版权声明:所有源码仅供参考学习使用,请勿用作违法犯罪活动 https://blog.csdn.net/Tomsidi/article/details/81489871
简单的爬取B站视频评论
技术不足还请大神多多包涵
说一下写这篇博客的缘由,我弄了半天终于把爬取程序写好了,把爬取的数据一部分在某个QQ群中展示一下,结果就出现了以下几个奇葩



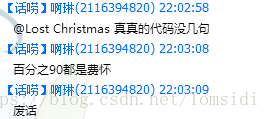

可能这就是键盘侠吧
整理一下心情我们回归正题
B站的视频评论区需要滑动窗口滚动条才能被加载出来,代码放在了js中,因此,如果直接用Requests的get方法无法获取评论区源码,如果有大佬会的可以在评论区留言。
这里我使用selenium中的webdriver方法实现组件元素交互。
import re
import requests
from selenium import webdriver
from requests.exceptions import RequestException
import time
# 获取评论第一页的源码
def get_first_page_source(url,content_list):
browser = webdriver.Chrome()
browser.get(url)
browser.execute_script('window.scrollBy(0,2000)')#调用js代码实现滑动
time.sleep(4)#等待加载完毕
content_list.append(browser.page_source)
return browser.page_source
# 获取评论总页数
def get_max_size_page_info(html):
pattern = re.compile('<div.*?header-page.*?result">共(\d+)页</span>',re.S)
return re.findall(pattern,html)[0]
# 获取其他页的源码
def get_more_page_source(url,content_list):
browser = webdriver.Chrome()
# browser.set_window_size(1000,30000)
browser.get(url)
browser.execute_script('window.scrollBy(0,2000)')#调用js代码实现滑动
time.sleep(4)#等待加载完毕
content_list.append(browser.page_source)
max_size = int(get_max_size_page_info(get_first_page_source(url,content_list)))
for i in range(max_size-1):
next_btn = browser.find_element_by_css_selector('div.comment-header div.header-page a.next')#使用css选择器选择下一页a标签
next_btn.click()
time.sleep(1.5)
content_list.append(browser.page_source)
# 获取评论信息
def get_comment(content):
# 使用正则表达式匹配
pattern = re.compile('<div.*?list-item.*?data-id="(\d+)".*?con.*?">.*?data-usercard-mid="(\d+)".*?name.*?">'
+ '(.*?)</a>.*?<p.*?text">(.*?)</p>.*?</div>.*?</div>',re.S)
for item in content:
info = re.findall(pattern,item)
for info_item in info:
# 使用生成器规范化数据
yield {
'comment_id':info_item[0],
'user_id':info_item[1],
'user_name':info_item[2],
'comment_text':info_item[3]
}
# return info
def main():
url = '填写需要爬的视频页网址'
comment_list = []
get_more_page_source(url,comment_list)
get_comment(comment_list)
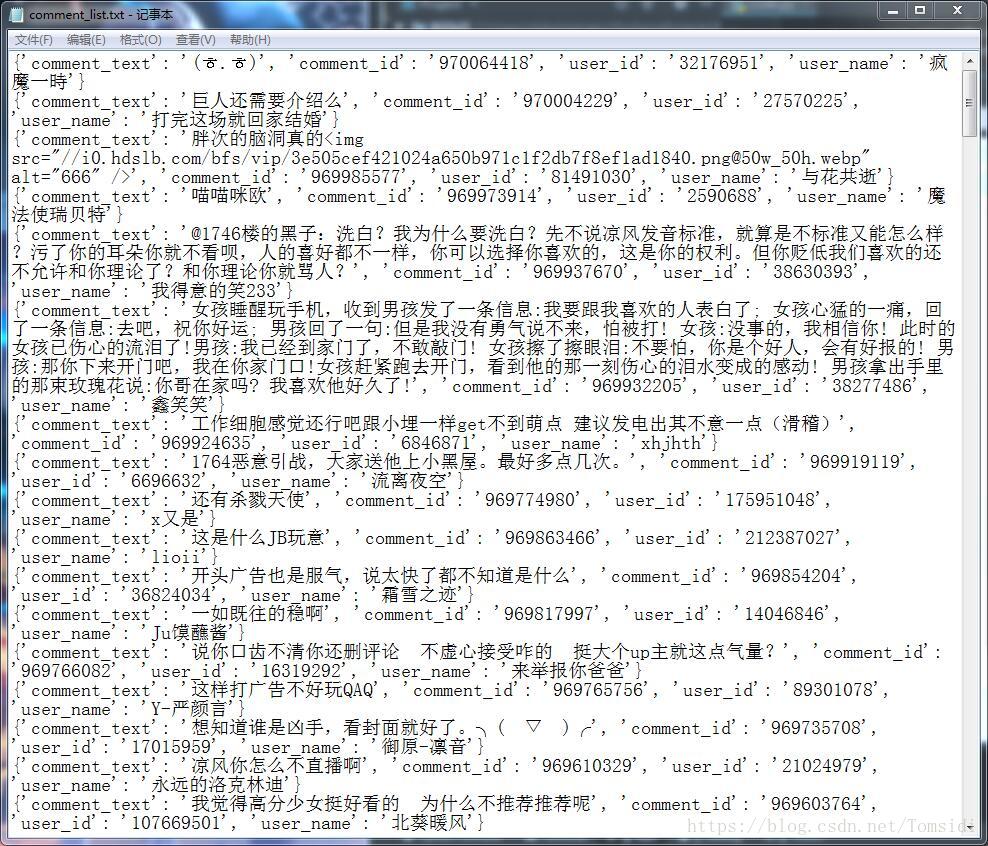
with open('D://comment_list.txt','a',encoding='utf-8') as f:
for item in get_comment(comment_list):
f.write(str(item) + '\n')
print(len(comment_list))
if __name__ == '__main__':
main()部分输出数据
