起因
作为一个B站的忠实粉丝,每天睡前和起床刷一下视频那是必须的。不过一般我都是在手机上刷,昨天用电脑刷的时候本来想下载一个视频,但是发现网页居然没有app的缓存功能,所以无奈只能自己动手写一个来下载视频了。(本来昨晚写完,辛辛苦苦还录了视频给B站投稿的,结果今天说内容违规无奈)
一步步实现
方法一

这是我看的视频的页面,然后F12,去找视频网址
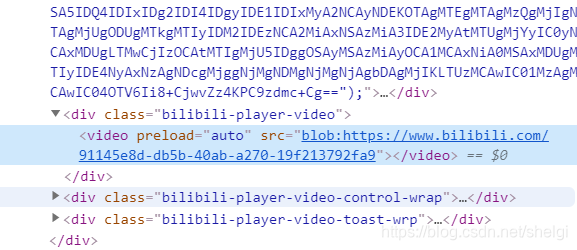
发现是blob加密的,网上很多关于blob解密的博客,帖子。但是最后都是返回很多ts然后再拼接,那有没有直接得到的呢?再去network里面看看视频播放的时候的加载内容,发现了这个
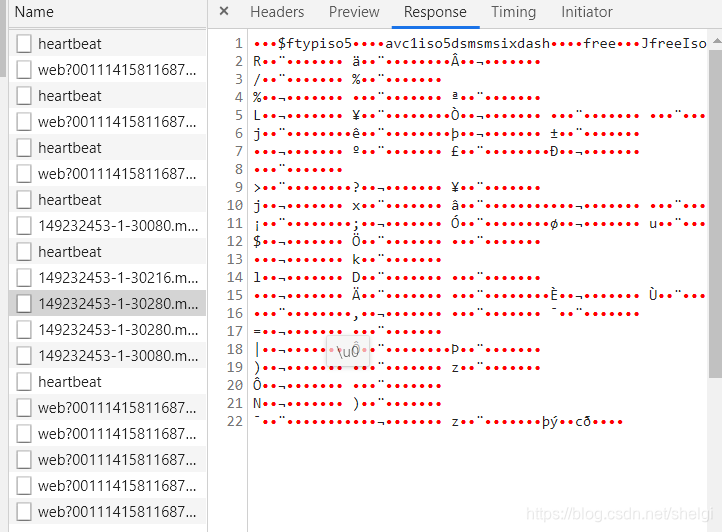
有很多这种,一看就是视频文件的乱码,所以我们要去访问这个网址得到这些内容再保存到本地就行了。所以我们要去找这个网址,我发现网页里面其实就有。
ctrl+F去网页搜索m4s,发现了这些
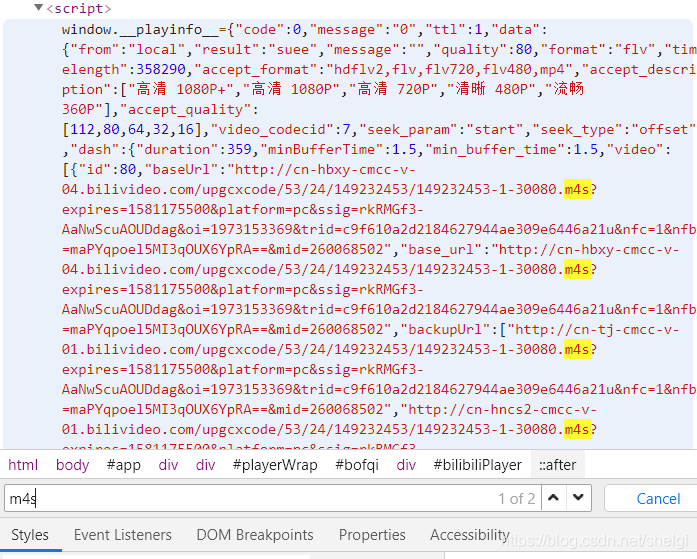
接下来正则匹配到网址就好,不过保存文件的时候一开始我是用m4s格式,后来发现打不开,所以把文件格式改成flv保存。
方法二
大致思路和上面一样,只是我在network中找到了一个api
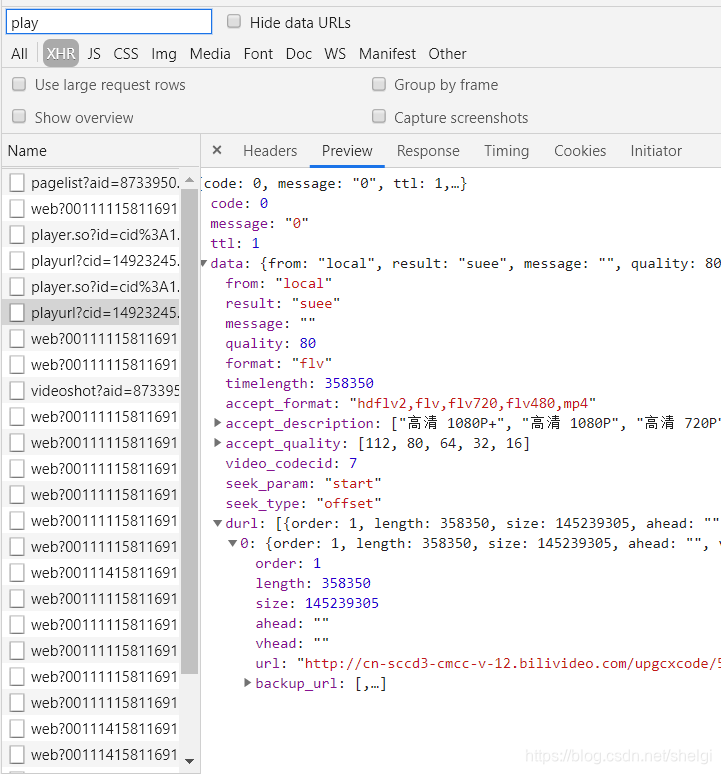
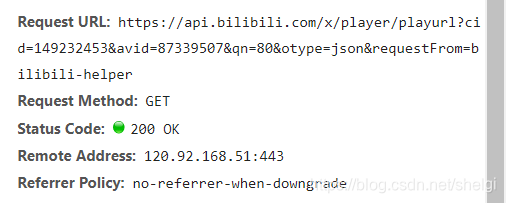
所以第二种实现就是访问这个网页,从返回的json中提取url,然后再去访问url,保存成文件。
代码
这个代码是第一种方法的代码,第二种也很简单,可以自己动手试一下,只要注意headers参数就好
import requests
import re
def get_html(url):
return requests.get(url,headers=headers1).text
def parse(html):
video_name=re.findall('<span class="tit">(.*?)</span>',html,re.S)[0]+'.flv'#本来是m4s,但是电脑打不开所以还是用flv
print("正在爬取"+video_name+"...")
video_url=re.findall('window.__playinfo__={.*?"baseUrl":"(.*?)".*?}',html,re.S)[0]
# print(video_url)
return video_url,video_name
def download(videourl,video_name):
with open(video_name,'wb') as f:
f.write(requests.get(videourl,headers=headers2,stream=True,verify=False).content)
f.close()
print("视频下载完成!")
if __name__ == '__main__':
avid=input("请输入要爬取的视频id:")
base_url=f'https://www.bilibili.com/video/av{avid}'
headers1={
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36',
'Host': 'www.bilibili.com',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'Accept-Encoding':'gzip, deflate, br',
'Accept-Language':'zh-CN,zh;q=0.9',
'Cache-Control': 'max-age=0',
'Connection': 'keep-alive'
}
headers2={
'Host':'cn-jsnj3-cmcc-v-14.bilivideo.com',
'Accept-Encoding':'identity',
'Accept-Language':'zh-CN,zh;q=0.9',
'Origin':'https://www.bilibili.com',
'Referer':base_url,
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36'
}
html=get_html(base_url)
videourl,videoname=parse(html)
download(videourl,videoname)
结果
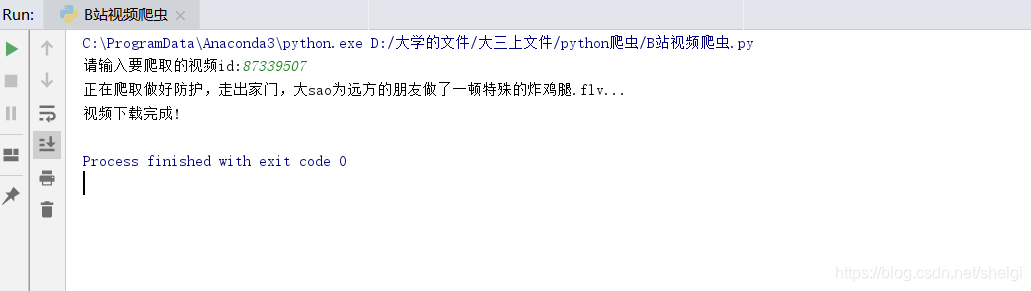
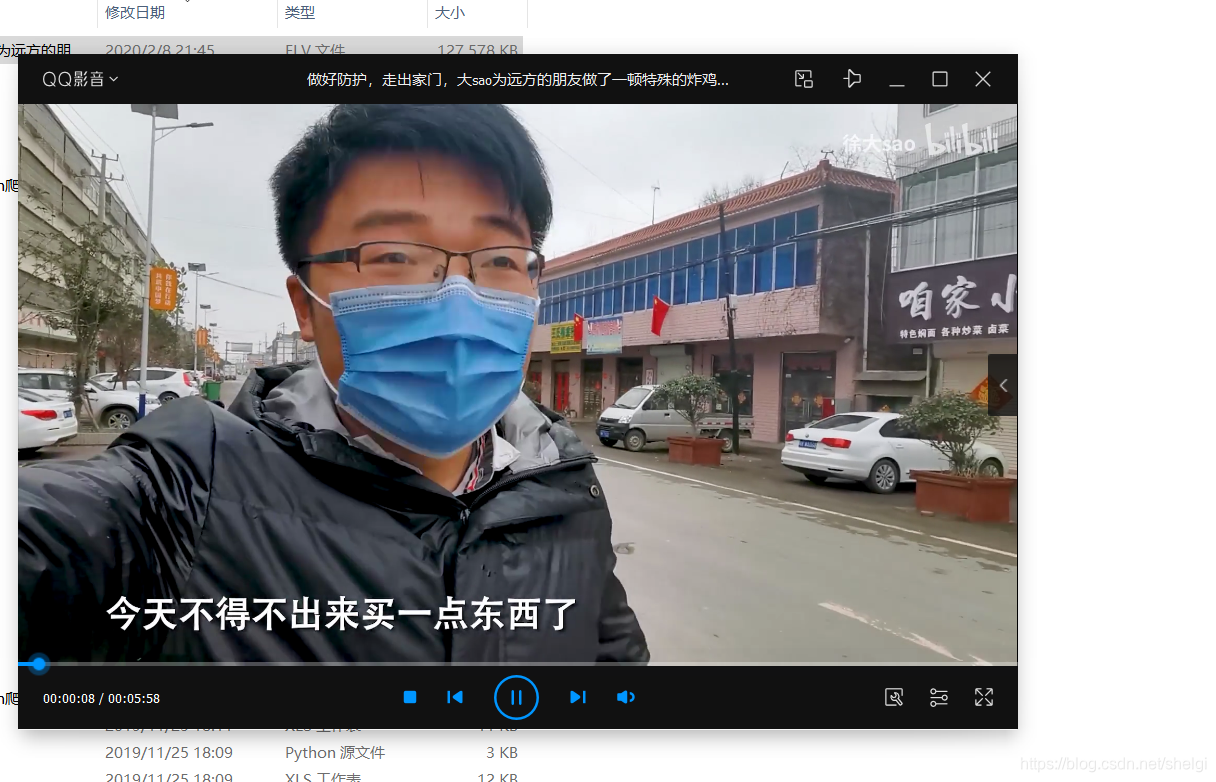
缺点和改进:缺点就是没有声音,音频部分的爬取和视频整合还要再想想,另外可以从首页匹配所有的视频id然后循环爬取所有的视频,以及一些线程也可以加进去。
最后
白嫖只是说着玩玩,循环爬取也不可取,不要给服务器太大压力。B站up主们做视频也很不容易,我们可以从丰富的优质内容视频中学到很多东西,所以拒绝下次一定,不做白嫖党!!!
