第十四章 自编码器
2020-3-8 深度学习笔记14 - 自编码器 1(欠完备自编码器)
正则自编码器Regularized Autoencoders
编码维数小于输入维数的欠完备自编码器可以学习数据分布最显著的特征。 我们已经知道,如果赋予这类自编码器过大的容量,它就不能学到任何有用的信息。
如果隐藏编码的维数允许与输入相等,或隐藏编码维数大于输入的过完备情况下,会发生类似的问题。 在这些情况下,即使是线性编码器和线性解码器也可以学会将输入复制到输出,而学不到任何有关数据分布的有用信息。
理想情况下,根据要建模的数据分布的复杂性,选择合适的编码维数和编码器、解码器容量,就可以成功训练任意架构的自编码器。 正则自编码器提供这样的能力。
正则自编码器使用的损失函数可以鼓励模型学习其他特性(除了将输入复制到输出),而不必限制使用浅层的编码器和解码器以及小的编码维数来限制模型的容量。 这些特性包括稀疏表示、表示的小导数、以及对噪声或输入缺失的鲁棒性。
即使模型容量大到足以学习一个无意义的恒等函数,非线性且过完备的正则自编码器仍然能够从数据中学到一些关于数据分布的有用信息。
1-1稀疏自编码器(Sparse Autoencoder)
稀疏自编码器是加入正则化的自编码器,它没有限制网络接收数据的能力,即不限制隐藏层的单元数。
稀疏性限制是指:若激活函数是sigmoid,则当神经元的输出接近于1的时候认为神经元被激活,输出接近于0的时候认为神经元被抑制。使得大部分神经元别抑制的限制叫做稀疏性限制。若激活函数是tanh,则当神经元的输出接近于-1的时候认为神经元是被抑制的。
补充:稀疏限制和L1/L2正则化的关系
①稀疏限制是对激活函数的结果增加限制,使得尽量多的激活函数的结果为0(如果激活函数是tanh,则为-1)
②L2/L1是对参数增加限制,使得尽可能多的参数为0。
若自编码器编码函数f(wx+b),若f是一个线性函数,则编码器便可以写成wx+b,限制激活函数的结果尽量为0,即是限制w尽量为0,此时稀疏限制和正则化限制相同。

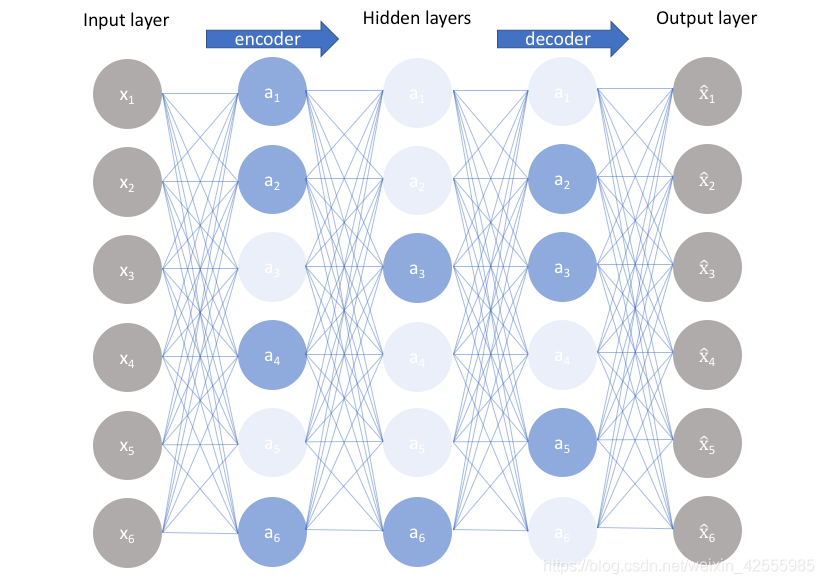
如上图所示,浅色的神经元表示被抑制的神经元,深色的神经元表示被激活的神经元。通过稀疏自编码器,我们没有限制隐藏层的单元数,但是防止了网络过度记忆的情况。
稀疏自编码器简单地在训练时结合编码层的稀疏惩罚
和重构误差,其损失函数的基本表示形式如下:
其中
是解码器的输出,通常
是编码器的输出,即
。
稀疏自编码器一般用来学习特征,以便用于像分类这样的任务。 稀疏正则化的自编码器必须反映训练数据集的独特统计特征,而不是简单地充当恒等函数。 以这种方式训练,执行附带稀疏惩罚的复制任务可以得到能学习有用特征的模型。
我们可以简单地将惩罚项 视为加到前馈网络的正则项,这个前馈网络的主要任务是将输入复制到输出(无监督学习的目标),并尽可能地根据这些稀疏特征执行一些监督学习任务(根据监督学习的目标)。

上述过程是稀疏自编码器在分类中的应用,它不是一次训练的。
可以看到上面只有编码器没有解码器,因此其训练过程是自编码器先使用数据训练参数,然后保留编码器,将解码器删除并在后面接一个分类器,并使用损失函数来训练参数已达到最后效果。
1-2.去噪自编码器(Denoising Autoencoder)
除了向代价函数增加一个惩罚项,我们也可以通过改变重构误差项来获得一个能学到有用信息的自编码器。
去噪自编码器是一类接受损失数据作为输入,并训练来预测原始未被损坏的数据作为输出的自编码器。
传统的自编码器最小化以下目标
其中
是一个损失函数,惩罚
与
的差异,如它们彼此差异的
范数。 如果模型被赋予过大的容量,
仅仅使得
学成一个恒等函数。
相反,去噪自编码器最小化
其中
是被某种噪声损坏的
的副本。 因此去噪自编码器必须撤消这些损坏,而不是简单地复制输入。
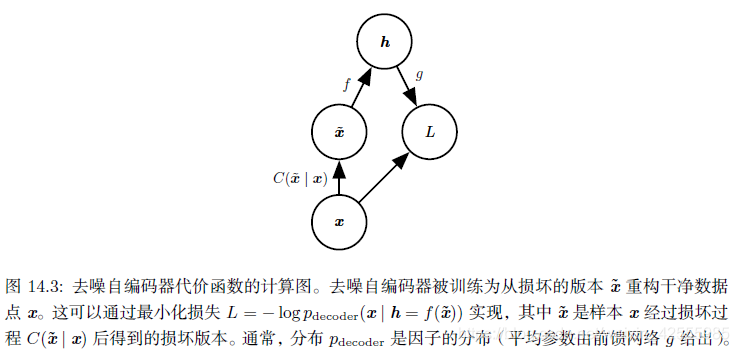
去噪自编码器其训练过程如下:
引入一个损坏过程
,这个条件分布代表给定数据样本x产生损坏样本
的概率。自编码器学习重构分布
- 从训练数据中采一个训练样本x
- 从 采一个损坏样本
- 将 作为训练样本来估计自编码器的重构分布 ,其中h是编码器 的输出,pdecoder根据解码函数g(h)定义。
去噪自编码器的直观解释是:和人体感官系统类似,比如人的眼睛看物体时,如果物体的某一小部分被遮住了,人依然能够将其识别出来,所以去噪自编码器就是破坏输入后,使得算法学习到的参数仍然可以还原图片。
注: 噪声可以是添加到输入的纯高斯噪声,也可以是随机丢弃输入层的某个特性。
1-3.惩罚导数作为正则
另一正则化自编码器的策略是使用一个类似稀疏自编码器中的惩罚项
,
但
的形式不同:
这迫使模型学习一个在 变化小时目标也没有太大变化的函数。 因为这个惩罚只对训练数据适用,它迫使自编码器学习可以反映训练数据分布信息的特征。
这样正则化的自编码器被称为收缩自编码器。 这种方法与去噪自编码器、流形学习和概率模型存在一定理论联系。
