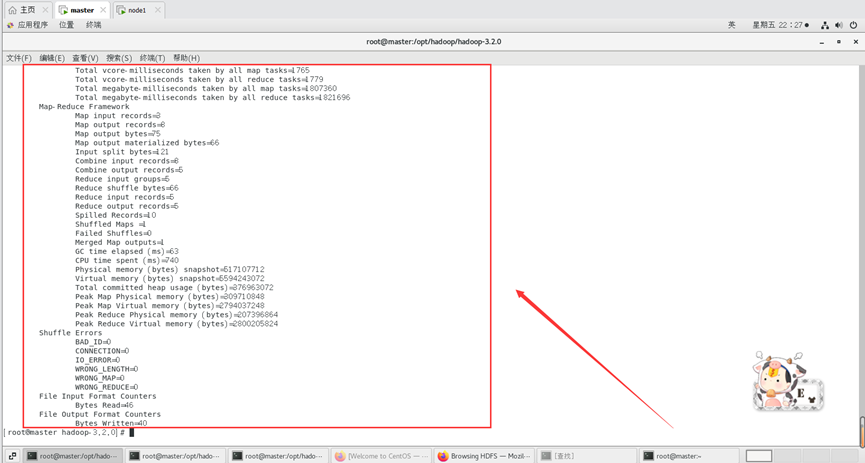
最终结果会存储在指定的输出目录中,查看输出目录里面可以看到以下内容。
./bin/hdfs dfs -cat /home/hadoop/myx/wordcount/output/part-r-00000*

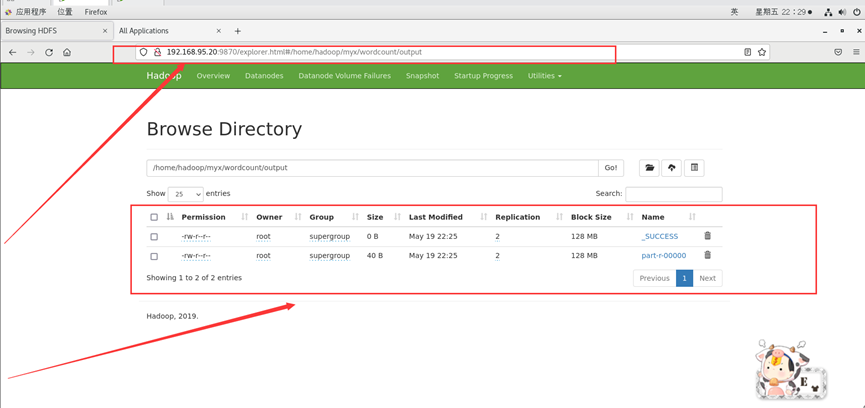
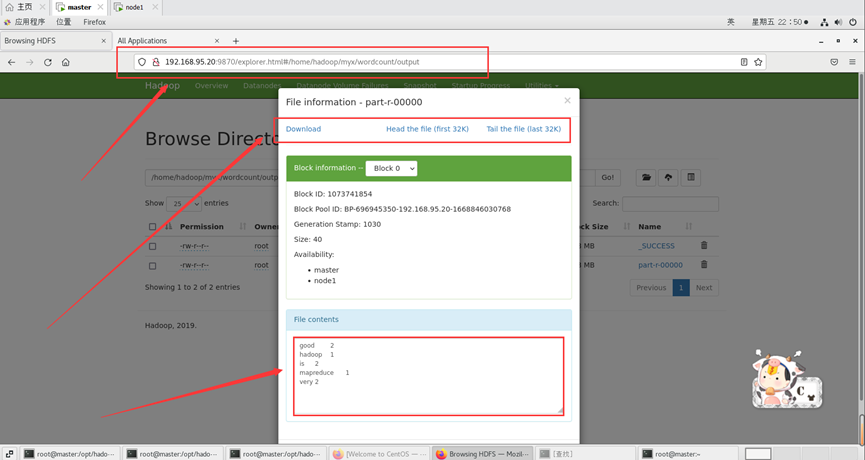
运行输出结果也可以在web端查看,里面有详细信息:
http://192.168.95.20:9870/explorer.html#/home/hadoop/myx/wordcount/output
再来试试第二个案例:
file:text2.txt
vim text2
加入下面内容
hadoop is easy to learn
mapreduce is easy to learn

在浏览器端查看新建的input2目录:
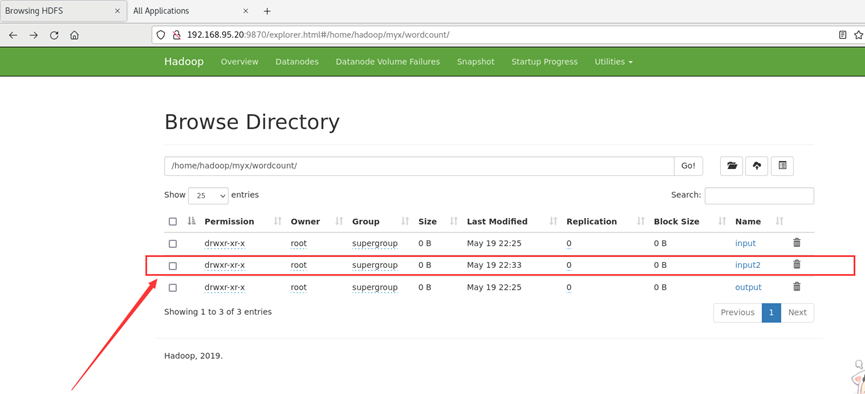
运行MapReduce进行处理,设置输出的目录为output2(输出结果目录不用提前创建,Mapreduce运行过程中会自动生成output2输出目录)。
./bin/hadoop jar /opt/hadoop/hadoop-3.2.0/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.0.jar wordcount /home/hadoop/myx/wordcount/input2 /home/hadoop/myx/wordcount/output2

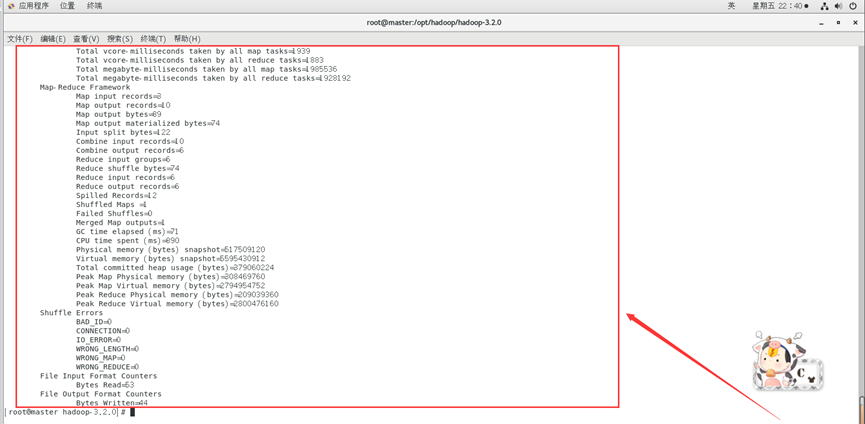
运行结束后,查看text2的输出结果
./bin/hdfs dfs -cat /home/hadoop/myx/wordcount/output2/part-r-00000*

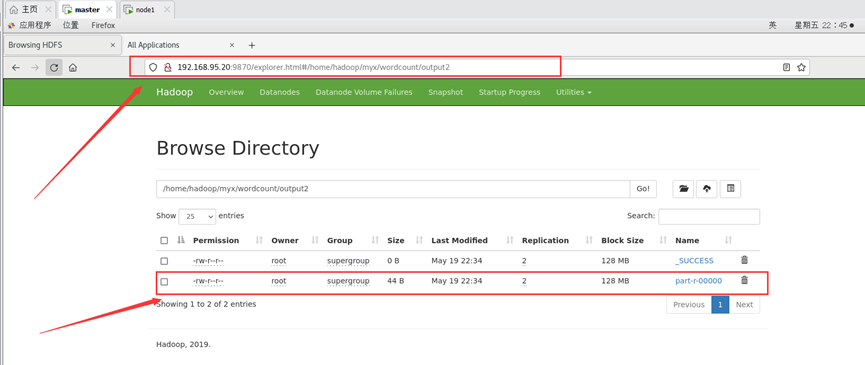
运行输出结果也可以在web端查看,里面有详细信息:
http://192.168.95.20:9870/explorer.html#/home/hadoop/myx/wordcount/output2
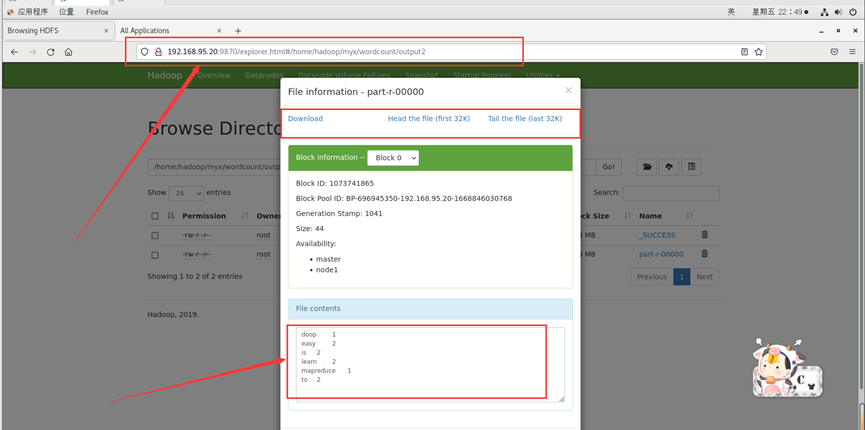
以上输出结果为每个单词出现的次数。
我们再自己试试运行测试程序WordCount
先在hadoop当前用户目录下新建文件夹WordCount,在其中建立两个测试文件分别为file1.txt,file2.txt。自行在两个文件中填写内容。
新建文件夹WordCount。
mkdir WordCount
ls

cd WordCount
vim file1.txt

file1.txt文件内容为:
This is the first hadoop test program!

vim file2.txt
file2.txt文件内容为:
This program is not very difficult,but this program is a common hadoop program!

然后在Hadoop文件系统HDFS中/home目录下新建文件夹input,并查看其中的内容。具体命令如下。
cd /opt/hadoop/hadoop-3.2.0
./bin/hadoop fs -mkdir /input
./bin/hadoop fs -ls /

在浏览器端查看:
http://192.168.95.20:9870/explorer.html#/input
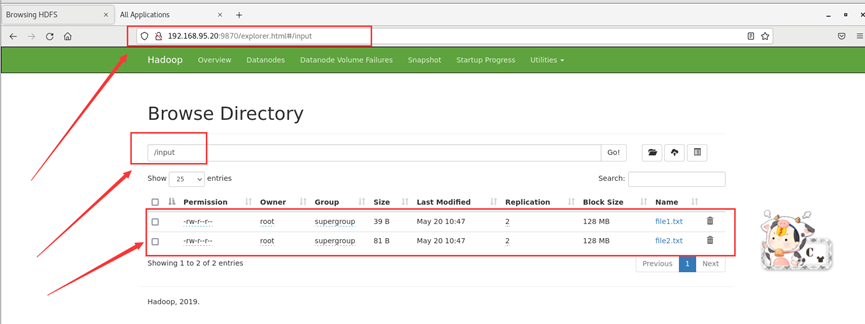
将WordCount文件夹中file1.txt\file2.txt文件上传到刚刚创建的“input”文件夹。具体命令如下。
./bin/hadoop fs -put /opt/hadoop/hadoop-3.2.0/WordCount/*.txt /input

运行Hadoop的示例程序,设置输出的目录为/output(输出结果目录不用提前创建,Mapreduce运行过程中会自动生成/output输出目录)。
./bin/hadoop jar /opt/hadoop/hadoop-3.2.0/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.0.jar wordcount /input /output
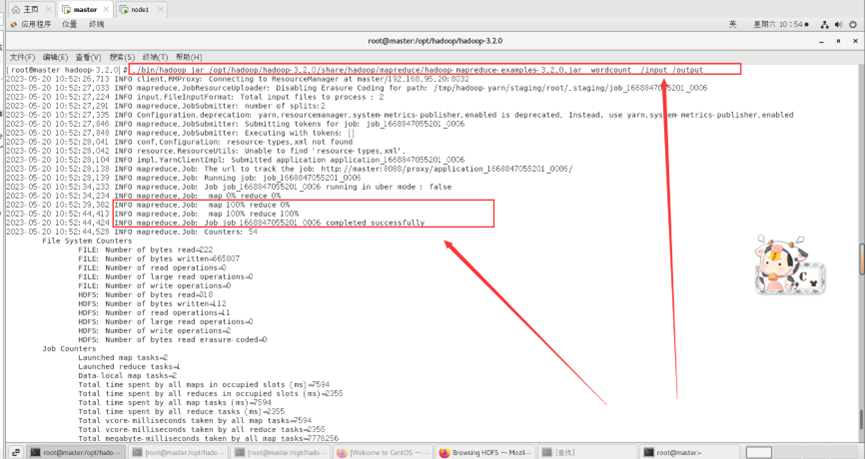
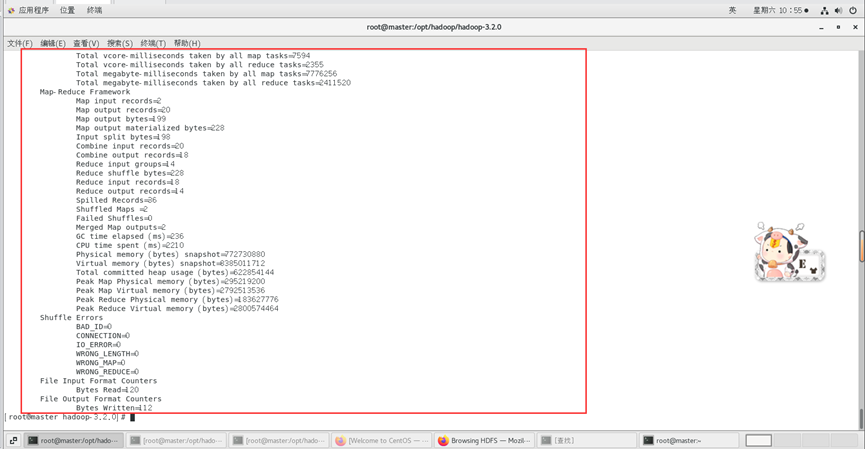
查看输出结果的文件目录信息和WordCount结果。
使用如下命令查看输出结果的文件目录信息。
./bin/hadoop fs -ls /output

使用如下命令查看WordCount的结果。
./bin/hdfs dfs -cat /output/part-r-00000*
输出结果如下所示
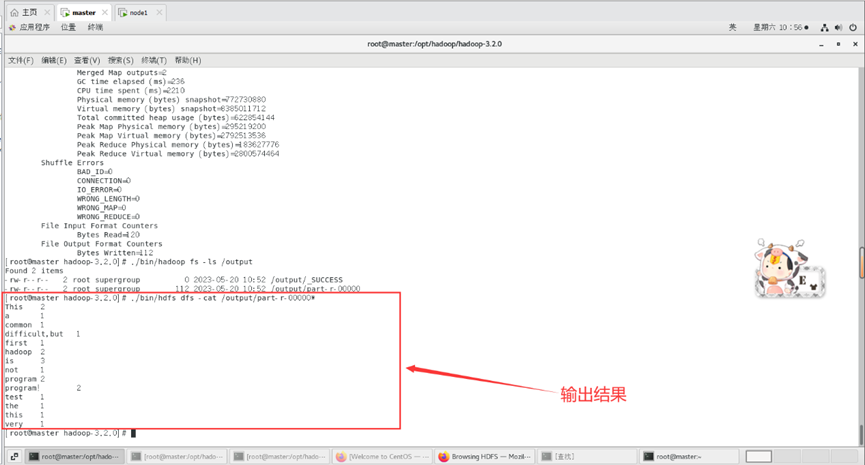
运行输出结果也可以在web端查看,里面有详细信息:
http://192.168.95.20:9870/explorer.html#/output
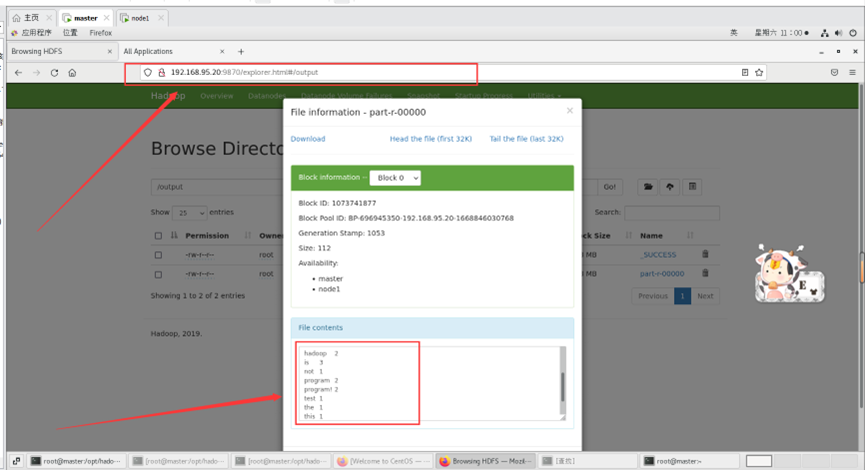
以上输出结果为每个单词出现的次数。
至此Centos搭建hadoop集群和运行3个MapReduce集群案例完成!
我记得之前有个关于Hadoop版本端口有个简单的面试题,这里会来问你一些重要服务进程的端口号。
这里怕有的小伙伴不知道,我来给大家整理一下。
对于版本比较新的Hadoop3.0x :
| Hadoop3.0x | 对应端口号 |
|---|---|
| HDFS NameNode 内部通信端口 | 8020/9000/9820 |
| HDFS NameNode对用户的查询端口HTTP UI | 9870 |
| MapReduce查看执行任务的端口 | 8088 |
| 历史服务通信端口 | 19888 |
对于版本Hadoop2.0x 的:
| Hadoop2.0x | 对应端口号 |
|---|---|
| HDFS NameNode 内部通信端口 | 8020/9000 |
| HDFS NameNode对用户的查询端口HTTP UI | 50070 |
| MapReduce查看执行任务的端口 | 8088 |
| 历史服务通信端口 | 19888 |
OK,花了快2小时的Linux从零搭建Hadoop集群(CentOS7+hadoop 3.2.0+JDK1.8+Mapreduce完全分布式集群)终于整理完成了,辛苦的小马同学决定奖励自己一把大乱斗,希望此教程对各位有所帮助,这些都已经试过水了,各位环境配置和操作没问题的话,基本都能部署完成,我这里部署了一个从机node1节点,可以根据自己需要增加3台或者更多node节点,节点配置信息修改的操作都是一样的。
有需要的小伙伴可以找我要完整的项目工程源码及详细文档,欢迎各位小伙伴的来访!
最后祝各位部署一切顺利!