0.概述
在统计学中,线性回归(Linear regression)是利用称为线性回归方程的最小二乘函数对一个或多个自变量和因变量之间关系进行建模的一种回归分析。这种函数是一个或多个称为回归系数的模型参数的线性组合。只有一个自变量的情况称为简单回归,大于一个自变量情况的叫做多元回归。 ——维基百科
从最简单的只有一个自变量的简答回归来看:
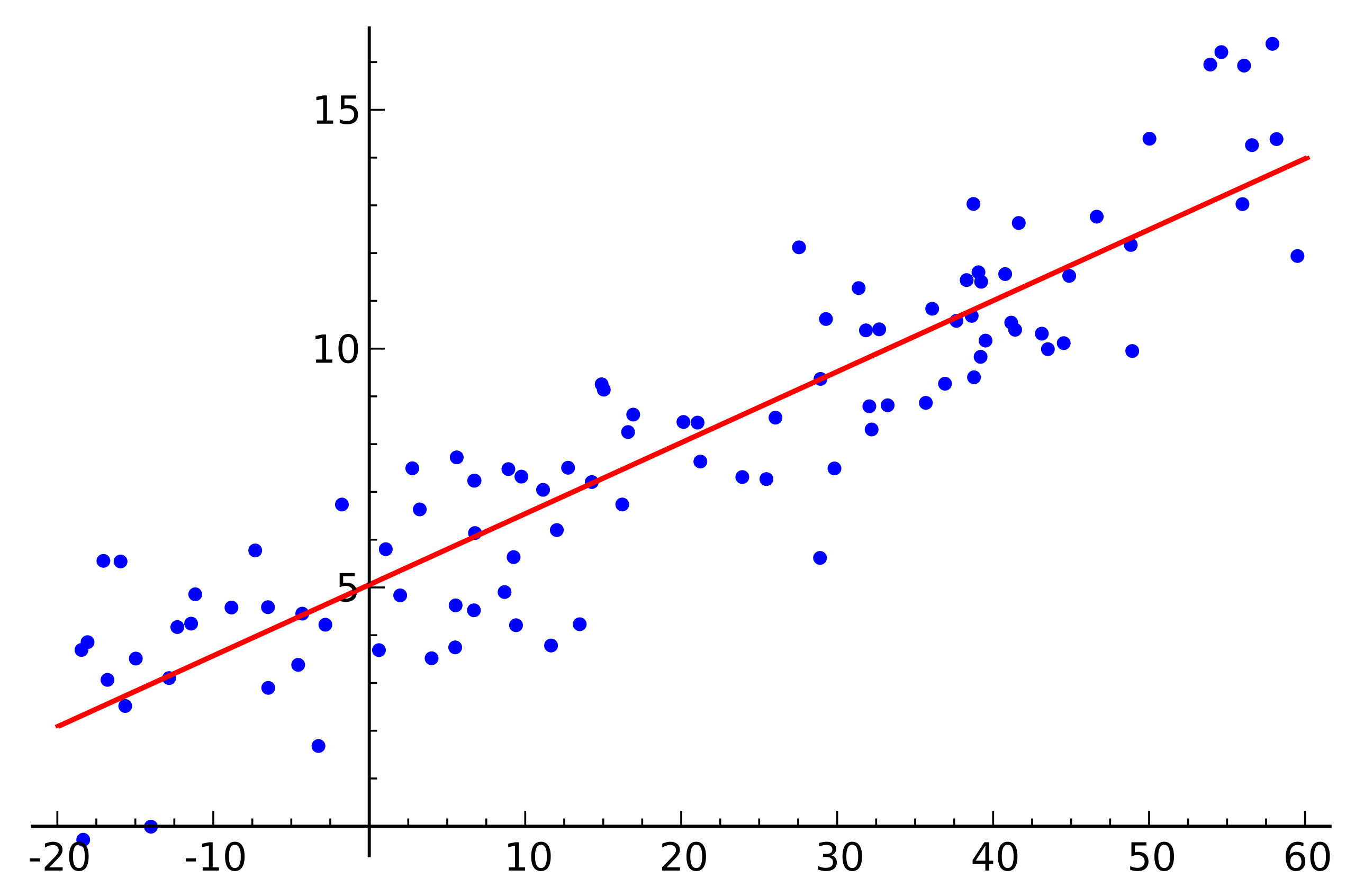
蓝点为实际样本,红线为线性预测函数,对于任意给定新的样本自变量即可按照线性预测函数进行因变量
y的预测。直观理想情况下,样本"应该是"均匀分布在预测函数两侧,红色预测函数从蓝色样本"居中"位置穿过去。
下面进行从理论实现对上述"直观感觉"的推导
1.线性回归理论推导
- 预备定理
- 中心极限定理
设随机变量
X1,X2,…,Xn互相独立,服从同一分布,并且具有相同的期望
μ和方差
σ2,则随机变量
Yn=n
σ∑i=1nXi−nμ
的分布收敛到标准正态分布,即高斯分布。
转化一下,即可得到
∑i=1nXi收敛到正态分布
N(nμ,nσ2)
简言之,当样本量足够大时,样本均值的分布慢慢变成正态分布
- 极大似然估计
设总体分布为
f(x,θ),
X1,X2,…,Xn为该总体采样得到的样本。因为
X1,X2,…,Xn独立同分布,因此,对于联合密度函数
L(X1,X2,…,Xn;θ1,θ2,…,θk)=i=1∏nf(Xi;θ1,θ2,…,θk)
上式中,
θ被看作固定但待求解的参数;反过来,因为样本已经存在,可以看成
X1,X2,…,Xn是固定的,
L(x,θ)是关于
θ的函数,即似然函数。
求
θ的值,使得似然函数取极大值,这种方法就是极大似然估计
- 线性回归数学定义
对于
n维空间(或者可以通俗的描述为
n维特征)的
m个样本,每个样本对应一个因变量
y,即有
m个样本数据如下
(x11,x21,…,xn1,y1),(x12,x22,…,xn2,y2),…,(x1m,x2m,…,xnm,ym)
在上面样本的基础之上,任意给定一个新样本
(x1x,x2x,…,xnx),如何求得该样本对应的
yx呢?如果
y是连续的,这就是一个回归问题,如果
y是离散的,就是一个分类问题,本文暂讨论回归情况。
(对于本文初自变量只有一维的情况,线性回归目的是求得一条直线(
y=ax+b)的方程,需要确定的量有斜率(
a)和截距(
b)两个。同理对于n维度自变量的情况,线性回归需要求得的是直线的推广——超平面的方程。此时待确定的依然是斜率和截距两个变量,但此时斜率维数变为
n维)
对于上述
m个样本,给出线性回归的模型如下
hθ(x1,x2,…,xn)=θ0+θ1x1+θ2x2+⋯+θnxn
其中,
θ0为截距,
θi(i=1,2,…,n)唯一确定"斜率"(注:超平面使用更多的是法向量,与"斜率"是垂直关系)。为了更加表述更加简洁,我们在截距项上增加一个
x0,并且令
x0=1,上述线性回归模型可以全等写成
hθ(x1,x2,…,xn)=θ0x0+θ1x1+θ2x2+⋯+θnxn
即
hθ(x1,x2,…,xn)=i=1∑nθixi
进一步,采用矩阵表示
hθ(X
)=θ
TX
其中,
X
为
m×n维矩阵,
m为样本个数,
n为样本维数(同特征数),
θ
T为
n×1维向量,
hθ(X
)为
m×1维因变量。
- 线性回归推导-误差分布
对于上述已经给定的样本点
(x11,x21,…,xn1,y1),(x12,x22,…,xn2,y2),…,(x1m,x2m,…,xnm,ym)
它们是在所求线性回归
hθ(X
)=θ
TX
的"附近",并不一定在所求的线性回归超平面上。因此,我们将已有的
m个样本点代入线性回归方程中时,会产生一个上下浮动的误差(扰动),记为
ε。将所有样本点代入回归方程,得到
Y
=θ
TX
+ε
其中,
ε
是
m×1维向量,分别代表
m个样本相对于线性回归方程的上下浮动程度(误差)。
敲黑板! 上式中的误差
ε
是独立同分布的,由中心极限定理,误差分布服从均值为0,方差为某定值的正态分布,记方差为
σ2。
- 线性回归推导-最大似然与最小二乘
对于上面方程
Y
=θ
TX
+ε
即
ε
=Y
−θ
TX
对每个样本分开,有
εj=yj−θ
Tx
j
其中
j∈(1,2,…,m),
x
j为
1×n维向量(第
j个样本自变量取值),
yj为第
j个样本因变量取值,
εj为第
j个样本的误差,
θ
为
n×1维向量。
由上面中心极限定理,误差分布服从均值为0,方差为
σ2的正态分布,按照整体分布的概率密度函数进行展开
即
p(εj)=2π
σ1exp(−2σ2εj2)
将
εj=yj−θ
Tx
j代入右式,得到一个关于
θ的函数
p(yj∣xj;θ)=2π
σ1exp(−2σ2(yj−θ
Tx
j)2)
再将所有样本代入,极大似然函数为
L(θ)=∏j=1mp(yj∣xj;θ)
L(θ)=j=1∏m2π
σ1exp(−2σ2(yj−θ
Tx
j)2)
两边取对数,令
l(θ)=logL(θ)
l(θ)=logj=1∏m2π
σ1exp(−2σ2(yj−θ
Tx
j)2)
乘积的对数等于对数的和
l(θ)=j=1∑mlog2π
σ1exp(−2σ2(yj−θ
Tx
j)2)
在利用一次乘积的对数等于对数的和
l(θ)=mlog2π
σ1−σ21⋅21j=1∑m(yj−θ
Tx
j)2
可以看出等式右边第一项为常数,第二项前面的系数
σ21也为常数,对求极值点无影响。求
l(θ)极大似然估计点,即求
−21∑j=1m(yj−θ
Tx
j)2的极大值点,去掉负号,即求
21∑j=1m(yj−θ
Tx
j)2的极小值点,令
J(θ)=21j=1∑m(yj−θ
Tx
j)2
将
hθ(xj)=θ
Tx
j代入
J(θ)=21j=1∑m(yj−hθ(xj))2
上式第一项
yj为样本实际函数值,第二项
hθ(xj)为线性回归预测值,现在目的就是求这两个值的差的平方最小值。这就是最小二乘法的由来,原理很简单
目标函数=∑(样本值−预测函数值)2
其中,样本值就是实际观测样本的函数值,预测函数值就是线性回归函数值,目标函数就是机器学习中的损失函数。我们的求解目的就是求得使目标函数最小的线性回归函数值,也就完成了线性回归中
θ
的求解。
2.最小二乘法推导
将式
J(θ)=21j=1∑m(yj−hθ(xj))2
改为矩阵表示
J(θ)=21(X
θ
−Y
)T(X
θ
−Y
)
将转置放到括号里面
J(θ)=21(θ
TX
T−Y
T)(X
θ
−Y
)
相乘展开
J(θ)=21(θ
TX
TX
θ
−θ
TX
TY
−Y
TX
θ
+Y
TY
)
求梯度
∇(J(θ))=∇(21(θ
TX
TX
θ
−θ
TX
TY
−Y
TX
θ
+Y
TY
))
∇(J(θ))=21(2X
TX
θ
−X
TY
−(Y
TX
)T)
最后一项转置写开
∇(J(θ))=21(2X
TX
θ
−X
TY
−X
TY
)
合并
∇(J(θ))=21(2X
TX
θ
−2X
TY
)
∇(J(θ))=X
TX
θ
−X
TY
求梯度的驻点,令
∇(J(θ))=0,即
X
TX
θ
−X
TY
=0
X
TX
θ
=X
TY
最终得到参数
θ的解析式
θ=(X
TX
)
−1X
TY
上述推导需要用到
X
TX
的逆,因此要求
X
TX
满秩或者正定。然而现实任务中
X
TX
往往不是满秩的。例如有的任务会使用到大量特征,甚至特征的个数会超过样本数,此时
X
TX
显然不满秩。为此,引入正则项,对任意
λ>0,
X
TX
+λI正定,
I为单位阵。参数解析式优化为
θ=(X
TX
+
λI)−1X
TY
3.为什么不使用最小二乘法
上节对最小二乘法进行了理论上的推导,得到的结果可以说是很漂亮的,但是在实际的操作中却不常使用,原因如下:
-
X
TX
可能不是正定的,加入正则项可以解决;
-
X
TX
在数据量很大的时候计算量特别大;
- 最小二乘法只适应于线性回归;
- 回归问题常使用的方法有梯度下降法和牛顿法以及拟牛顿法等。
4.小结
本文从最简单一维样本情况引出线性回归的概念,进而使用中心极限定理说明样本点与回归函数值之间的误差的分布是服从均值为0的正态分布。使用最大似然估计推导出最小二乘法,然后利用梯度为0求出最小二乘的驻点。最终给出线性回归参数
θ的解析式。
如有不妥,请指示正,谢谢阅读!
作者:togetlife