前言
自己学习python的初衷就是为了能在支持micropython的芯片上编程,比如早期接触到的openmv,以及拥有arm linux环境的树莓派上(树莓派的python不是micropython)还有后面接触到的esp32和esp8266上编写程序。于是乎进入了python编程的自学行列,经过一段时间在b站看小甲鱼视频后自己的基础知识方面知道的差不多了,后面就想着运用到实际上。于是就接触python最经典的东西“爬虫”,一开始学习爬虫的时候是在mooc跟着嵩天老师学习的,讲到关于requests和bs4在内的很多爬虫。自己也慢慢的有了进步,但是在自己想依靠爬虫去白嫖“百度文库”的时候第一次碰壁,自己爬取的内容是空的。很奇怪,明明自己按了F12后能看到文字在html后面怎么爬虫就爬取的是空呢?后来几经百度发现它的页面是通过js渲染的,而requests库能得到的就是原始的html页面,于是也就只能不了了之。时过境迁,后来我准备利用esp32里的micropython制作一个up主点赞关注的显示机的时候,又碰到了这个问题,我也百度过也知道它百度后能查到它的api,但是这次我想亲自分析出这个api,也为我爬虫学习画上一个小句号
方法一:selenium库
关于这个selenium库,是一个网页自动化的库,个人理解就是做网页脚本的一个好用的库,这里如果用它做爬虫的话能够获取渲染过后的结果,它pip下载之后还要去安装对应的网页驱动比如我就是用的是谷歌浏览器的驱动,这里推荐一篇博文windows环境下安装selenium这里要说的是要会看自己浏览器的版本去下对应的驱动,chrome是在【帮助】->【关于Google chrome】里面
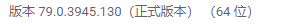
这是我的版本。
在你要爬取的地方右击然后copy Xpath就行了
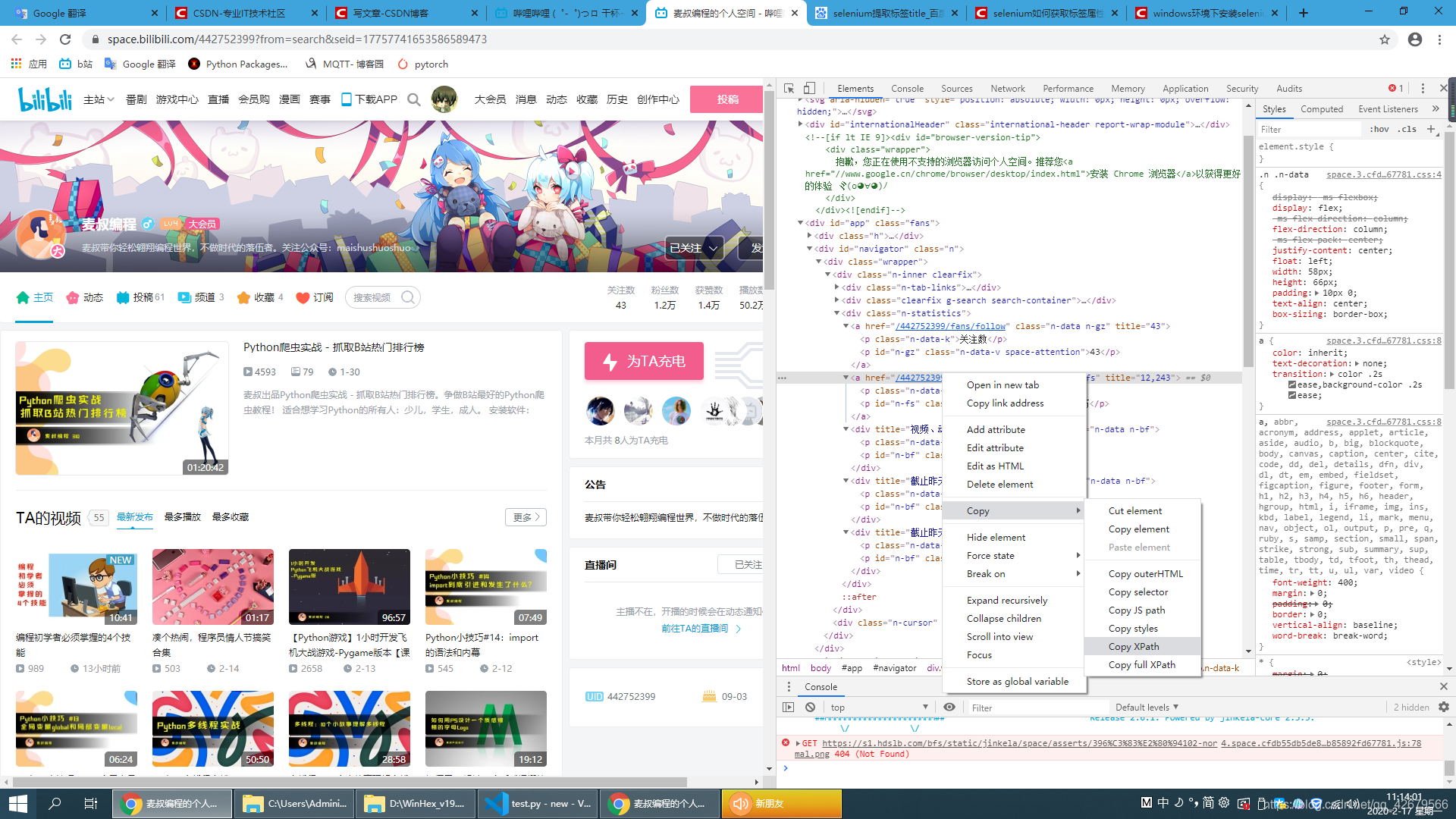
后面的我就贴出代码来了
from selenium import webdriver
Browser = webdriver.Chrome()
Browser.get("https://space.bilibili.com/442752399?from=search&seid=17757741653586589473")
content = Browser.find_element_by_xpath('//*[@id="navigator"]/div/div[1]/div[3]/a[2]')
print("粉丝数:",content.get_attribute("title"),content.text)
Browser.close()
方法二:分析出api
实际上对于micropython来说并不是python它没有那么丰富的库,不过最基础的requests库还是有的(micropython里叫urequests库)那么这么基础的库我们就只能抓它的api了,于是就要对网页数据包进行分析。
按下F12后首先我对一个数字产生了兴趣那就是粉丝数12243这个数字那么如果有数据包,数据包就必然有这个数字(前提是没做加密处理的情况),然后我就习惯性的去network里面的XHR找,
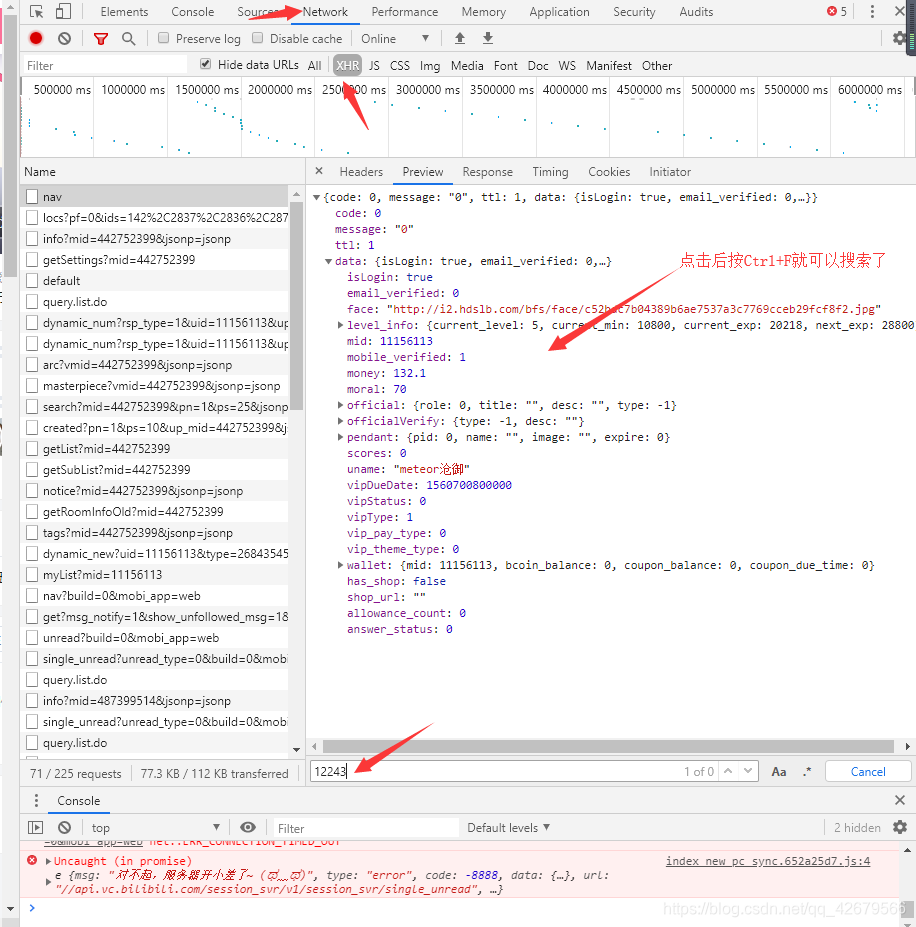
结果找了一圈没找到,后来进入了,Sources里搜索这个数字
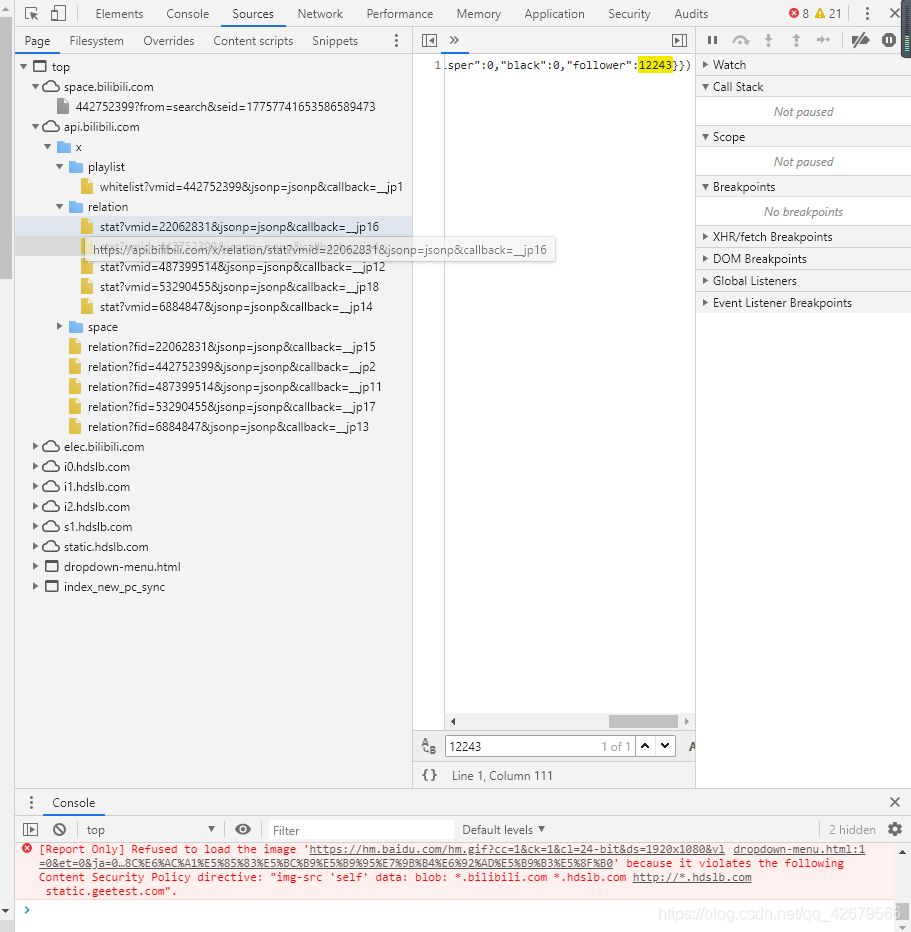
终于在这里找到了,但是当我右键open in new tab的时候
结果就是无法访问,最后分析url后我i选择删除&callback=__jp4后发现成功返回json

至此它的api就分析出来啦,下面贴出源码
import requests
uid = input('please input your uid:')
url = 'https://api.bilibili.com/x/relation/stat?vmid=%s&jsonp=jsonp'%(uid)
r = requests.get(url)
print(r.json()["data"]["follower"])
总结
以上就是自己的两种方法,第一种适合pc,但是相对看、来说可能局限性很大。第二种很明显就是要抓取源数据的url,这里通过一些手段获得相应的url后对url分析后获取真正的url,虽然很简单但是写出了自己的心路历程,算是给后来的人少走弯路吧。
