第十四章 自编码器
自编码器是一种无监督的数据维度压缩和数据特征表达方法。
自编码器已成功应用于降维和信息检索任务。
自编码器是神经网络的一种,经过训练后能尝试将输入复制到输出。 自编码器内部有一个隐藏层 ,可以产生编码表示输入。该网络可以看作由两部分组成:
- 一个由函数 表示的编码器
- 一个生成重构的解码器
下图是一个自编码器。自编码的目标便是优化损失函数L(x,g(f(x)),也就是减小图中的Error。
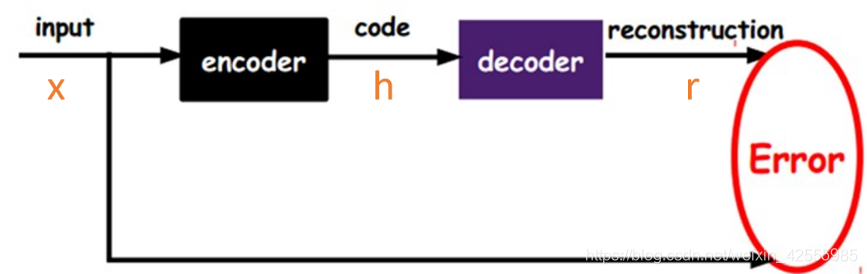
如果一个自编码器只是简单地学会将每个地方都设置为g(f(x))=x,那么这个自编码器就没什么特别的用处。相反,我们不应该将自编码器设计成输入到输出完全相等。这通常需要向自编码器强加一些约束,使它只能近似地复制,并只能复制与训练数据相似的输入。这些约束强制模型考虑输入数据的哪些部分需要被优先复制,因此它往往能学习到数据的有用特性。
普通自编码器存在的问题
在普通的自编码器中,输入和输出是完全相同的,因此输出对我们来说没有什么应用价值,所以我们希望利用中间隐层的结果,比如,可以将其作为特征提取的结果、利用中间隐层获取最有用的特性等。
但是如果只使用普通的自编码器会面临什么问题呢?比如,输入层和输出层的维度都是5,中间隐层的维度也是5,那么我们使用相同的输入和输出来不断优化隐层参数,最终得到的参数可能是这样:x1−>a1,x2−>a2,…x1−>a1,x2−>a2,…的参数为1,其余参数为0,也就是说,中间隐层的参数只是完全将输入记忆下来,并在输出时将其记忆的内容完全输出即可,神经网络在做恒等映射,产生数据过拟合。如下图所示
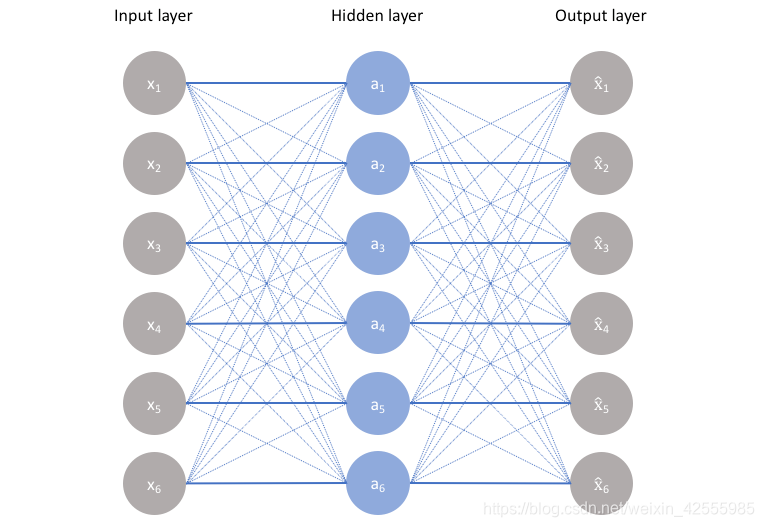
上图是隐层单元数等于输入维度的情况,当然,如果是隐层单元数大于输入维度,也会发生类似的情况,即当隐层单元数大于等于输入维度时,网络可以采用完全记忆的方式,虽然这种方式在训练时精度很高,但是复制的输出对我们来说毫无意义。
因此,我们会给隐层加一些约束,如限制隐藏单元数(欠完备自编码器)、添加正则化(正则自编码器)等
现代自编码器将编码器和解码器的概念推而广之,将其中的确定函数推广为随机映射 和 。
传统自编码器被用于降维或特征学习。 近年来,自编码器与潜变量模型理论的联系将自编码器带到了生成式建模的前沿。
自编码器可以被看作是前馈网络的一个特例,并且可以使用完全相同的技术进行训练,通常使用小批量梯度下降法(其中梯度基于反向传播计算)。
不同于一般的前馈网络,自编码器也可以使用再循环训练,这种学习算法基于比较原始输入的激活和重构输入的激活。 相比反向传播算法,再循环算法更具生物学意义,但很少用于机器学习应用。
自编码器和前馈神经网络的比较
(1)自编码器是前馈神经网络的一种,最开始主要用于数据的降维以及特征的抽取,随着技术的不断发展,现在也被用于生成模型中,可用来生成图片等。
(2)前馈神经网络是有监督学习,其需要大量的标注数据。自编码器是无监督学习,数据不需要标注因此较容易收集。
(3)前馈神经网络在训练时主要关注的是输出层的数据以及错误率,而自编码的应用可能更多的关注中间隐层的结果。
欠完备自编码器(Undercomplete Autoencoder)
将输入复制到输出听起来没什么用,但我们通常不关心解码器的输出。 相反,我们希望通过训练自编码器对输入进行复制而使 获得有用的特性。
从自编码器获得有用特征的一种方法是限制
的维度比
小,这种编码维度小于输入维度的自编码器称为欠完备自编码器。 学习欠完备的表示将强制自编码器捕捉训练数据中最显著的特征。
学习过程可以简单地描述为最小化一个损失函数
其中
是一个损失函数,惩罚
与
的差异,如均方误差。
欠完备自编码器如下图所示。(以下解释来自推荐,比书上通俗易懂)
由上述自编码器的原理可知,当隐层单元数大于等于输入维度时,网络会发生完全记忆的情况,为了避免这种情况,我们限制隐层的维度一定要比输入维度小,这就是欠完备自编码器。
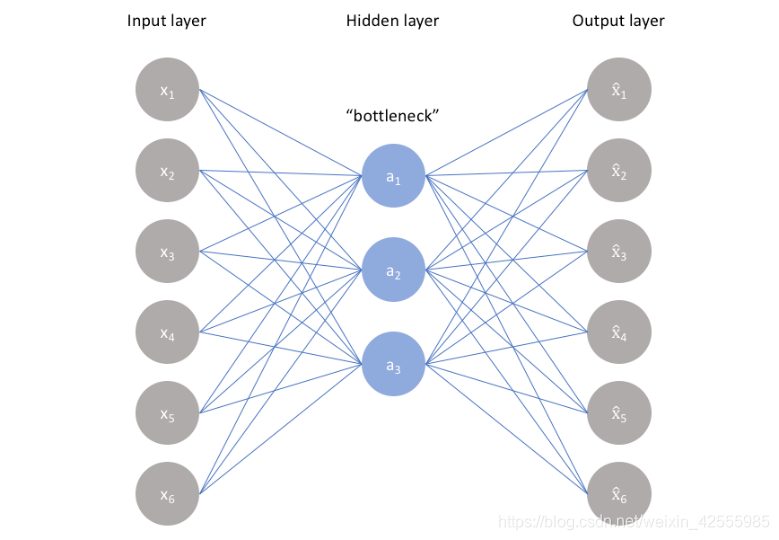
学习欠完备的表示将强制自编码器捕捉训练数据中最显著的特征。
欠完备自编码器和主成分分析(PCA)的比较
实际上,若同时满足下列条件,欠完备自编码器的网络等同于PCA,其会学习出于PCA相同的生成子空间:
- 每两层之间的变换均为线性变换。
- 目标函数L(x,g(f(x))为均方误差。
因此,拥有非线性编码器函数 和非线性解码器函数 的自编码器能够学习出更强大的PCA非线性推广。
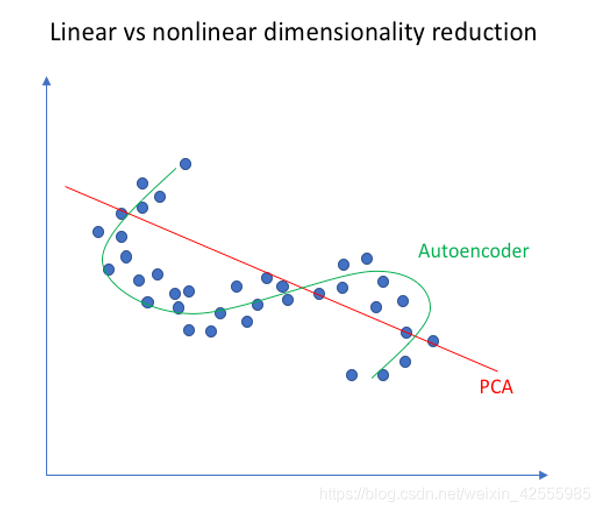
下图是在二维空间中PCA算法和自编码器同时作用在二维点上做映射的结果,从图中可以看出,自编码器具有更好的表达能力,其可以映射到非线性函数。
欠完备自编码器特点
- 防止过拟合,并且因为隐层编码维数小于输入维数,可以学习数据分布中最显著的特征。
- 若中间隐层单元数特别少,则其表达信息有限,会导致重构过程比较困难。
