这个b站之前一直想爬,看了几篇关于这个的博客,发现好难,今天耐不住就找了比较新的一篇博客讲述爬取b站视频。本来以为还要破解js加密获取加密参数,发现并没有这么复杂,视频下载的连接都在网页里保存,ε=(´ο`*)))唉。话不多说开始搞起。
所需环境:pycharm+python3.6+requests+re+pyquery+fiddler (re是提取网页里面下载的连接,其他的都不好提取出来,pyquery是提取打开视频的网页url)
1 分析api:
随便打开个视频网页,打开fiddler查看http请求,等了一会(要几分钟)fiddler才出现视频的资源。
这个就是加载的资源。

查看他的请求头:
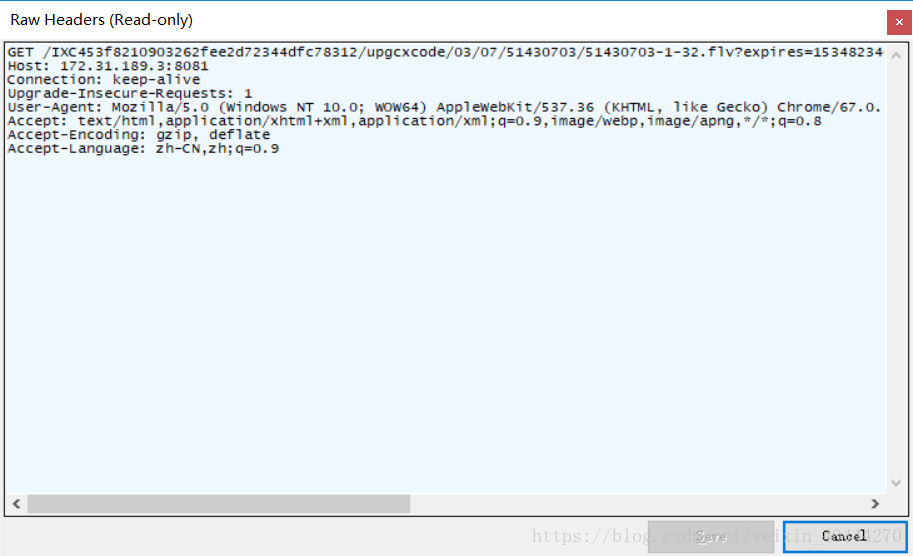
先写一个简单的程序,url填写这个MP4的地址,等待一段时间发现可以下载
def download(url):
url='http://172.31.189.3:8081/IXC453f8210903262fee2d72344dfc78312/upgcxcode/03/07/51430703/51430703-1-32.flv?hfa=2034783019'
headers={
'Host': '172.31.189.3:8081',
'Connection':'keep-alive',
'Upgrade-Insecure-Requests': '1',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.62 Safari/537.36',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language':'zh-CN,zh;q=0.9'
}
h=requests.get(url=url,headers=headers,verify=False)
with open('信息.mp4','wb') as f:
f.write(h.content)
print('下载完成')
然后我们开始寻找这个url,这个要么是js产生,要么网页源码里就有,从简单开始验证,打开网页源代码,发现许多,随便复制粘贴一个,在浏览器打开,发现是在下载视频。那就直接找到了,真没意思,(这个url可能时间长了过期,我也没有验证)

代码:
from pyquery import PyQuery as pq
import requests
import re
def download():
url='http://cn-jszj-dx-v-06.acgvideo.com/upgcxcode/24/16/47791624/47791624-1-32.flv?expires=1534830300&platform=pc&ssig=d-qNS9b7EeC8itVRtJHWOQ&oi=976830102&nfa=uTIiNt+AQjcYULykM2EttA==&dynamic=1&hfa=2034806275&hfb=Yjk5ZmZjM2M1YzY4ZjAwYTMzMTIzYmIyNWY4ODJkNWI=&trid=d65441f273b6440bbe3d2a57bcb5c66a&nfc=1'
headers={
'Connection':'keep-alive',
'Upgrade-Insecure-Requests': '1',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.62 Safari/537.36',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language':'zh-CN,zh;q=0.9'
}
h=requests.get(url=url,headers=headers,verify=False)
with open('信息2.mp4','wb') as f:
f.write(h.content)
print('下载完成')
def getHtml(url):
headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.62 Safari/537.36'
}
html=requests.get(url,headers,verify=False)
return html.text
def getListUrl(txt):
doc=pq(txt)
items=doc('#app > div.b-page-body > div > div.rank-container > div.rank-body > div.rank-list-wrap > ul > li > div.content > div.info > a').items()
list=[]
for item in items:
dic={}
title=item.text()
href=item.attr('href')
dic[title]=href
list.append(dic)
return list
def parse_get_url(txt):
pattern=re.compile(r'window.__playinfo__={(.*?)}',re.S)
content=re.findall(pattern,txt)
p=re.compile(r'"url":"(.*?)",',re.S)
url=re.findall(p,content[0])
print(url)
return url
def save_toFile(txt):
f=open("b站热门排行视频.txt",'a',encoding='utf-8')
f.write(txt)
f.write('\n')
f.close()
if __name__ == '__main__':
t=getHtml('https://www.bilibili.com/ranking?spm_id_from=333.334.banner_link.1')
urls=getListUrl(t)
for url in urls:
dic={}
print(type(url))
for title in url:
print(title)
url=list(url.values())[0].replace('//','')
print(url)
url='https://'+url
t=getHtml(url)
certainUrl=parse_get_url(t)
dic[title]=certainUrl
save_toFile(dic.__str__())
我并没有使用下载的那个函数,只是保存了标题和下载地址。