系列文章目录
实战使用scrapy与selenium来爬取数据
前言
当学会使用Scrapy 和 Selenium后的那就试试通过Scrapy 驱动 Selenium来获取数据,可以绕过JS解密的耗时,缺点是可能爬取数据的速度会变慢慢。
Scrapy 是用 Python 实现的一个为了爬取网站数据、提取结构性数据而编写的应用框架。
Scrapy 常应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中。
通常我们可以很简单的通过 Scrapy 框架实现一个爬虫,抓取指定网站的内容或图片。
Selenium是一个Web的自动化测试工具,最初是为网站自动化测试而开发的,类型像我们玩游戏用的按键精灵,可以按指定的命令自动操作,不同是Selenium 可以直接运行在浏览器上,它支持所有主流的浏览器(包括PhantomJS这些无界面的浏览器)。
Selenium 可以根据我们的指令,让浏览器自动加载页面,获取需要的数据,甚至页面截屏,或者判断网站上某些动作是否发生。
一、前期准备
- 安装 scrapy
pip install scrapy - 安装 selenium
pip install selenium - 安装 mongodb 数据
二、思路与运行程序
1.思路
- 通过驱动 scrapy 来启动 selenium 打开浏览器来访问网址,获取数据,也可以通过此方法来获取被JS加密过的数据
2.运行程序
- 通过启动 amazonselenium 项目,来控制 selenium 来获取数据
- 保存到 mongodb 的数据
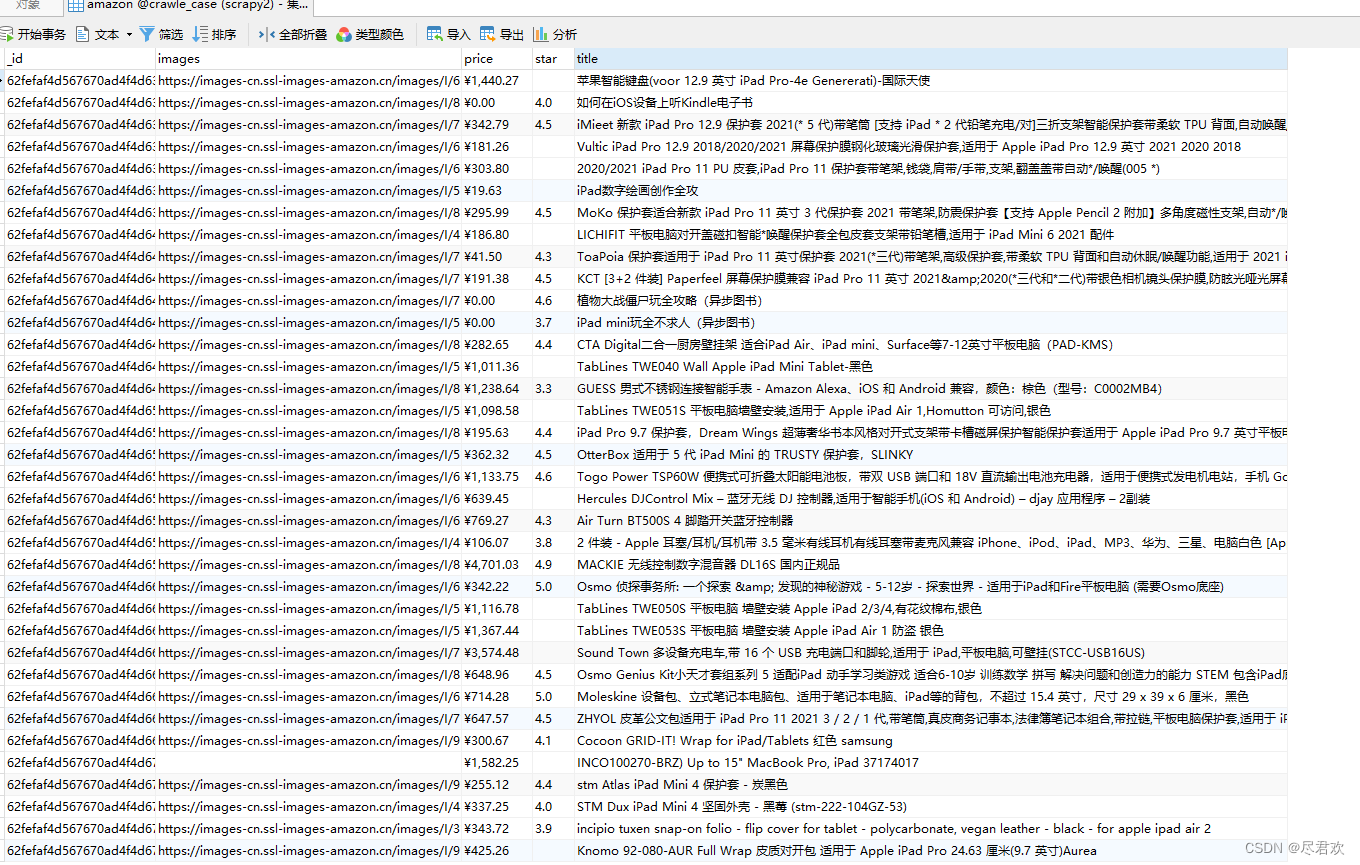
三、代码
1.代码下载
2.部分代码
-
amazon.py
class AmazonSpider(scrapy.Spider): name = 'amazon' allowed_domains = ['www.amazon.cn'] start_urls = ['http://www.amazon.cn/'] # 负责生成url链接 def start_requests(self): # https://www.amazon.cn/s?k=iPad&__mk_zh_CN=%E4%BA%9A%E9%A9%AC%E9%80%8A%E7%BD%91%E7%AB%99&crid=UH9JRIHEWIMZ&sprefix=ipad%2Caps%2C140&ref=nb_sb_noss_1 base_url = 'https://www.amazon.cn/s?' # https://www.amazon.cn/s?k=ipad&page=2 # data = {'k':'ipad', 'page': '1', 'crid': '31DTEW5X7KV5Q', 'qid': '1660806360', 'sprefix': 'ipad%2Caps%2C96', 'ref': 'sr_pg_1'} data = { 'k':'ipad', 'page': '1'} for keyword in settings['KEYWORDS']: data['k'] = keyword # data['sprefix'] = 'ipad%2Caps%2C96' for page in range(1, settings['MAX_PAGE'] + 1): # data['qid'] = int(time.time()) data['page'] = str(page) # data['ref'] = 'sr_pg_' + str(page) # 拼成链接 params = urlencode(data) if page > 1: amazon_url = base_url + params else: amazon_url = 'https://www.amazon.cn/s?k=ipad' print(amazon_url) yield scrapy.Request(url=amazon_url, callback=self.parse,dont_filter=True) # 负责获取数据 def parse(self, response): for data in response.xpath('//*[@id="search"]/div[1]/div[1]/div/span[3]/div[2]/div'): images = data.re(r'<img class="s-image" src="(.*?)" srcset="" alt=".*?" data-image-index=".*?" data-image-load=.*?data-image-latency=.*?>') title = data.re(r'<span class="a-size-base-plus a-color-base a-text-normal">(.*?)</span>') price = data.re(r'<span class="a-offscreen">(¥.*?.\d{2})</span>') star = data.re(r'<span class="a-icon-alt">(\d.\d) 颗星,最多 5 颗星</span>') # <span class="a-icon-alt">3.5 颗星,最多 5 颗星</span> # <span class="a-offscreen">¥266.78</span> # <span class="a-size-base-plus a-color-base a-text-normal">OtterBox Pad Mini 5 代 TRUSTY 外壳 - YOYO</span> if images ==[] and title ==[] and price ==[] and star ==[]: continue item = AmazonseleniumItem() item['images'] = ''.join(images) item['title'] = ''.join(title) item['price'] = ''.join(price) item['star'] = ''.join(star) yield item # print(response.text) -
items.py
class AmazonseleniumItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() # Mongdb与mysql的表名 collection = table = 'amazon' images = scrapy.Field() title = scrapy.Field() price = scrapy.Field() star = scrapy.Field() -
middlewares.py
负责驱动selenium进行访问网址class SeleniumMiddleware: def __init__(self, timeout=None): self.option = ChromeOptions() # 开启 无头模式 self.timeout = timeout # self.option.add_argument('--headless') self.option.add_experimental_option('excludeSwitches', ['enable-automation']) self.option.add_experimental_option('useAutomationExtension', False) self.browser = webdriver.Chrome(options=self.option) self.browser.set_page_load_timeout(self.timeout) # 设置超时 self.wait = WebDriverWait(self.browser, self.timeout) self.browser.execute_cdp_cmd('Page.addScriptToEvaluateOnNewDocument', { 'source': 'Object.defineProperty(navigator, "webdriver", {get: () => undefined})' }) def __del__(self): self.browser.close() @classmethod def from_crawler(cls, crawler): return cls(timeout=crawler.settings.get('SELENIUM_TIMEOUT')) # //*[@id="search"]/div[1]/div[1]/div/span[3]/div[2]/div[50]/div/div/span/span[1]/text() def process_request(self, request, spider): try: self.browser.get(request.url) self.wait.until(EC.presence_of_element_located((By.XPATH, '//*[@id="search"]'))) time.sleep(2) return HtmlResponse(url=request.url, body=self.browser.page_source, request=request, encoding='utf-8',status=200) except TimeoutException: return HtmlResponse(url=request.url, status=500, request=request) -
pipelines.py
负责将数据写入到Mongodb中class MongoPipeline: def __init__(self, mongo_uri, mongo_db): self.mongo_uri = mongo_uri self.mongo_db = mongo_db @classmethod def from_crawler(cls, crawler): return cls( mongo_uri=crawler.settings.get('MONGO_URI'), mongo_db=crawler.settings.get('MONGO_DATABASE') ) def open_spider(self, spider): self.client = pymongo.MongoClient(self.mongo_uri) self.db = self.client[self.mongo_db] def close_spider(self, spider): self.client.close() def process_item(self, item, spider): # scrapy通过itemadapter库支持以下类型的item:dictionaries、item object、dataclass object和attrs object # self.db[item.collection].insert_one(ItemAdapter(item).asdict()) # 存在则更新,不存在则新建, self.db[item.collection].update_one({ # 保证 数据 是唯一的 'images': ItemAdapter(item).get('images') }, { '$set': ItemAdapter(item) }, upsert=True) return item -
settings.py
DOWNLOADER_MIDDLEWARES = { 'amazonselenium.middlewares.SeleniumMiddleware': 543, # 'amazonselenium.middlewares.AmazonseleniumDownloaderMiddleware': 543, } ITEM_PIPELINES = { 'amazonselenium.pipelines.MongoPipeline': 300, } KEYWORDS = ['iPad'] MAX_PAGE = 10 SELENIUM_TIMEOUT = 20 MONGO_URI = 'mongodb://192.168.27.101:27017' MONGO_DATABASE = 'crawle_case'
总结
以上就是今天要讲的内容,本文仅仅介绍了Scrapy 驱动 selenium来获取数据,当selenium获取到页面代码时,我们需要的数据已经加载在页面代码中,再来获取数据已经是基础的东西了,难点在于驱动 selenium 访问网站。