python爬虫,爬取全国空气质量指数
编程环境:Jupyter Notebook
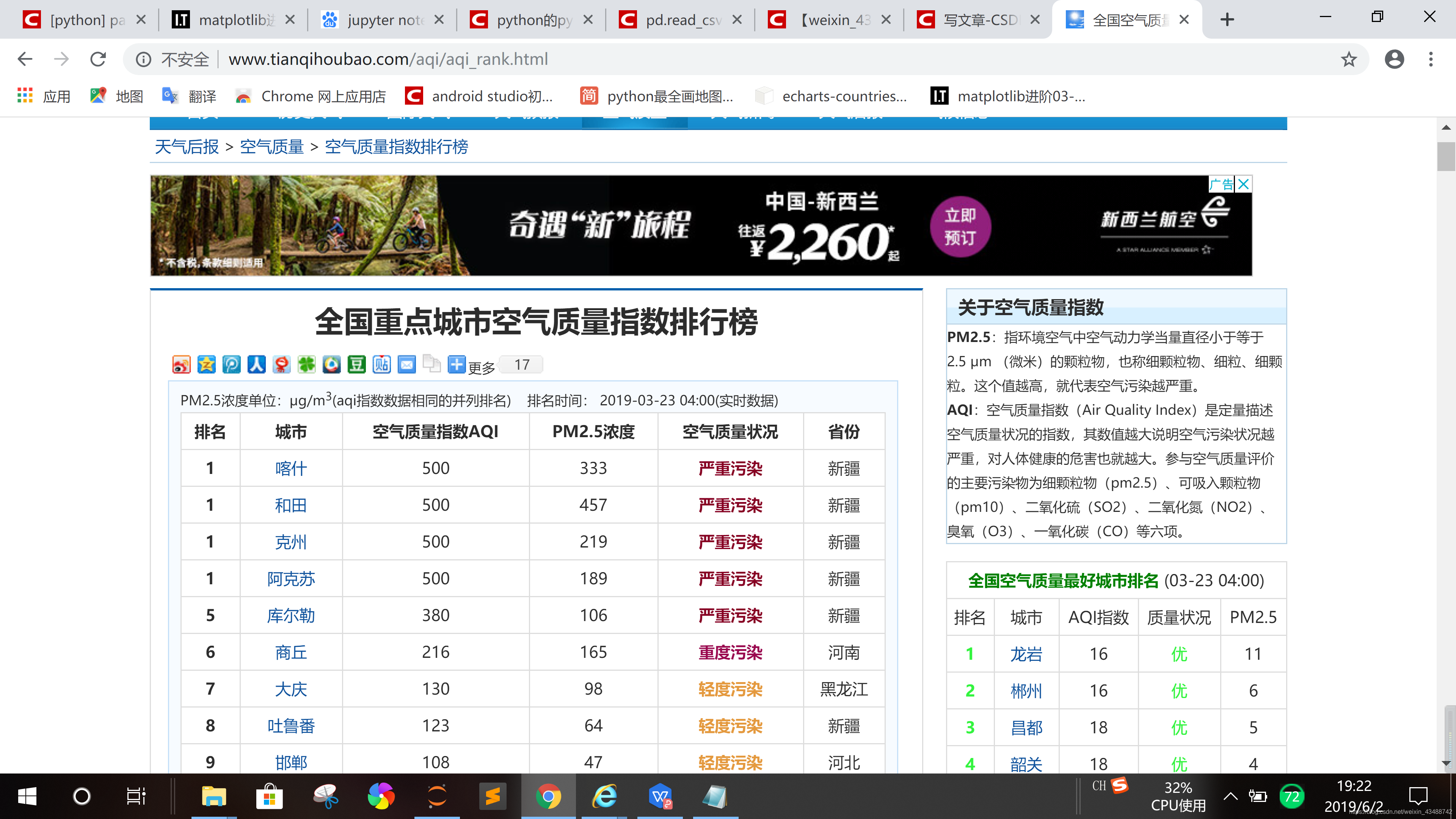
所要爬取的网页数据内容如下图
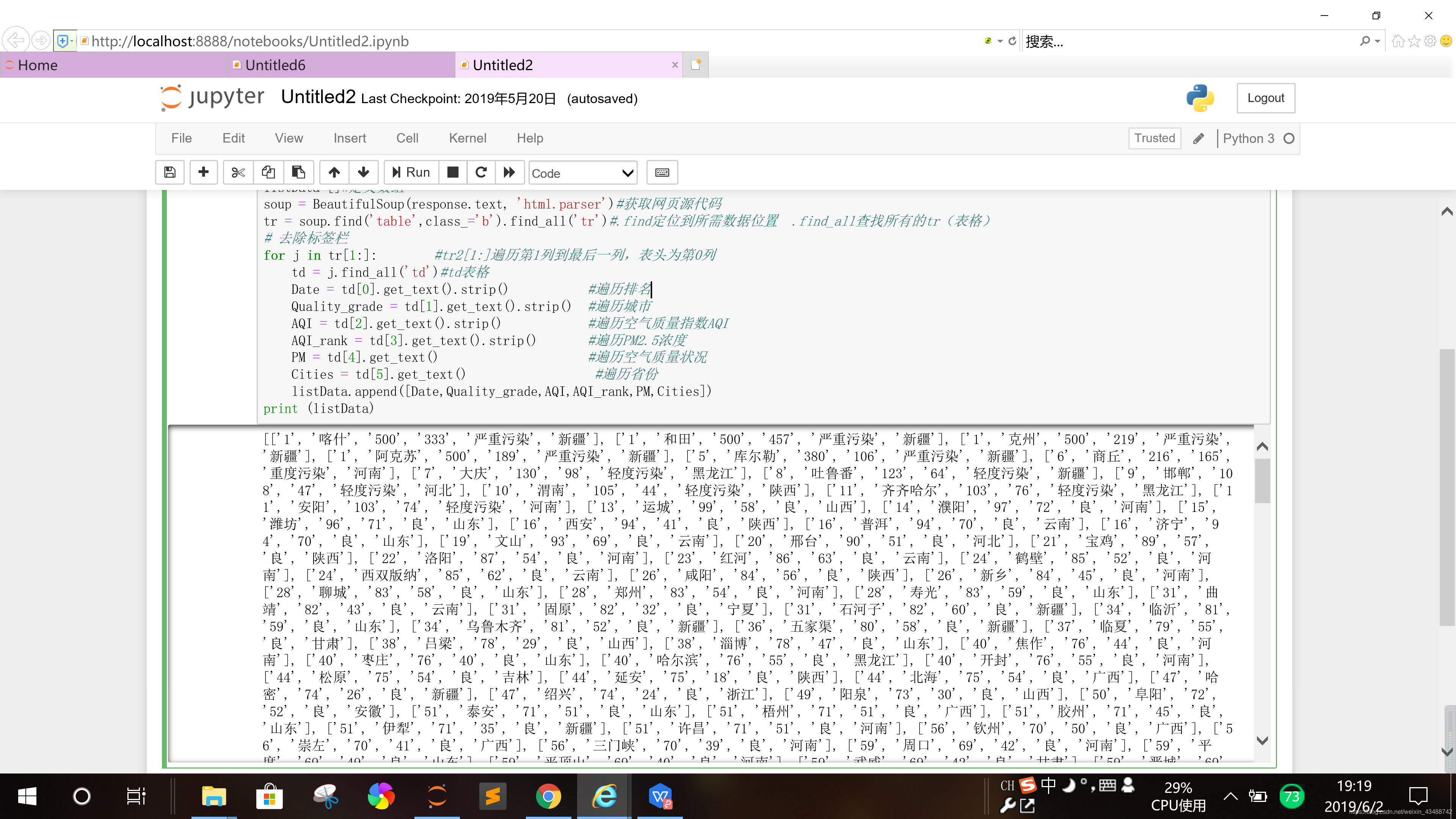
python爬虫代码及含义详细说明
#全国城市
import time
import requests
from bs4 import BeautifulSoup
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'
}#爬虫[Requests设置请求头Headers],伪造浏览器
# 核心爬取代码
url= 'http://www.tianqihoubao.com/aqi/aqi_rank.html'
params = {"show_ram":1}
response = requests.get(url,params=params, headers=headers)#访问url
listData=[]#定义数组
soup = BeautifulSoup(response.text, 'html.parser')#获取网页源代码
tr = soup.find('table',class_='b').find_all('tr')#.find定位到所需数据位置 .find_all查找所有的tr(表格)
# 去除标签栏
for j in tr[1:]: #tr2[1:]遍历第1列到最后一列,表头为第0列
td = j.find_all('td')#td表格
Date = td[0].get_text().strip() #遍历排名
Quality_grade = td[1].get_text().strip() #遍历城市
AQI = td[2].get_text().strip() #遍历空气质量指数AQI
AQI_rank = td[3].get_text().strip() #遍历PM2.5浓度
PM = td[4].get_text() #遍历空气质量状况
Cities = td[5].get_text() #遍历省份
listData.append([Date,Quality_grade,AQI,AQI_rank,PM,Cities])
print (listData)#打印
运行结果如下