这一次终于到了分析b站视频了。开始体会到写博客非常占用学技术的时间,但是还是希望能总结,沉淀下来。
b站分析结果文章:https://www.bilibili.com/read/cv523868/
工具:使用Webmaigc框架,DBUtils,C3P0连接池。
分析过程:b站的搜索页面是这样的。如果浏览器右键查看源代码,你会发现是动态页面,也就是从后台通过ajax等在某个路径加载获得数据
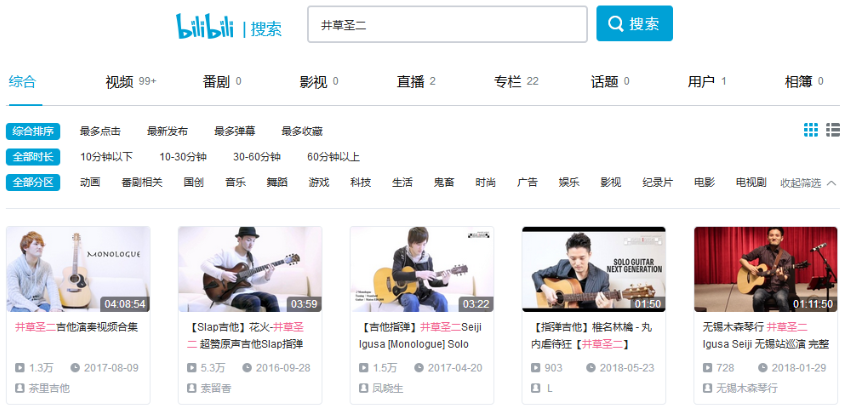
于是初入爬虫的我,打算贪方便试一下selenium模拟浏览器行为,结果效果不太好。当时是b站的搜索页面经常显示的是 出错啦,后来我就苦苦思索,我通过b站的页面在F12开发者工具里,从请求路径里找到了b站视频的搜索url,https://search.bilibili.com/api/search,当时还是很激动的!
从这个路径进去,发现b站视频的数据实际上是一个大Json,通过看webmagic文档知道了它提供了JsonPath的拿取方法。于是就按JsonPath拿数据,原本是用xpath在html里拿数据。
先贴一下我的processor核心代码:
1 public class BilibiliSearchProcessor implements PageProcessor{ 2 private Site site = Site.me().setUserAgent("Mozilla/5.0 (Windows NT 10.0; …e/59.0.3071.109 Safari/537.36") 3 .setRetryTimes(3) 4 .setTimeOut(30000) 5 .setSleepTime(1800) 6 .setCycleRetryTimes(3) 7 .setUseGzip(true) 8 .addHeader("Host","search.bilibili.com") 9 .addHeader("Accept","text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8") 10 .addHeader("Accept-Language","zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2") 11 .addHeader("Accept-Encoding","gzip, deflate, br") 12 ; 13 private static final String man = "Pierre Bensusan"; 14 private static final String defineUrl = "https://search.bilibili.com/api/search?search_type=video&keyword="+man+"&from_source=banner_search&order=totalrank&duration=0&tids=0"; 15 //"井草圣二","伍伍慧","押尾光太郎","岸部真明","松井佑贵","小松原俊","郑成河","depapepe","Pierre Bensusan","TOMMY EMMANUEL","Daniel Padim","andy mckee"}; 16 public void process(Page page) { 17 int numPage = Integer.parseInt(page.getJson().jsonPath("$.numPages").get()); 18 for (int i=0;i<numPage;i++) { 19 page.addTargetRequest(defineUrl+"&page="+(i+2)); 20 } 21 //up主 22 List<String> ups = page.getJson().jsonPath("$..author").all(); 23 page.putField("author", ups); 24 //标题 25 List<String> titles = page.getJson().jsonPath("$..title").all(); 26 page.putField("title", titles); 27 //链接 28 List<String> srcLinks = page.getJson().jsonPath("$..arcurl").all(); 29 page.putField("srcLinks", srcLinks); 30 //时长 31 List<String> durations = page.getJson().jsonPath("$..duration").all(); 32 page.putField("duration", durations); 33 //观看数 34 List<String> watchNums = page.getJson().jsonPath("$..play").all(); 35 page.putField("watchNum", watchNums); 36 //上传时间 2017-08-09 1502222633 37 // 2016-09-28 1475053142 38 //2018-05-18 1526650568 39 List<String> uploadTimes = page.getJson().jsonPath("$..pubdate").all(); 40 page.putField("uploadTime", uploadTimes); 41 //review 42 List<String> reviews = page.getJson().jsonPath("$..review").all(); 43 //video_review 44 List<String> video_reviews = page.getJson().jsonPath("$..video_review").all(); 45 //favorite 46 List<String> favorites = page.getJson().jsonPath("$..favorites").all(); 47 //视频说明 48 List<String> description = page.getJson().jsonPath("$..description").all(); 49 page.putField("description", description); 50 for (int i=0;i<ups.size();i++) { 51 BiliVideosDao.save(man,ups.get(i),SimpleUtil.cutHtml(titles.get(i)),srcLinks.get(i),durations.get(i),watchNums.get(i) 52 , SimpleUtil.convert2String(1000*Long.parseLong(uploadTimes.get(i))), 53 reviews.get(i),video_reviews.get(i),favorites.get(i),description.get(i)); 54 } 55 } 56 57 public Site getSite() { 58 return site; 59 } 60 61 public static void main(String[] args) { 62 Spider.create(new BilibiliSearchProcessor()) 63 //.addUrl(urls) 64 .addUrl(defineUrl) 65 .addPipeline(new ConsolePipeline()) 66 .thread(5) 67 .run(); 68 } 69 }
有几个当时遇到的要点讲一下:
第一是site的header一定要加!!没有为什么,一定要加,因为要模拟更真实的浏览器访问!
第二是site的爬取频率,b站还是有限制的,.setSleepTime(1800)这样就可以了,不会太快。
第三是b站视频爬的pubdate也就是上传时间,实际上是秒为单位,但是平时java里转换用的是毫秒,当晚我没想明白这个数字该怎么转换成date格式,第二天早上突然就发现了,真是感恩。
另外,json里拿到title实际上带有关键词的高亮,于是写了个cutHtml的方法去replace.
第四是header的host要加对,我当时用selenium有时成功有时失败,我后来改成直接拿Json的时候突然发现我Host之前写的地址好像不对劲,不是search.bilibili.com,现在才渐渐明白估计也是参数错了.
第五是能分析动态分析页面,尽量分析,因为用selenium速度还是不快的,而且会造成java程序结束,chrome进程却没有退出的情况(开发者估计也还没优化!)
1 public class SimpleUtil { 2 // 短日期格式 3 public static String DATE_FORMAT = "yyyy-MM-dd"; 4 5 /** 6 * 将长整型数字转换为日期格式的字符串 7 * 8 * @param time 9 * @return 10 */ 11 public static String convert2String(long time) { 12 if (time > 0l) { 13 SimpleDateFormat sf = new SimpleDateFormat(DATE_FORMAT); 14 Date date = new Date(time); 15 return sf.format(date); 16 } 17 return ""; 18 } 19 20 public static String cutHtml(String str){ 21 return str.replaceAll("</?[^>]+>", ""); 22 } 23 }
Dao就不贴了,直接用DBUtils,QueryRunner执行sql语句save一个数据对象.
有什么疑问可以发我邮箱[email protected]