前言
小袁开始实习了,我主管让我练一下爬虫,公司是做商标大数据的,所以这次爬取的是商标网站,之后也会更新一些爬虫教程(美女图片之类的劳逸结合你们懂得!!!)

点赞收藏博主更有创作动力哟,以后常更!!!

爬取目标
我们要爬取的网页是:http://www.mp.cc/search/1?category=25
网站主页如下:
1)第一页有39个商标展示,每一个都需要进入网页获取详细信息(未截图完)

红色框就是要爬取的内容

2)一共91页

给你们看看我爬取完的效果,保存在SqlServer中:
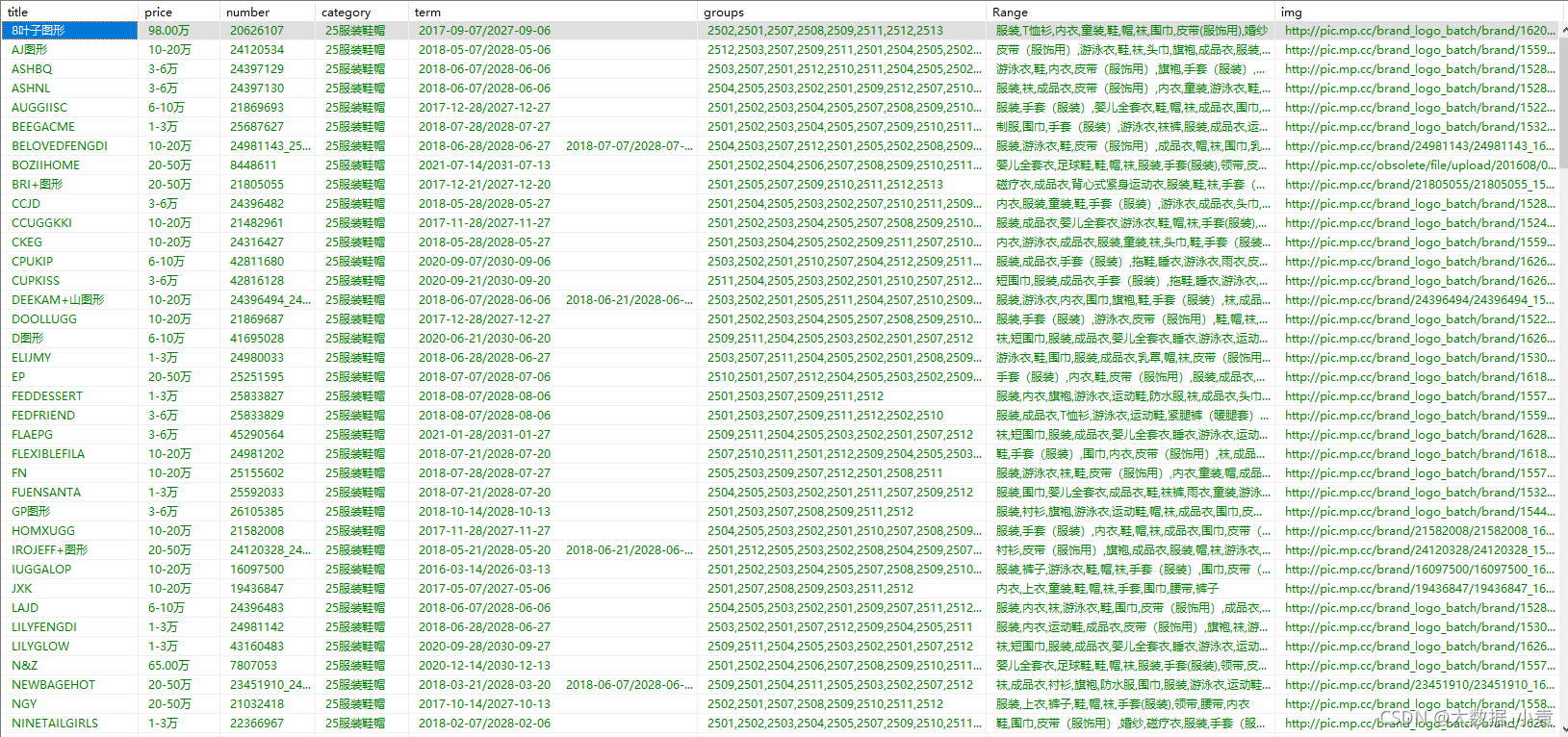
爬取的内容是:商标名、商标价格、商标编号、所属类别、专用期限、类似群组、注册范围、商标图片地址
准备工作
我用的是python3.8,VScode编辑器,所需的库有:requests、etree、pymssql
开头导入所需用到的导入的库:
import requests # python基础爬虫库
from lxml import etree # 可以将网页转换为Elements对象
import pymssql # 连接SqlServer的库
建表:
CREATE TABLE "test5" (
"title" NVARCHAR(MAX),
"price" NVARCHAR(MAX),
"number" NVARCHAR(MAX),
"category" NVARCHAR(MAX),
"term" NVARCHAR(MAX),
"groups" NVARCHAR(MAX),
"Range" NVARCHAR(MAX),
"img" NVARCHAR(MAX)
)
为防止,字段给的不够,直接给个MAX!

代码分析
直接上完整代码,再逐步分析!
import requests # python基础爬虫库
from lxml import etree # 可以将网页转换为
import pymssql # 连接SqlServer的库
import time
class TrademarkSpider:
def __init__(self) :
self.baseurl = "http://www.mp.cc/search/%s?category=25"
self.headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36"}
# 发送请求,获取相应
def parse_url(self,url):
response = requests.get(url,headers=self.headers)
time.sleep(2)
return response.content.decode()
# 获取第一页中39个详情页地址
def get_content_list(self,html_str):
html = etree.HTML(html_str)
div_list = html.xpath("//div[@class='item_wrapper']") # 根据div分组
item = {
}
for div in div_list:
item["href"]= div.xpath("//a[@class='img-container']/@href")
# 拼接网页
for i in range(39):
item["href"][i] = 'http://www.mp.cc%s' % item["href"][i]
for value in item.values():
content_list = value
print(content_list)
return content_list
# 获取39个详情页信息
def get_information(self,content_list):
information = []
for i in range(len(content_list)):
details_url = content_list[i]
html_str = self.parse_url(details_url)
html = etree.HTML(html_str)
div_list = html.xpath("//div[@class='d_top']") # 根据div分组
item = []
for div in div_list:
title = div.xpath("///div[@class='d_top_rt_right']/text()")
price = div.xpath("//div[@class='text price2box']/span[2]/text()")
number = div.xpath("//div[@class='text'][1]/text()")
category = div.xpath("//div[@class='text'][2]/span[@class='cate']/text()")
term = div.xpath("//div[@class='text'][3]/text()")
groups = div.xpath("//div[@class='text'][4]/text()")
Range = div.xpath("//div[@class='text'][5]/text()")
img = div.xpath("//img[@class='img_logo']/@src")
title = ' '.join(title).replace('\n', '').replace('\r', '').replace(' ','')
price = ' '.join(price)
number = ' '.join(number).replace('\n', '').replace('\r', '').replace(' ','')
category = ' '.join(category)
term = ' '.join(term).replace('\n', '').replace('\r', '').replace(' ','')
groups = ' '.join(groups).replace('\n', '').replace('\r', '').replace(' ','')
Range = ' '.join(Range).replace('\n', '').replace('\r', '').replace(' ','')
img = ' '.join(img)
item.append(title)
item.append(price)
item.append(number)
item.append(category)
item.append(term)
item.append(groups)
item.append(Range)
item.append(img)
item = tuple(item)
information.append(item)
#print(information)
return information
def insert_sqlserver(self, information):
# 连接本地数据库服务,创建游标对象
db = pymssql.connect('.', 'sa', 'yuan427', 'test') #服务器名,账户,密码,数据库名
if db:
print("连接成功!")
cursor= db.cursor()
try:
# 插入sql语句
sql = "insert into test6 (title,price,number,category,term,groups,Range,img) values (%s,%s,%s,%s,%s,%s,%s,%s)"
# 执行插入操作
cursor.executemany(sql,information)
db.commit()
print('成功载入......' )
except Exception as e:
db.rollback()
print(str(e))
# 关闭游标,断开数据库
cursor.close()
db.close()
# 实现主要逻辑
def run(self):
# 6.实现主页翻页(1,92)
for i in range(1,92):
# 1.构造主页地址
url = self.baseurl % i
x = 0
while x<1:
# 2.发送请求,获取相应
html_str = self.parse_url(url)
# 3.获取第一页中39个详情页地址
content_list= self.get_content_list(html_str)
# 4.获取39个详情页信息
information = self.get_information(content_list)
# 5.入库
self.insert_sqlserver(information)
x += 1
if __name__ == "__main__":
trademarkSpider = TrademarkSpider()
trademarkSpider.run()

先讲讲我的整体思路再逐步解释:
- 第一步:构造主页的URL地址
- 第二步:发送请求,获取响应
- 第三步:获取第一页中39个详情页地址
- 第四步:获取39个详情页信息
- 第五步:存入SqlServer数据库
- 第六步:实现主页翻页(1-91页)
第一步
我们先手动翻页,1-3页:
http://www.mp.cc/search/1?category=25
http://www.mp.cc/search/2?category=25
http://www.mp.cc/search/3?category=25
可以看出来,网址只有中间一个数据在逐步递增,所以就可以构造主页地址,代码如下:
for i in range(1,92):
# 1.构造主页地址
url = self.baseurl % i
这里做了字符串拼接,baseurl在 __init__(self)中:
self.baseurl = "http://www.mp.cc/search/%s?category=25" #通过%s传数字进入
第二步
发送请求,获取响应,代码如下:
def __init__(self) :
self.baseurl = "http://www.mp.cc/search/%s?category=25"
self.headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36"}
# 发送请求,获取相应
def parse_url(self,url):
response = requests.get(url,headers=self.headers)
return response.content.decode() #返回网页代码,我们就在这里面提取数据
这会就有小伙伴不明白了,你headers什么意思啊?
- 防止服务器把我们认出来是爬虫,所以模拟浏览器头部信息,向服务器发送消息
- 这个 “装” 肯定必须是要装的!!!

第三步
获取第一页中39个详情页地址,代码如下:
def get_content_list(self,html_str):
html = etree.HTML(html_str)
div_list = html.xpath("//div[@class='item_wrapper']") # 根据div分组
item = {
}
# 获取网页(只有半截,如:/brand/detail/36003501)
for div in div_list:
item["href"]= div.xpath("//a[@class='img-container']/@href")
# 拼接网页
for i in range(39):
item["href"][i] = 'http://www.mp.cc%s' % item["href"][i]
#遍历字典存入列表
for value in item.values():
content_list = value
print(content_list)
return content_list
1)我们先把获取到的主页代码转换为Elements对象,就和网页中的一样,如下图:html = etree.HTML(html_str)
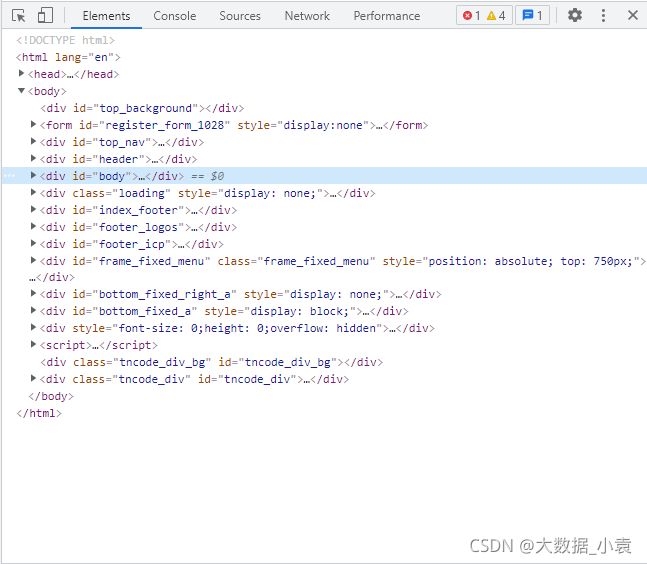
2)写Xpath根据div分组:div_list = html.xpath("//div[@class='item_wrapper']")
如图可以看出每个商标的详情地址都在<div class="item_wrapper">中
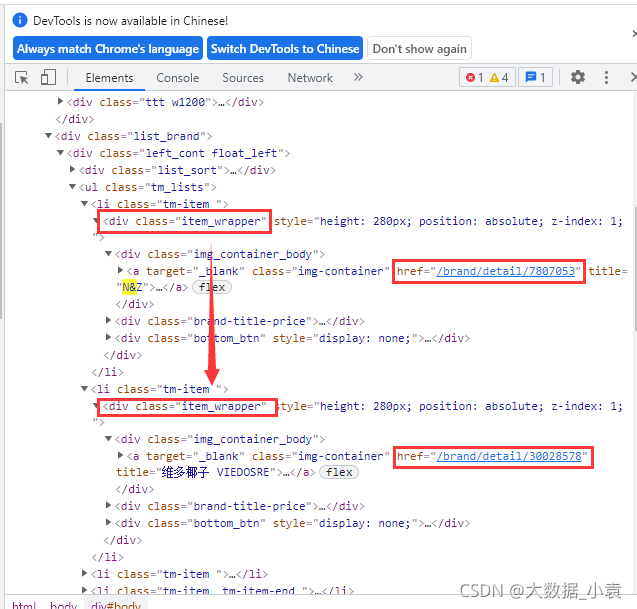
3)提取地址
item = {
}
for div in div_list:
item["href"]= div.xpath("//a[@class='img-container']/@href")
# 拼接网页
for i in range(39):
item["href"][i] = 'http://www.mp.cc%s' % item["href"][i]
#遍历字典存入列表
for value in item.values():
content_list = value
4)效果如下:
['http://www.mp.cc/brand/detail/36449901', 'http://www.mp.cc/brand/detail/26298802', 'http://www.mp.cc/brand/detail/22048146', 'http://www.mp.cc/brand/detail/4159836', 'http://www.mp.cc/brand/detail/9603914', 'http://www.mp.cc/brand/detail/4156243', 'http://www.mp.cc/brand/detail/36575014', 'http://www.mp.cc/brand/detail/39965756', 'http://www.mp.cc/brand/detail/36594259', 'http://www.mp.cc/brand/detail/37941094', 'http://www.mp.cc/brand/detail/38162960', 'http://www.mp.cc/brand/detail/38500643', 'http://www.mp.cc/brand/detail/38025192', 'http://www.mp.cc/brand/detail/37755982', 'http://www.mp.cc/brand/detail/37153272', 'http://www.mp.cc/brand/detail/35335841', 'http://www.mp.cc/brand/detail/36003501', 'http://www.mp.cc/brand/detail/27794101', 'http://www.mp.cc/brand/detail/26400645', 'http://www.mp.cc/brand/detail/25687631', 'http://www.mp.cc/brand/detail/25592319',
'http://www.mp.cc/brand/detail/25593974', 'http://www.mp.cc/brand/detail/24397124', 'http://www.mp.cc/brand/detail/23793395', 'http://www.mp.cc/brand/detail/38517219', 'http://www.mp.cc/brand/detail/36921312', 'http://www.mp.cc/brand/detail/6545326_6545324', 'http://www.mp.cc/brand/detail/8281719', 'http://www.mp.cc/brand/detail/4040639', 'http://www.mp.cc/brand/detail/42819737', 'http://www.mp.cc/brand/detail/40922772', 'http://www.mp.cc/brand/detail/41085317', 'http://www.mp.cc/brand/detail/40122971', 'http://www.mp.cc/brand/detail/39200273', 'http://www.mp.cc/brand/detail/38870472', 'http://www.mp.cc/brand/detail/38037836', 'http://www.mp.cc/brand/detail/37387087', 'http://www.mp.cc/brand/detail/36656221', 'http://www.mp.cc/brand/detail/25858042']
因为我们获取的详情页地址只有半截,所以在做一个拼接!
可能这里有小伙伴要问了为什么你要先存入字典再存列表呢???
可以自己试试如果直接存列表,所有的地址全部都挤在一起了,没法拼接!!!

第四步
分别进行39个详情页,并获取信息,代码如下:
# 获取39个详情页信息
def get_information(self,content_list):
information = []
for i in range(len(content_list)):
details_url = content_list[i]
html_str = self.parse_url(details_url)
html = etree.HTML(html_str)
div_list = html.xpath("//div[@class='d_top']") # 根据div分组
item = []
for div in div_list:
title = div.xpath("///div[@class='d_top_rt_right']/text()")
price = div.xpath("//div[@class='text price2box']/span[2]/text()")
number = div.xpath("//div[@class='text'][1]/text()")
category = div.xpath("//div[@class='text'][2]/span[@class='cate']/text()")
term = div.xpath("//div[@class='text'][3]/text()")
groups = div.xpath("//div[@class='text'][4]/text()")
Range = div.xpath("//div[@class='text'][5]/text()")
img = div.xpath("//img[@class='img_logo']/@src")
title = ' '.join(title).replace('\n', '').replace('\r', '').replace(' ','')
price = ' '.join(price)
number = ' '.join(number).replace('\n', '').replace('\r', '').replace(' ','')
category = ' '.join(category)
term = ' '.join(term).replace('\n', '').replace('\r', '').replace(' ','')
groups = ' '.join(groups).replace('\n', '').replace('\r', '').replace(' ','')
Range = ' '.join(Range).replace('\n', '').replace('\r', '').replace(' ','')
img = ' '.join(img)
item.append(title)
item.append(price)
item.append(number)
item.append(category)
item.append(term)
item.append(groups)
item.append(Range)
item.append(img)
item = tuple(item)
information.append(item)
#print(information)
return information
1)根据content_list长度遍历(分别获取详情页地址),并调用parse_url方法获取网页源码
for i in range(len(content_list)):
details_url = content_list[i]
html_str = self.parse_url(details_url)
2)根据div分组并获取数据
html = etree.HTML(html_str)
div_list = html.xpath("//div[@class='d_top']") # 根据div分组
item = []
for div in div_list:
title = div.xpath("///div[@class='d_top_rt_right']/text()")
price = div.xpath("//div[@class='text price2box']/span[2]/text()")
number = div.xpath("//div[@class='text'][1]/text()")
category = div.xpath("//div[@class='text'][2]/span[@class='cate']/text()")
term = div.xpath("//div[@class='text'][3]/text()")
groups = div.xpath("//div[@class='text'][4]/text()")
Range = div.xpath("//div[@class='text'][5]/text()")
img = div.xpath("//img[@class='img_logo']/@src")
- 好了又要小伙伴要问了XPath怎么写?,这里我用的是XPath Helper工具,就是下图那个黑框可以帮我们写Xpath定位元素,有需要的我可以写个安装使用教程
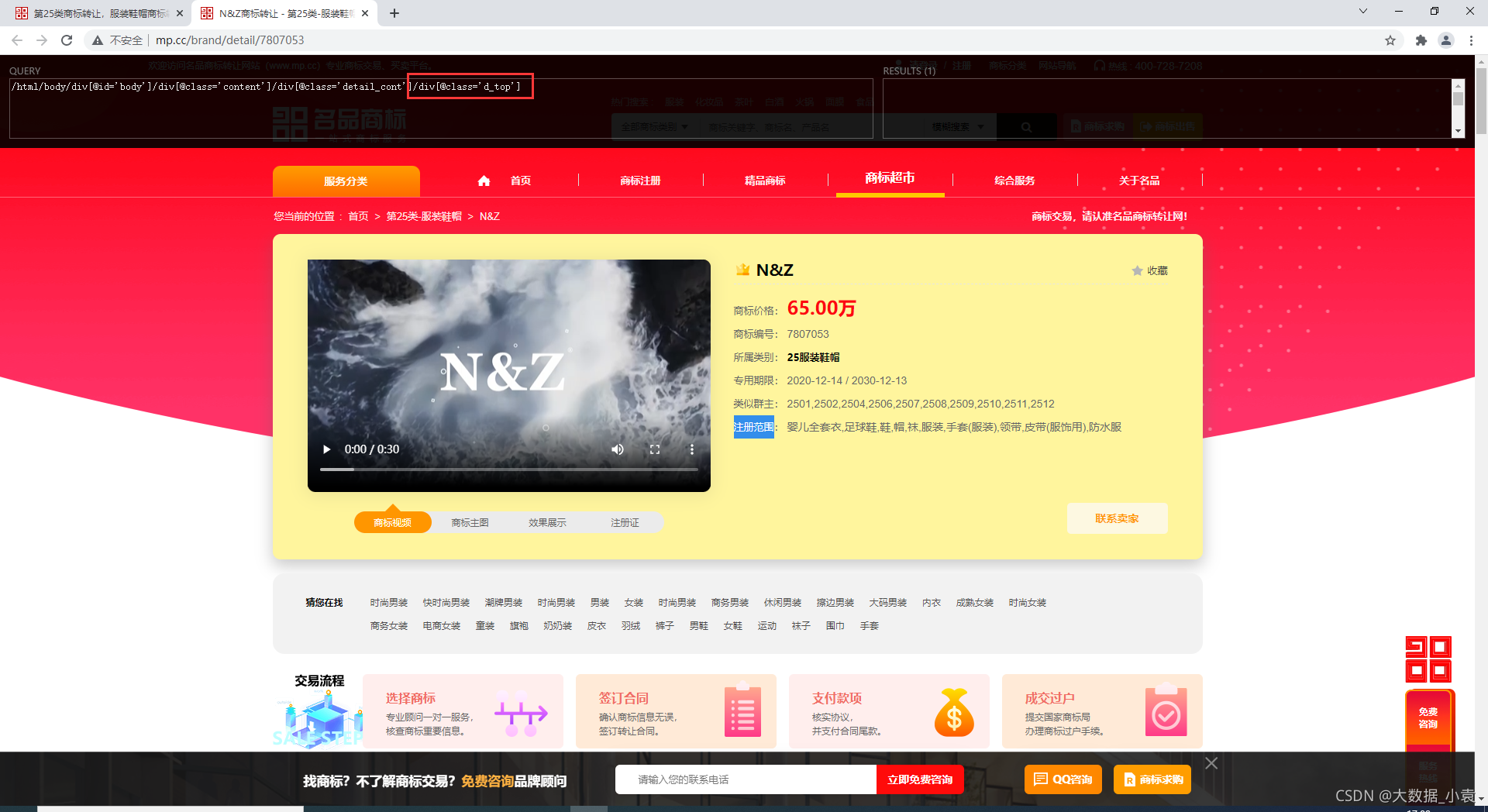
4)因为个别数据有空格换行符所以要先去掉,如图:

title = ' '.join(title).replace('\n', '').replace('\r', '').replace(' ','')
price = ' '.join(price)
number = ' '.join(number).replace('\n', '').replace('\r', '').replace(' ','')
category = ' '.join(category)
term = ' '.join(term).replace('\n', '').replace('\r', '').replace(' ','')
groups = ' '.join(groups).replace('\n', '').replace('\r', '').replace(' ','')
Range = ' '.join(Range).replace('\n', '').replace('\r', '').replace(' ','')
img = ' '.join(img)
第五步
把数据存入数据库,需要注意的是服务器名,账户,密码,数据库名和SQL语句中的表名!
def insert_sqlserver(self, information):
# 连接本地数据库服务,创建游标对象
db = pymssql.connect('.', 'sa', 'yuan427', 'test') #服务器名,账户,密码,数据库名
if db:
print("连接成功!")
cursor= db.cursor()
try:
# 插入sql语句
sql = "insert into test6 (title,price,number,category,term,groups,Range,img) values (%s,%s,%s,%s,%s,%s,%s,%s)"
# 执行插入操作
cursor.executemany(sql,information)
db.commit()
print('成功载入......' )
except Exception as e:
db.rollback()
print(str(e))
# 关闭游标,断开数据库
cursor.close()
db.close()
第六步
循环以上五步,按页数实现翻页
# 实现主要逻辑
def run(self):
# 6.实现主页翻页(1,92)
for i in range(1,92):
# 1.构造主页地址
url = self.baseurl % i
x = 0
while x<1:
# 2.发送请求,获取相应
html_str = self.parse_url(url)
# 3.获取第一页中39个详情页地址
content_list= self.get_content_list(html_str)
# 4.获取39个详情页信息
information = self.get_information(content_list)
# 5.入库
self.insert_sqlserver(information)
x += 1
最后:启动
if __name__ == "__main__":
trademarkSpider = TrademarkSpider()
trademarkSpider.run()
打开数据库看看是不是我们想要的结果:
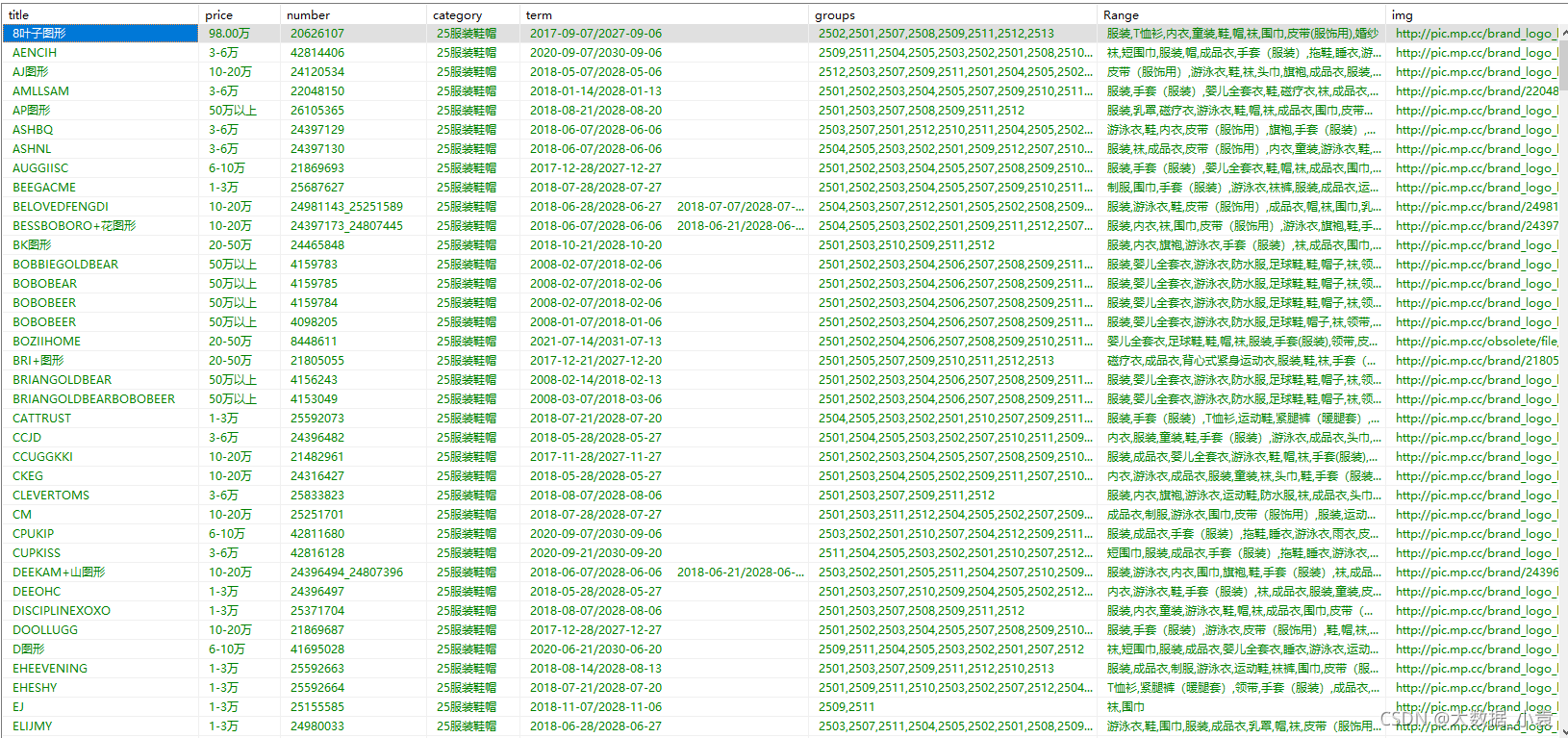
O了O了!!!

这也是我第一次写爬虫实战,有讲的不对的地方,希望各位大佬指正!!!,如果有不明白的地方评论区留言回复!兄弟们来个点赞有空就更新爬虫实战!!!
