使用scrapy实现爬虫实例
一、Scrapy安装
使用命令:pip install scrapy
安装成功后验证是否成功,输入如下代码,执行:
import scrapy
print(scrapy.version_info)
我这里输出的是(1,6,0)版本,说明scrapy安装成功

二、第一个Scrapy网络爬虫
1.创建scrapy框架——scrapy startproject name
注:name为项目名称

进入pycharm中开始我们的项目
2.使用Spider实现数据的爬取
2.1创建爬虫项目
在spiders中创建爬虫项目,这里是booksSpider.py
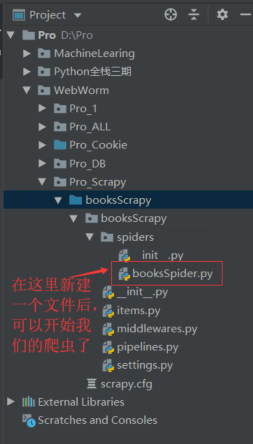 、
、
booksSpider.py 代码为:
from scrapy import Request
from scrapy.spider import Spider
class booksSpider(Spider):
name = 'books'
# 初始请求,获取起始的url
def start_requests(self):
url = 'http://books.toscrape.com/catalogue/category/books_1/index.html'
yield Request(url)
# 解析数据的函数
def parse(self, response):
print(response.text)
2.2运行爬虫项目——start.py文件
start.py文件就像一个公式一样,可以用于任何scrapy项目的运行,只需将项目名称改掉就行了,如下:
start.py 代码为:
注——单引号中的 book 是爬虫的名字
from scrapy import cmdline
cmdline.execute('scrapy crawl book'.split())
在start.py文件中运行后,便可得到网站代码

2.3爬取网站信息
将2.1中booksSpider.py文件中的输出网页内容利用xpath()方法来爬取我们想要的数据,booksSpider.py 代码为:
from scrapy import Request
from scrapy.spiders import Spider
class booksSpider(Spider):
name = 'books' # 爬虫命名只能用name接收,不能换成其他的
allBooks = [] #保存所有网页的内容
# 初始请求,获取起始的url
def start_requests(self):
url = 'http://books.toscrape.com/catalogue/category/books_1/index.html'
yield Request(url)
# 解析数据的函数
def parse(self, response):
li_selector = response.xpath("//ol[@class='row']/li")
for one_selector in li_selector:
# 名称
name = one_selector.xpath("article[@class='product_pod']/h3/a/@title").extract()[0]
# 价格
price = one_selector.xpath("article[@class='product_pod']/div[@class='product_price']/p[1]/text()").extract()[0]
one_list = [name, price]
self.allBooks.append(one_list)
print(self.allBooks)
# 下一页
next_url = response.xpath('//li[@class="next"]/a/@href').extract()[0]
if next_url:
next_url = "http://books.toscrape.com/catalogue/category/books_1/" + next_url
yield Request(next_url)
进而可以进入start.py文件来运行。
三、总结
整个项目执行起来,首先会调用start_requests(self)方法,初始请求,用来获取起始的url,然后调用scrapy中的Request(url)向网站生成一个请求,并使用yield将请求返回(yield会将请求返回回去并继续执行该函数余下的部分,但return的用法就不会继续执行余下的部分,这就是二者的区别),请求发送完以后就会向目标网站爬取数据,所以自动调用parse(self,response)方法,服务器就会将数据的对象给response,故response是一个对象,该对象有一个方法自带xpath()方法用来解析数据。
本章讲了使用Spider爬取数据,下一章会记录使用Item实现数据的封装。
