查找就是根据给定的某个值,在查找表中确定一个其关键字等于给定值的数据元素。
顺序表查找
顺序表查找(sequential search)又叫线性查找,是最基本的查找技术,它的查找过程是:从表中第一个记录开始,逐个进行记录的关键字和给定值比较,若某个记录的关键字和给定值相等,则查找成功,找到所查的记录;如果查到最后一个记录,其关键字和给定值比较都不等时,则表中没有所查的记录,查找不成功。
- 顺序表查找
a为数组,key为要查找的关键字,a[i]==key则查找成功。 - 顺序表查找优化
以上算法每次循环时都要对i是否越界,即是否小于等于n作判断。事实上,还可以有更好一点的办法,设置一个哨兵,可以解决不需要每次让i与n作比较,时间复杂度为O(n)。
有序表查找
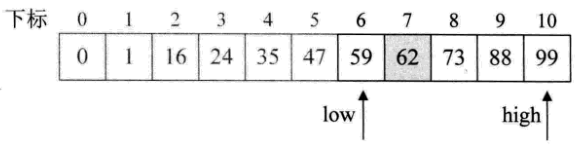
折半查找
折半查找又称为二分查找,它的前提是线性表中的记录必须是关键码有序,线性表必须采用顺序存储,时间复杂度O(logn)。
插值查找
现在我们的问题是,为什么一定要折半,而不是折1/4或者折更多呢?插值查找时根据要查找的关键字key与查找表中最大最小记录的关键字比较后的查找方法,其核心就在于插值的计算公式:
mid = low + (high-low)*(key-a[low])/(a[high]-a[low]);
时间复杂度为O(logn),但对于表长较长,而关键字分布又比较均匀的查找表来说,插值查找算法的平均性能比折半查找好得多。
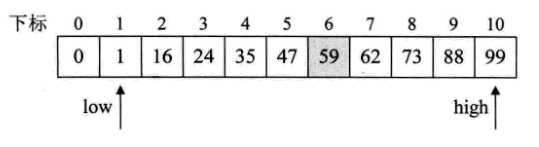
斐波那契查找
除了插值查找,还可以利用黄金分割原理来实现查找,即斐波那契查找。
- 数组不够斐波那契对应数字长度,得补全a[i]=a[n]
- mid=low+F[k-1]-1
- 如果key<a[mid],则high=mid-1;k=k-1
- 如果key>a[mid],则low=mid+1;k=k-2
- 直到key=a[mid],程序结束
如果mid>n,则说明是补全数值,返回n
#include "stdio.h"
#include "stdlib.h"
#include "io.h"
#include "math.h"
#include "time.h"
#define OK 1
#define ERROR 0
#define TRUE 1
#define FALSE 0
#define MAXSIZE 100 /* 存储空间初始分配量 */
typedef int Status; /* Status是函数的类型,其值是函数结果状态代码,如OK等 */
int F[100]; /* 斐波那契数列 */
/* 无哨兵顺序查找,a为数组,n为要查找的数组个数,key为要查找的关键字 ,i返回角标*/
int Sequential_Search(int *a, int n, int key)
{
int i;
for (i = 1; i <= n; i++)
{
if (a[i] == key)
return i;
}
return 0;
}
/* 有哨兵顺序查找 */
//a为表,n为表长,key为要查找的数字,i返回数字角标
int Sequential_Search2(int *a, int n, int key)
{
int i;
a[0] = key;
i = n;
while (a[i] != key)
{
i--;
}
return i;
}
/* 折半查找 */
//a为表,n为表长,key为要查找的数字,mid返回数字角标
int Binary_Search(int *a, int n, int key)
{
int low, high, mid;
low = 1; /* 定义最低下标为记录首位 */
high = n; /* 定义最高下标为记录末位 */
while (low <= high)
{
mid = (low + high) / 2; /* 折半 */
if (key<a[mid]) /* 若查找值比中值小 */
high = mid - 1; /* 最高下标调整到中位下标小一位 */
else if (key>a[mid])/* 若查找值比中值大 */
low = mid + 1; /* 最低下标调整到中位下标大一位 */
else
{
return mid; /* 若相等则说明mid即为查找到的位置 */
}
}
return 0;
}
/* 插值查找 */
//a为表,n为表长,key为要查找的数字,mid返回数字角标
int Interpolation_Search(int *a, int n, int key)
{
int low, high, mid;
low = 1; /* 定义最低下标为记录首位 */
high = n; /* 定义最高下标为记录末位 */
while (low <= high)
{
mid = low + (high - low)*(key - a[low]) / (a[high] - a[low]); /* 插值 */
if (key<a[mid]) /* 若查找值比插值小 */
high = mid - 1; /* 最高下标调整到插值下标小一位 */
else if (key>a[mid])/* 若查找值比插值大 */
low = mid + 1; /* 最低下标调整到插值下标大一位 */
else
return mid; /* 若相等则说明mid即为查找到的位置 */
}
return 0;
}
/* 斐波那契查找 */
//a为表,n为表长,key为要查找的数字,mid返回数字的角标
int Fibonacci_Search(int *a, int n, int key)
{
int low, high, mid, i, k = 0;
low = 1; /* 定义最低下标为记录首位 */
high = n; /* 定义最高下标为记录末位 */
while (n>F[k] - 1)
k++;
for (i = n; i<F[k] - 1; i++)
a[i] = a[n];
while (low <= high)
{
mid = low + F[k - 1] - 1;
if (key<a[mid])
{
high = mid - 1;
k = k - 1;
}
else if (key>a[mid])
{
low = mid + 1;
k = k - 2;
}
else
{
if (mid <= n)
return mid; /* 若相等则说明mid即为查找到的位置 */
else
return n;
}
}
return 0;
}
int main(void)
{
int a[MAXSIZE + 1], i, result;
int arr[MAXSIZE] = { 0,1,16,24,35,47,59,62,73,88,99 };
for (i = 0; i <= MAXSIZE; i++)
{
a[i] = i;
}
result = Sequential_Search(a, MAXSIZE, MAXSIZE);
printf("Sequential_Search:%d \n", result);
result = Sequential_Search2(a, MAXSIZE, 1);
printf("Sequential_Search2:%d \n", result);
result = Binary_Search(arr, 10, 62);
printf("Binary_Search:%d \n", result);
result = Interpolation_Search(arr, 10, 62);
printf("Interpolation_Search:%d \n", result);
F[0] = 0;//斐波那契数列,全局变量
F[1] = 1;
for (i = 2; i < 100; i++)
{
F[i] = F[i - 1] + F[i - 2];
}
result = Fibonacci_Search(arr, 10, 62);
printf("Fibonacci_Search:%d \n", result);
system("pause");
return 0;
}
运行结果:
Sequential_Search:100
Sequential_Search2:1
Binary_Search:7
Interpolation_Search:7
Fibonacci_Search:7
请按任意键继续. . .
线性索引查找
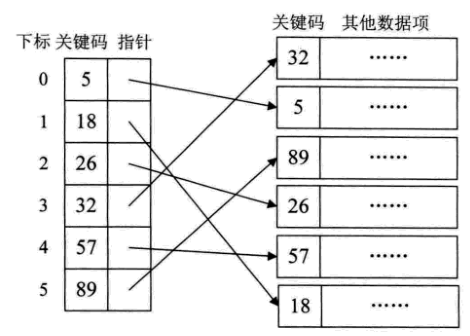
稠密索引
稠密索引是指在线性索引中,将数据集中的每个记录对应一个索引项,索引项一定是按照关键码有序排列。
- 关键字有序,可以使用折半、插值、斐波那契等有序查找法
- 但对于
内存有限的计算机来说,可能需要反复的访问磁盘,查找性能下降。
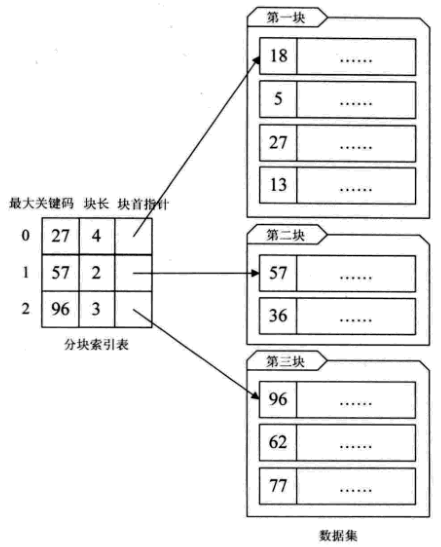
分块索引
分块索引好比图书馆的书架,块间有序,块内无序,需要指定块的的最大关键码,使得下一个块的最小关键字比上一个最大关键字大。
- 块间使用折半、插值等算法
- 块内使用顺序查找算法
- 效率比顺序查找O(n)高,比折半O(logn)低。
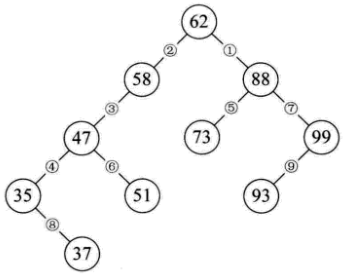
二叉排序树
1. 顺序存储插、删快,查找慢
2. 对于有序表,折半、插值、斐波那契查找快,增删慢
二叉排序树是以链接的方式存储,保持了链接存储结构在执行插入或删除操作时不用移动元素的优点,插入删除的时间性能好。二叉树的查找性能取决于二叉树的形状,不平衡的极端情况下可能需要查找n次。
#include "stdio.h"
#include "stdlib.h"
#include "io.h"
#include "math.h"
#include "time.h"
#define OK 1
#define ERROR 0
#define TRUE 1
#define FALSE 0
#define MAXSIZE 100 /* 存储空间初始分配量 */
typedef int Status; /* Status是函数的类型,其值是函数结果状态代码,如OK等 */
/* 二叉树的二叉链表结点结构定义 */
typedef struct BiTNode /* 结点结构 */
{
int data; /* 结点数据 */
struct BiTNode *lchild, *rchild; /* 左右孩子指针 */
} BiTNode, *BiTree;
/* 递归查找二叉排序树T中是否存在key, */
/* 指针f指向T的双亲,其初始调用值为NULL */
/* 若查找成功,则指针p指向该数据元素结点,并返回TRUE */
/* 否则指针p指向查找路径上访问的最后一个结点并返回FALSE */
Status SearchBST(BiTree T, int key, BiTree f, BiTree *p)
{
if (!T) /* 查找不成功 */
{
*p = f;
return FALSE;
}
else if (key == T->data) /* 查找成功 */
{
*p = T;
return TRUE;
}
else if (key<T->data)
return SearchBST(T->lchild, key, T, p); /* 在左子树中继续查找 */
else
return SearchBST(T->rchild, key, T, p); /* 在右子树中继续查找 */
}
/* 当二叉排序树T中不存在关键字等于key的数据元素时, */
/* 插入key并返回TRUE,否则返回FALSE */
Status InsertBST(BiTree *T, int key)
{
BiTree p, s;
if (!SearchBST(*T, key, NULL, &p)) /* 查找不成功 */
{
s = (BiTree)malloc(sizeof(BiTNode));
s->data = key;
s->lchild = s->rchild = NULL;
if (!p)
*T = s; /* 插入s为新的根结点 */
else if (key<p->data)
p->lchild = s; /* 插入s为左孩子 */
else
p->rchild = s; /* 插入s为右孩子 */
return TRUE;
}
else
return FALSE; /* 树中已有关键字相同的结点,不再插入 */
}
/* 从二叉排序树中删除结点p,并重接它的左或右子树。 */
Status Delete(BiTree *p)
{
BiTree q, s;
if ((*p)->rchild == NULL) /* 右子树空则只需重接它的左子树(待删结点是叶子也走此分支) */
{
q = *p; *p = (*p)->lchild; free(q);
}
else if ((*p)->lchild == NULL) /* 只需重接它的右子树 */
{
q = *p; *p = (*p)->rchild; free(q);
}
else /* 左右子树均不空 */
{
q = *p; s = (*p)->lchild;
while (s->rchild) /* 转左,然后向右到尽头(找待删结点的前驱) */
{
q = s;
s = s->rchild;
}
(*p)->data = s->data; /* s指向被删结点的直接前驱(将被删结点前驱的值取代被删结点的值) */
if (q != *p)
q->rchild = s->lchild; /* 重接q的右子树 */
else
q->lchild = s->lchild; /* 重接q的左子树 */
free(s);
}
return TRUE;
}
/* 若二叉排序树T中存在关键字等于key的数据元素时,则删除该数据元素结点, */
/* 并返回TRUE;否则返回FALSE。 */
Status DeleteBST(BiTree *T, int key)
{
if (!*T) /* 不存在关键字等于key的数据元素 */
return FALSE;
else
{
if (key == (*T)->data) /* 找到关键字等于key的数据元素 */
return Delete(T);
else if (key<(*T)->data)
return DeleteBST(&(*T)->lchild, key);
else
return DeleteBST(&(*T)->rchild, key);
}
}
int main(void)
{
int i;
int a[10] = { 62,88,58,47,35,73,51,99,37,93 };
BiTree T = NULL;
for (i = 0; i<10; i++)
{
InsertBST(&T, a[i]);
}
BiTree p = NULL;
int result1 = SearchBST(T, 93, NULL, &p);
printf("查找'93'的结果为(1:存在,0:不存在):%d\n",result1);
int result2 = DeleteBST(&T, 93);
printf("删除'93'的结果为(1:成功,0:不成功):%d\n", result2);
int result3 = SearchBST(T, 93, NULL, &p);
printf("查找'93'的结果为(1:存在,0:不存在):%d\n", result3);
//printf("本样例建议断点跟踪查看二叉排序树结构\n");
system("pause");
return 0;
}
运行结果为:
查找'93'的结果为(1:存在,0:不存在):1
删除'93'的结果为(1:成功,0:不成功):1
查找'93'的结果为(1:存在,0:不存在):0
请按任意键继续. . .
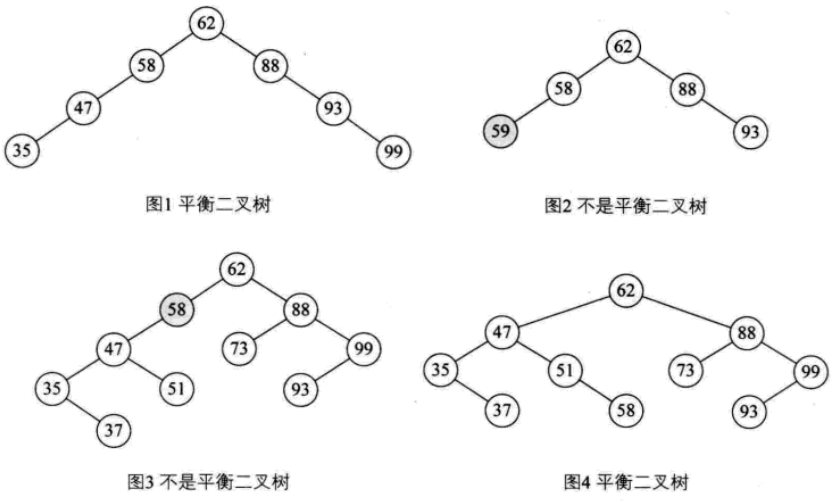
平衡二叉树(AVL树)
平衡二叉树是一种二叉排序树,其中每一个节点的左子树和右子树的高度差至多等于1。
- 图2中58<59不满足二叉排序树定义
- 图3中58左子树高度2,右子树为空,相差大于1,故不满足
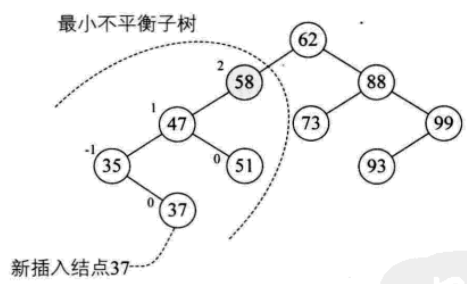
距离插入结点最近的,且平衡因子的绝对值大于1的结点为根的子树,我们称为最小不平衡子树。当插入结点37时,距离它最近的平衡因子绝对值超过1的结点是58(左子树高度2减去右子树高度0),所以从58开始以下的子树为最小不平衡子树。
平衡二叉树实现原理:每当插入一个结点时,先检查是否因为插入结点而破坏了树的平衡性,若是,则找出最小不平衡子树。在保持二叉树特性的前提下,调整最小不平衡子树中结点的链接关系,进行相应的旋转,使之成为新的平衡二叉树。
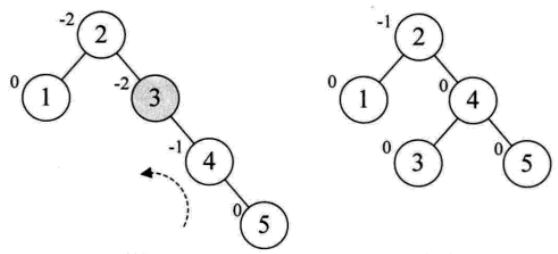
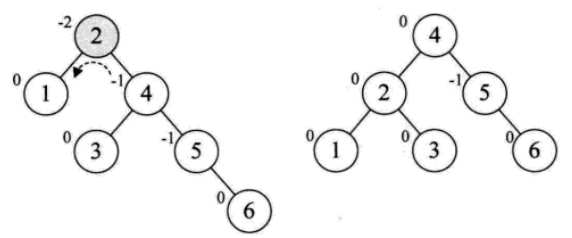
(1)插入结点5,结点3的BF值为-2说明要旋转了,对这棵树的最小平衡子树进行左旋,以此达到平衡。
(2)插入结点6,结点2的BF值为-2,把树的最小平衡子树左旋,旋转后为满足二叉排序树的特性,结点3需要作出改变。
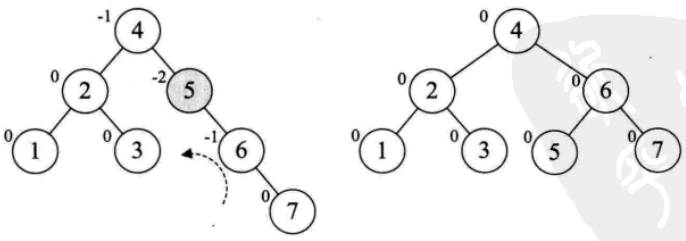
(3)添加结点7,结点5的BF值为-2,左旋。
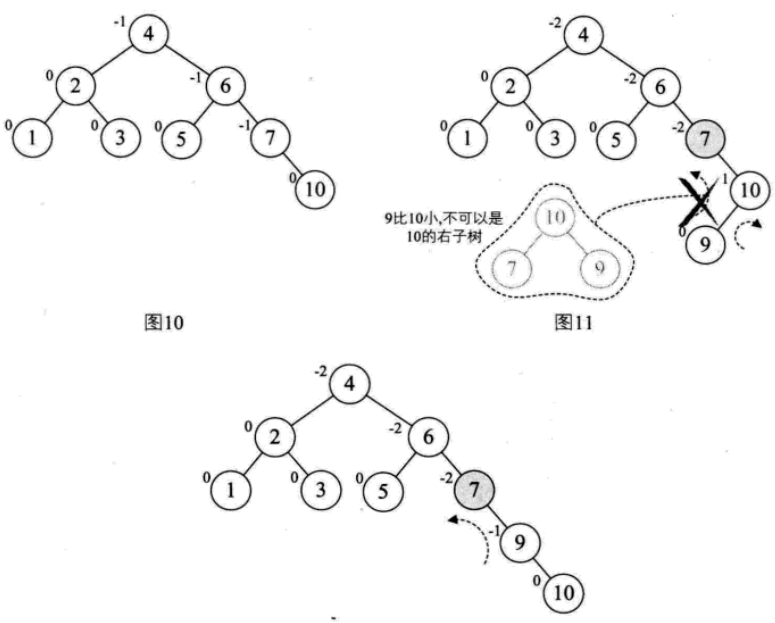
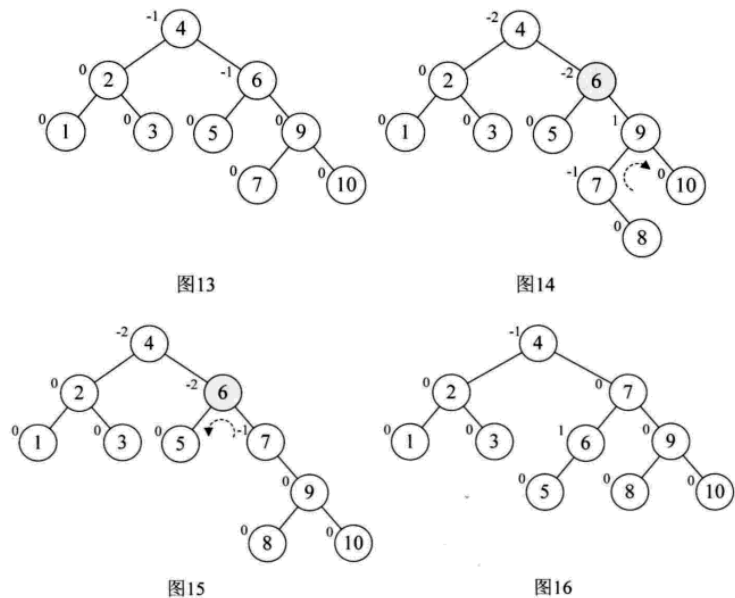
(4)添加结点10,结构不变化。添加结点9,结点7的BF值为-2,而结点10的BF为1,一正一负,符号不统一。所以先把结点9、10右旋,符号统一,再左旋。添加结点8同理可得。
#include "stdio.h"
#include "stdlib.h"
#include "io.h"
#include "math.h"
#include "time.h"
#define OK 1
#define ERROR 0
#define TRUE 1
#define FALSE 0
#define MAXSIZE 100 /* 存储空间初始分配量 */
typedef int Status; /* Status是函数的类型,其值是函数结果状态代码,如OK等 */
/* 二叉树的二叉链表结点结构定义 */
typedef struct BiTNode /* 结点结构 */
{
int data; /* 结点数据 */
int bf; /* 结点的平衡因子 */
struct BiTNode *lchild, *rchild; /* 左右孩子指针 */
} BiTNode, *BiTree;
/* 对以p为根的二叉排序树作右旋处理, */
/* 处理之后p指向新的树根结点,即旋转处理之前的左子树的根结点 */
void R_Rotate(BiTree *P)
{
BiTree L;
L = (*P)->lchild; /* L指向P的左子树根结点 */
(*P)->lchild = L->rchild; /* L的右子树挂接为P的左子树 */
L->rchild = (*P);
*P = L; /* P指向新的根结点 */
}
/* 对以P为根的二叉排序树作左旋处理, */
/* 处理之后P指向新的树根结点,即旋转处理之前的右子树的根结点0 */
void L_Rotate(BiTree *P)
{
BiTree R;
R = (*P)->rchild; /* R指向P的右子树根结点 */
(*P)->rchild = R->lchild; /* R的左子树挂接为P的右子树 */
R->lchild = (*P);
*P = R; /* P指向新的根结点 */
}
#define LH +1 /* 左高 */
#define EH 0 /* 等高 */
#define RH -1 /* 右高 */
/* 对以指针T所指结点为根的二叉树作左平衡旋转处理 */
/* 本算法结束时,指针T指向新的根结点 */
void LeftBalance(BiTree *T)
{
BiTree L, Lr;
L = (*T)->lchild; /* L指向T的左子树根结点 */
switch (L->bf)
{ /* 检查T的左子树的平衡度,并作相应平衡处理 */
case LH: /* 新结点插入在T的左孩子的左子树上,要作单右旋处理 */
(*T)->bf = L->bf = EH;
R_Rotate(T);
break;
case RH: /* 新结点插入在T的左孩子的右子树上,要作双旋处理 */
Lr = L->rchild; /* Lr指向T的左孩子的右子树根 */
switch (Lr->bf)
{ /* 修改T及其左孩子的平衡因子 */
case LH: (*T)->bf = RH;
L->bf = EH;
break;
case EH: (*T)->bf = L->bf = EH;
break;
case RH: (*T)->bf = EH;
L->bf = LH;
break;
}
Lr->bf = EH;
L_Rotate(&(*T)->lchild); /* 对T的左子树作左旋平衡处理 */
R_Rotate(T); /* 对T作右旋平衡处理 */
}
}
/* 对以指针T所指结点为根的二叉树作右平衡旋转处理, */
/* 本算法结束时,指针T指向新的根结点 */
void RightBalance(BiTree *T)
{
BiTree R, Rl;
R = (*T)->rchild; /* R指向T的右子树根结点 */
switch (R->bf)
{ /* 检查T的右子树的平衡度,并作相应平衡处理 */
case RH: /* 新结点插入在T的右孩子的右子树上,要作单左旋处理 */
(*T)->bf = R->bf = EH;
L_Rotate(T);
break;
case LH: /* 新结点插入在T的右孩子的左子树上,要作双旋处理 */
Rl = R->lchild; /* Rl指向T的右孩子的左子树根 */
switch (Rl->bf)
{ /* 修改T及其右孩子的平衡因子 */
case RH: (*T)->bf = LH;
R->bf = EH;
break;
case EH: (*T)->bf = R->bf = EH;
break;
case LH: (*T)->bf = EH;
R->bf = RH;
break;
}
Rl->bf = EH;
R_Rotate(&(*T)->rchild); /* 对T的右子树作右旋平衡处理 */
L_Rotate(T); /* 对T作左旋平衡处理 */
}
}
/* 若在平衡的二叉排序树T中不存在和e有相同关键字的结点,则插入一个 */
/* 数据元素为e的新结点,并返回1,否则返回0。若因插入而使二叉排序树 */
/* 失去平衡,则作平衡旋转处理,布尔变量taller反映T长高与否。 */
Status InsertAVL(BiTree *T, int e, Status *taller)
{
if (!*T)
{ /* 插入新结点,树“长高”,置taller为TRUE */
*T = (BiTree)malloc(sizeof(BiTNode));
(*T)->data = e; (*T)->lchild = (*T)->rchild = NULL; (*T)->bf = EH;
*taller = TRUE;
}
else
{
if (e == (*T)->data)
{ /* 树中已存在和e有相同关键字的结点则不再插入 */
*taller = FALSE; return FALSE;
}
if (e<(*T)->data)
{ /* 应继续在T的左子树中进行搜索 */
if (!InsertAVL(&(*T)->lchild, e, taller)) /* 未插入 */
return FALSE;
if (*taller) /* 已插入到T的左子树中且左子树“长高” */
switch ((*T)->bf) /* 检查T的平衡度 */
{
case LH: /* 原本左子树比右子树高,需要作左平衡处理 */
LeftBalance(T); *taller = FALSE; break;
case EH: /* 原本左、右子树等高,现因左子树增高而使树增高 */
(*T)->bf = LH; *taller = TRUE; break;
case RH: /* 原本右子树比左子树高,现左、右子树等高 */
(*T)->bf = EH; *taller = FALSE; break;
}
}
else
{ /* 应继续在T的右子树中进行搜索 */
if (!InsertAVL(&(*T)->rchild, e, taller)) /* 未插入 */
return FALSE;
if (*taller) /* 已插入到T的右子树且右子树“长高” */
switch ((*T)->bf) /* 检查T的平衡度 */
{
case LH: /* 原本左子树比右子树高,现左、右子树等高 */
(*T)->bf = EH; *taller = FALSE; break;
case EH: /* 原本左、右子树等高,现因右子树增高而使树增高 */
(*T)->bf = RH; *taller = TRUE; break;
case RH: /* 原本右子树比左子树高,需要作右平衡处理 */
RightBalance(T); *taller = FALSE; break;
}
}
}
return TRUE;
}
int main(void)
{
int i;
int a[10] = { 3,2,1,4,5,6,7,10,9,8 };
BiTree T = NULL;
Status taller;
for (i = 0; i<10; i++)
{
InsertAVL(&T, a[i], &taller);
}
printf("本样例建议断点跟踪查看平衡二叉树结构");
return 0;
}
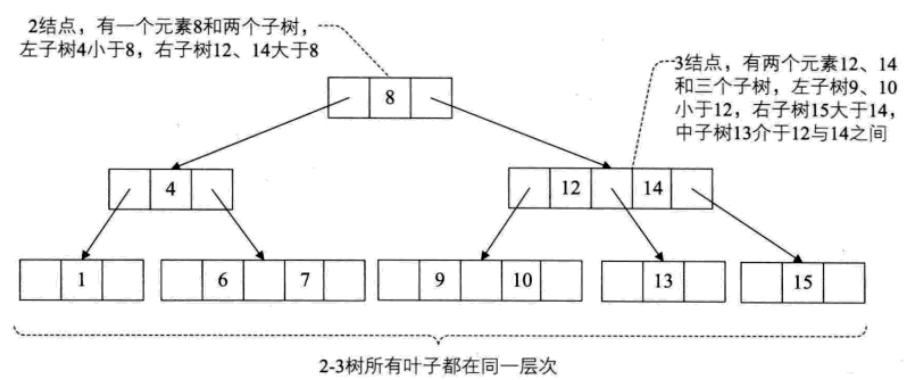
多路查找树(B树)
多路查找树,其每个结点的孩子书可以多于两个,且每个结点处可以存储多个元素。常见的形式有:2-3树,2-3-4树,B树和B+树。
B树是一种平衡的多路查找树,2-3树和2-3-4树都是B树的特例。结点最大的孩子数目称为B树的阶。因此,2-3树是3阶B树,2-3-4树是4阶B树。
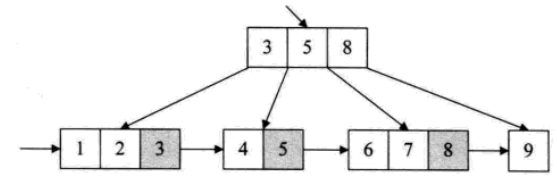
为了让遍历时每个元素只被访问一次,在原有的基础上出现了B+树,每个叶子节点都会保存一个指向后一叶子节点的指针。
#define _CRT_SECURE_NO_DEPRECATE
#include "stdio.h"
#include "stdlib.h"
#include "io.h"
#include "math.h"
#include "time.h"
#define OK 1
#define ERROR 0
#define TRUE 1
#define FALSE 0
#define MAXSIZE 100 /* 存储空间初始分配量 */
#define m 3 /* B树的阶,暂设为3 */
#define N 17 /* 数据元素个数 */
#define MAX 5 /* 字符串最大长度+1 */
typedef int Status; /* Status是函数的类型,其值是函数结果状态代码,如OK等 */
typedef struct BTNode
{
int keynum; /* 结点中关键字个数,即结点的大小 */
struct BTNode *parent; /* 指向双亲结点 */
struct Node /* 结点向量类型 */
{
int key; /* 关键字向量 */
struct BTNode *ptr; /* 子树指针向量 */
int recptr; /* 记录指针向量 */
}node[m + 1]; /* key,recptr的0号单元未用 */
}BTNode, *BTree; /* B树结点和B树的类型 */
typedef struct
{
BTNode *pt; /* 指向找到的结点 */
int i; /* 1..m,在结点中的关键字序号 */
int tag; /* 1:查找成功,O:查找失败 */
}Result; /* B树的查找结果类型 */
/* 在p->node[1..keynum].key中查找i,使得p->node[i].key≤K<p->node[i+1].key */
int Search(BTree p, int K)
{
int i = 0, j;
for (j = 1; j <= p->keynum; j++)
if (p->node[j].key <= K)
i = j;
return i;
}
/* 在m阶B树T上查找关键字K,返回结果(pt,i,tag)。若查找成功,则特征值 */
/* tag=1,指针pt所指结点中第i个关键字等于K;否则特征值tag=0,等于K的 */
/* 关键字应插入在指针Pt所指结点中第i和第i+1个关键字之间。 */
Result SearchBTree(BTree T, int K)
{
BTree p = T, q = NULL; /* 初始化,p指向待查结点,q指向p的双亲 */
Status found = FALSE;
int i = 0;
Result r;
while (p&&!found)
{
i = Search(p, K); /* p->node[i].key≤K<p->node[i+1].key */
if (i>0 && p->node[i].key == K) /* 找到待查关键字 */
found = TRUE;
else
{
q = p;
p = p->node[i].ptr;
}
}
r.i = i;
if (found) /* 查找成功 */
{
r.pt = p;
r.tag = 1;
}
else /* 查找不成功,返回K的插入位置信息 */
{
r.pt = q;
r.tag = 0;
}
return r;
}
/* 将r->key、r和ap分别插入到q->key[i+1]、q->recptr[i+1]和q->ptr[i+1]中 */
void Insert(BTree *q, int i, int key, BTree ap)
{
int j;
for (j = (*q)->keynum; j>i; j--) /* 空出(*q)->node[i+1] */
(*q)->node[j + 1] = (*q)->node[j];
(*q)->node[i + 1].key = key;
(*q)->node[i + 1].ptr = ap;
(*q)->node[i + 1].recptr = key;
(*q)->keynum++;
}
/* 将结点q分裂成两个结点,前一半保留,后一半移入新生结点ap */
void split(BTree *q, BTree *ap)
{
int i, s = (m + 1) / 2;
*ap = (BTree)malloc(sizeof(BTNode)); /* 生成新结点ap */
(*ap)->node[0].ptr = (*q)->node[s].ptr; /* 后一半移入ap */
for (i = s + 1; i <= m; i++)
{
(*ap)->node[i - s] = (*q)->node[i];
if ((*ap)->node[i - s].ptr)
(*ap)->node[i - s].ptr->parent = *ap;
}
(*ap)->keynum = m - s;
(*ap)->parent = (*q)->parent;
(*q)->keynum = s - 1; /* q的前一半保留,修改keynum */
}
/* 生成含信息(T,r,ap)的新的根结点&T,原T和ap为子树指针 */
void NewRoot(BTree *T, int key, BTree ap)
{
BTree p;
p = (BTree)malloc(sizeof(BTNode));
p->node[0].ptr = *T;
*T = p;
if ((*T)->node[0].ptr)
(*T)->node[0].ptr->parent = *T;
(*T)->parent = NULL;
(*T)->keynum = 1;
(*T)->node[1].key = key;
(*T)->node[1].recptr = key;
(*T)->node[1].ptr = ap;
if ((*T)->node[1].ptr)
(*T)->node[1].ptr->parent = *T;
}
/* 在m阶B树T上结点*q的key[i]与key[i+1]之间插入关键字K的指针r。若引起 */
/* 结点过大,则沿双亲链进行必要的结点分裂调整,使T仍是m阶B树。 */
void InsertBTree(BTree *T, int key, BTree q, int i)
{
BTree ap = NULL;
Status finished = FALSE;
int s;
int rx;
rx = key;
while (q&&!finished)
{
Insert(&q, i, rx, ap); /* 将r->key、r和ap分别插入到q->key[i+1]、q->recptr[i+1]和q->ptr[i+1]中 */
if (q->keynum<m)
finished = TRUE; /* 插入完成 */
else
{ /* 分裂结点*q */
s = (m + 1) / 2;
rx = q->node[s].recptr;
split(&q, &ap); /* 将q->key[s+1..m],q->ptr[s..m]和q->recptr[s+1..m]移入新结点*ap */
q = q->parent;
if (q)
i = Search(q, key); /* 在双亲结点*q中查找rx->key的插入位置 */
}
}
if (!finished) /* T是空树(参数q初值为NULL)或根结点已分裂为结点*q和*ap */
NewRoot(T, rx, ap); /* 生成含信息(T,rx,ap)的新的根结点*T,原T和ap为子树指针 */
}
void print(BTNode c, int i) /* TraverseDSTable()调用的函数 */
{
printf("(%d)", c.node[i].key);
}
int main()
{
int r[N] = { 22,16,41,58,8,11,12,16,17,22,23,31,41,52,58,59,61 };
BTree T = NULL;
Result s;
int i;
for (i = 0; i<N; i++)
{
s = SearchBTree(T, r[i]);
if (!s.tag)
InsertBTree(&T, r[i], s.pt, s.i);
}
printf("\n请输入待查找记录的关键字: ");
scanf("%d", &i);
s = SearchBTree(T, i);
if (s.tag)
print(*(s.pt), s.i);
else
printf("没找到");
printf("\n");
system("pause");
return 0;
}
哈希表
散列函数
- 直接定址法:f(key)=a*key+b
- 数字分析法:手机号后四位
- 平方取中法:1234平方得1522756,取227做散列地址,适合位数不是很大的情况。
- 折叠法:9876543210,分为四组987|654|321|0,求和987+654+321+0=1962,取后三位962,适合位数较多的情况。
- 除留取余法:f(key)=key mod p。
- 随机数法
散列冲突处理
开放定址法:
- 线性探测法:f(key)=(f(key)+di) mod m (di=1,2,3…m-1),di是冲突元素的角标,m为表长。
- 二次探测法:
- 伪随机法:di为伪随机数,
同样的随机种子结果相同。
再散列函数法:多次用相同或不同散列函数。
散列表查找实现
#include "stdio.h"
#include "stdlib.h"
#include "io.h"
#include "math.h"
#include "time.h"
#define OK 1
#define ERROR 0
#define TRUE 1
#define FALSE 0
#define MAXSIZE 100 /* 存储空间初始分配量 */
#define SUCCESS 1
#define UNSUCCESS 0
#define HASHSIZE 12 /* 定义散列表长为数组的长度 */
#define NULLKEY -32768
typedef int Status; /* Status是函数的类型,其值是函数结果状态代码,如OK等 */
typedef struct
{
int *elem; /* 数据元素存储基址,动态分配数组 */
int count; /* 当前数据元素个数 */
}HashTable;
int m = 0; /* 散列表表长,全局变量 */
/* 初始化散列表 */
Status InitHashTable(HashTable *H)
{
int i;
m = HASHSIZE;
H->count = m;
H->elem = (int *)malloc(m*sizeof(int));
for (i = 0; i<m; i++)
H->elem[i] = NULLKEY;
return OK;
}
/* 散列函数 */
int Hash(int key)
{
return key % m; /* 除留余数法 */
}
/* 插入关键字进散列表 */
void InsertHash(HashTable *H, int key)
{
int addr = Hash(key); /* 求散列地址 */
while (H->elem[addr] != NULLKEY) /* 如果不为空,则冲突 */
{
addr = (addr + 1) % m; /* 开放定址法的线性探测 */
}
H->elem[addr] = key; /* 直到有空位后插入关键字 */
}
/* 散列表查找关键字 */
Status SearchHash(HashTable H, int key, int *addr)
{
*addr = Hash(key); /* 求散列地址 */
while (H.elem[*addr] != key) /* 如果不为空,则冲突 */
{
*addr = (*addr + 1) % m; /* 开放定址法的线性探测 */
if (H.elem[*addr] == NULLKEY || *addr == Hash(key)) /* 如果循环回到原点 */
return UNSUCCESS; /* 则说明关键字不存在 */
}
return SUCCESS;
}
int main()
{
int arr[HASHSIZE] = { 12,67,56,16,25,37,22,29,15,47,48,34 };
int i, p, key, result;
HashTable H;
key = 39;
InitHashTable(&H);
for (i = 0; i<m; i++)
InsertHash(&H, arr[i]);
result = SearchHash(H, key, &p);
if (result)
printf("查找 %d 的地址为:%d \n", key, p);
else
printf("查找 %d 失败。\n", key);
for (i = 0; i<m; i++)
{
key = arr[i];
SearchHash(H, key, &p);
printf("查找 %d 的地址为:%d \n", key, p);
}
system("pause");
return 0;
}
运行结果:
查找 39 失败。
查找 12 的地址为:0
查找 67 的地址为:7
查找 56 的地址为:8
查找 16 的地址为:4
查找 25 的地址为:1
查找 37 的地址为:2
查找 22 的地址为:10
查找 29 的地址为:5
查找 15 的地址为:3
查找 47 的地址为:11
查找 48 的地址为:6
查找 34 的地址为:9
请按任意键继续. . .