PyTorch深度学习实战(25)——自编码器
0. 前言
自编码器 (Autoencoder) 是一种无监督学习的神经网络模型,用于数据的特征提取和降维,它由一个编码器 (Encoder) 和一个解码器 (Decoder) 组成,通过将输入数据压缩到低维表示,然后再重构出原始数据。在本节中,我们将学习如何使用自编码器,以在低维空间表示图像,学习以较少的维度表示图像有助于修改图像,可以利用低维表示来生成新图像。
1. 自编码器
我们已经学习了通过输入图像及其相应标签训练模型来对图像进行分类,进行分类的前提是是拥有带有类别标签的数据集。假设数据集中没有图像对应的标签,如果需要根据图像的相似性对图像进行聚类,在这种情况下,自编码器可以方便地识别和分组相似的图像。
自动编码器将图像作为输入,将其存储在低维空间中,并尝试通过解码过程输出相同图像,而不使用其他标签,因此 AutoEncoder 中的 Auto 表示能够再现输入。但是,如果我们只需要简单的在输出中重现输入,就不需要神经网络了,只需要将输入简单地原样输出即可。自编码器的作用在于它能够以较低维度对图像信息进行编码,因此称为编码器(将图像信息编码至较低维空间中),因此,相似的图像具有相似的编码。此外,解码器致力于根据编码矢量重建原始图像,以尽可能重现输入图像:

假设模型输入图像是 MNIST 手写数字图像,模型输出图像与输入图像相同。最中间的网络层是编码层,也称瓶颈层 (bottleneck layer),输入和瓶颈层之间发生的操作表示编码器,瓶颈层和输出之间的操作表示解码器。
通过瓶颈层,我们可以在低维空间中表示图像,也可以重建原始图像,换句话说,利用自编码器中的瓶颈层能够解决识别相似图像以及生成新图像的问题,具体而言:
- 具有相似瓶颈层值(编码表示,也称潜编码)的图像可能彼此相似
- 通过改变瓶颈层的节点值,可以改变输出图像。
2. 使用 PyTorch 实现自编码器
本节中,使用 PyTorch 构建自编码器,我们使用 MNIST 数据集训练此网络,MNIST 数据集中是一个手写数字的图像数据集,包含了 6 万个 28x28 像素的训练样本和 1 万个测试样本。
(1) 导入相关库并定义设备:
from torchvision.datasets import MNIST
from torchvision import transforms
from torch.utils.data import DataLoader, Dataset
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets, transforms
from torchvision.utils import make_grid
import numpy as np
from matplotlib import pyplot as plt
device = 'cuda' if torch.cuda.is_available() else 'cpu'
(2) 指定图像转换方法:
img_transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize([0.5], [0.5]),
transforms.Lambda(lambda x: x.to(device))
])
通过以上代码,将图像转换为张量,对其进行归一化,然后将其传递到设备中。
(3) 创建训练和验证数据集:
trn_ds = MNIST('MNIST/', transform=img_transform, train=True, download=True)
val_ds = MNIST('MNIST/', transform=img_transform, train=False, download=True)
(4) 定义数据加载器:
batch_size = 256
trn_dl = DataLoader(trn_ds, batch_size=batch_size, shuffle=True)
val_dl = DataLoader(val_ds, batch_size=batch_size, shuffle=False)
(5) 定义网络架构,在 __init__ 方法中定义了使用编码器-解码器架构的 AutoEncoder 类,以及瓶颈层的维度,latent_dim 和 forward 方法,并打印模型摘要信息。
定义 AutoEncoder 类和包含编码器、解码器以及瓶颈层维度的 __init__ 方法:
class AutoEncoder(nn.Module):
def __init__(self, latent_dim):
super().__init__()
self.latend_dim = latent_dim
self.encoder = nn.Sequential(
nn.Linear(28 * 28, 128), nn.ReLU(True),
nn.Linear(128, 64), nn.ReLU(True),
#nn.Linear(64, 12), nn.ReLU(True),
nn.Linear(64, latent_dim))
self.decoder = nn.Sequential(
#nn.Linear(latent_dim, 12), nn.ReLU(True),
nn.Linear(latent_dim, 64), nn.ReLU(True),
nn.Linear(64, 128), nn.ReLU(True),
nn.Linear(128, 28 * 28), nn.Tanh())
定义前向计算方法 forward:
def forward(self, x):
x = x.view(len(x), -1)
x = self.encoder(x)
x = self.decoder(x)
x = x.view(len(x), 1, 28, 28)
return x
打印模型摘要信息:
from torchsummary import summary
model = AutoEncoder(3).to(device)
print(summary(model, (1,28,28)))
模型架构信息输出如下:
----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Linear-1 [-1, 128] 100,480
ReLU-2 [-1, 128] 0
Linear-3 [-1, 64] 8,256
ReLU-4 [-1, 64] 0
Linear-5 [-1, 3] 195
Linear-6 [-1, 64] 256
ReLU-7 [-1, 64] 0
Linear-8 [-1, 128] 8,320
ReLU-9 [-1, 128] 0
Linear-10 [-1, 784] 101,136
Tanh-11 [-1, 784] 0
================================================================
Total params: 218,643
Trainable params: 218,643
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.00
Forward/backward pass size (MB): 0.02
Params size (MB): 0.83
Estimated Total Size (MB): 0.85
----------------------------------------------------------------
从前面的输出中,可以看到 Linear: 2-5 层是瓶颈层,将每张图像都表示为一个 3 维向量;此外,解码器使用瓶颈层中的 3 维向量重建原始图像。
(6) 定义函数在批数据上训练模型 train_batch():
def train_batch(input, model, criterion, optimizer):
model.train()
optimizer.zero_grad()
output = model(input)
loss = criterion(output, input)
loss.backward()
optimizer.step()
return loss
(7) 定义在批数据上进行模型验证的函数 validate_batch():
@torch.no_grad()
def validate_batch(input, model, criterion):
model.eval()
output = model(input)
loss = criterion(output, input)
return loss
(8) 定义模型、损失函数和优化器:
model = AutoEncoder(3).to(device)
criterion = nn.MSELoss()
optimizer = torch.optim.AdamW(model.parameters(), lr=0.001, weight_decay=1e-5)
(9) 训练模型:
num_epochs = 20
train_loss_epochs = []
val_loss_epochs = []
for epoch in range(num_epochs):
N = len(trn_dl)
trn_loss = []
val_loss = []
for ix, (data, _) in enumerate(trn_dl):
loss = train_batch(data, model, criterion, optimizer)
pos = (epoch + (ix+1)/N)
trn_loss.append(loss.item())
train_loss_epochs.append(np.average(trn_loss))
N = len(val_dl)
for ix, (data, _) in enumerate(val_dl):
loss = validate_batch(data, model, criterion)
pos = epoch + (1+ix)/N
val_loss.append(loss.item())
val_loss_epochs.append(np.average(val_loss))
(10) 可视化训练期间模型的训练和验证损失随时间的变化情况:
epochs = np.arange(num_epochs)+1
plt.plot(epochs, train_loss_epochs, 'bo', label='Training loss')
plt.plot(epochs, val_loss_epochs, 'r-', label='Test loss')
plt.title('Training and Test loss over increasing epochs')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.grid('off')
plt.show()

(11) 使用测试数据集 val_ds 验证模型:
for _ in range(5):
ix = np.random.randint(len(val_ds))
im, _ = val_ds[ix]
_im = model(im[None])[0]
plt.subplot(121)
# fig, ax = plt.subplots(1,2,figsize=(3,3))
plt.imshow(im[0].detach().cpu(), cmap='gray')
plt.title('input')
plt.subplot(122)
plt.imshow(_im[0].detach().cpu(), cmap='gray')
plt.title('prediction')
plt.show()

我们可以看到,即使瓶颈层只有三个维度,网络也可以非常准确地重现输入,但是图像并不像预期的那样清晰,主要是因为瓶颈层中的节点数量过少。具有不同瓶颈层大小 (2、3、5、10 和 50) 的网络训练后,可视化重建的图像如下所示:
def train_aec(latent_dim):
model = AutoEncoder(latent_dim).to(device)
criterion = nn.MSELoss()
optimizer = torch.optim.AdamW(model.parameters(), lr=0.001, weight_decay=1e-5)
num_epochs = 20
train_loss_epochs = []
val_loss_epochs = []
for epoch in range(num_epochs):
N = len(trn_dl)
trn_loss = []
val_loss = []
for ix, (data, _) in enumerate(trn_dl):
loss = train_batch(data, model, criterion, optimizer)
pos = (epoch + (ix+1)/N)
trn_loss.append(loss.item())
train_loss_epochs.append(np.average(trn_loss))
N = len(val_dl)
trn_loss = []
val_loss = []
for ix, (data, _) in enumerate(val_dl):
loss = validate_batch(data, model, criterion)
pos = epoch + (1+ix)/N
val_loss.append(loss.item())
val_loss_epochs.append(np.average(val_loss))
epochs = np.arange(num_epochs)+1
plt.plot(epochs, train_loss_epochs, 'bo', label='Training loss')
plt.plot(epochs, val_loss_epochs, 'r-', label='Test loss')
plt.title('Training and Test loss over increasing epochs')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.grid('off')
plt.show()
return model
aecs = [train_aec(dim) for dim in [50, 2, 3, 5, 10]]
for _ in range(10):
ix = np.random.randint(len(val_ds))
im, _ = val_ds[ix]
plt.subplot(1, len(aecs)+1, 1)
plt.imshow(im[0].detach().cpu(), cmap='gray')
plt.title('input')
idx = 2
for model in aecs:
_im = model(im[None])[0]
plt.subplot(1, len(aecs)+1, idx)
plt.imshow(_im[0].detach().cpu(), cmap='gray')
plt.title(f'prediction\nlatent-dim:{
model.latend_dim}')
idx += 1
plt.show()
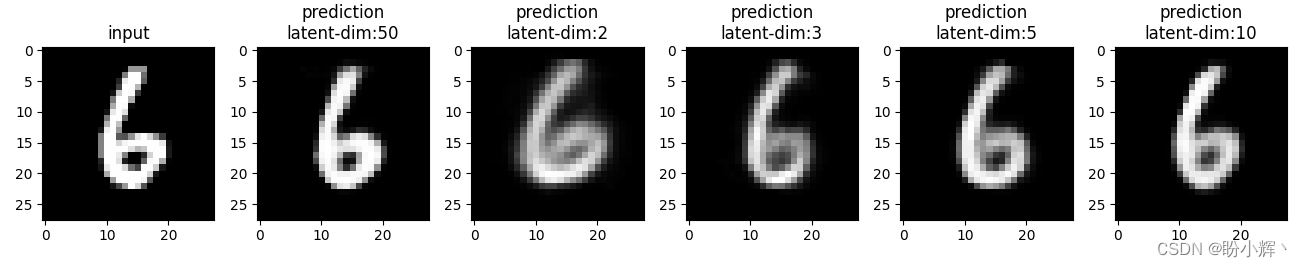
随着瓶颈层中向量维度的增加,重建图像的清晰度逐渐提高。
小结
自编码器是一种无监督学习的神经网络模型,用于数据的特征提取和降维。它由编码器和解码器组成,通过将输入数据压缩到低维表示,并尝试重构出原始数据来实现特征提取和数据的降维。自编码器的训练过程中,目标是最小化输入数据与重构数据之间的重建误差,以使编码器捕捉到数据的关键特征。自编码器在无监督学习和深度学习中扮演着重要的角色,能够从数据中学习有用的特征,并为后续的机器学习任务提供支持。
系列链接
PyTorch深度学习实战(1)——神经网络与模型训练过程详解
PyTorch深度学习实战(2)——PyTorch基础
PyTorch深度学习实战(3)——使用PyTorch构建神经网络
PyTorch深度学习实战(4)——常用激活函数和损失函数详解
PyTorch深度学习实战(5)——计算机视觉基础
PyTorch深度学习实战(6)——神经网络性能优化技术
PyTorch深度学习实战(7)——批大小对神经网络训练的影响
PyTorch深度学习实战(8)——批归一化
PyTorch深度学习实战(9)——学习率优化
PyTorch深度学习实战(10)——过拟合及其解决方法
PyTorch深度学习实战(11)——卷积神经网络
PyTorch深度学习实战(12)——数据增强
PyTorch深度学习实战(13)——可视化神经网络中间层输出
PyTorch深度学习实战(14)——类激活图
PyTorch深度学习实战(15)——迁移学习
PyTorch深度学习实战(16)——面部关键点检测
PyTorch深度学习实战(17)——多任务学习
PyTorch深度学习实战(18)——目标检测基础
PyTorch深度学习实战(19)——从零开始实现R-CNN目标检测
PyTorch深度学习实战(20)——从零开始实现Fast R-CNN目标检测
PyTorch深度学习实战(21)——从零开始实现Faster R-CNN目标检测
PyTorch深度学习实战(22)——从零开始实现YOLO目标检测
PyTorch深度学习实战(23)——使用U-Net架构进行图像分割
PyTorch深度学习实战(24)——从零开始实现Mask R-CNN实例分割