大数据hadoop学习【5】-----通过JAVA编程,实现对HDFS文件的过滤与合并目录
在上次的hadoop学习之中,我们通过java编程实现了对HDFS文件系统中文件的各个基本操作,了解了在Hadoop文件系统HDFS与ubuntu下的文件系统的区别,也通过相应的命令和java编程让他们之间联系起来,这是学习大数据基础hadoop语言的必须要经历的一步!
本次博客,我们将通过JAVA编程,继续对HDFS文件系统进行相应的操作,即对HDFS文件实现过滤与合并,目的如下:
- 过滤出file文件下格式为=xxx.abc格式的学生信息文件
- 将file中的其他文件合并到input目录下的Merge.txt文件中
一、创建文件数据
1、切换到hadoop账户,并运行hadoop
1)、打开终端,切换为hadoop账户
su - hadoop
2)、进入hadoop环境
cd /usr/local/hadoop/
3)、运行hadoop
./sbin/start-dfs.sh
jps

注意:上面一定要有NameNode和DataNode节点哦!
2、在路径为[/user/hadoop]下创建file文件夹,用来保存我们的数据文件
1)、创建file文件夹:
./bin/hdfs dfs -mkdir /user/hadoop/file
2)、查看文件夹是否创建成功
./bin/hdfs dfs -ls /user/hadoop/

3、在file文件夹下创建3个写有学生基本信息的file文件
1)、创建file1.txt学生信息文件
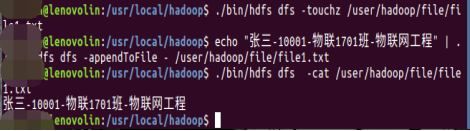
./bin/hdfs dfs -touchz /user/hadoop/file/file1.txt
2)、对该文件写入学习信息内容
echo "张三-10001-物联1701班-物联网工程" | ./bin/hdfs dfs -appendToFile - /user/hadoop/file/file1.txt
3)、通过cat命令查看文件内容是否成功写入
./bin/hdfs dfs -cat /user/hadoop/file/file1.txt
4)、其他两个文件和上面步骤一样哦,大家也可以自己多建立几个文件,方便看效果哦!
1.第二个学生基本信息的创建步骤如下所示:
./bin/hdfs dfs -touchz /user/hadoop/file/file2.txt
echo "李四-10002-物联1702班-物联网工程" | ./bin/hdfs dfs -appendToFile - /user/hadoop/file/file2.txt

2.第三个学生基本信息的创建步骤如下所示:
./bin/hdfs dfs -touchz /user/hadoop/file/file3.txt
echo "王五-10003-物联1703班-物联网工程" | ./bin/hdfs dfs -appendToFile - /user/hadoop/file/file3.txt

5)、创建过滤类型的文件file4.abc
创建file4.abc文件:
./bin/hdfs dfs -touchz /user/hadoop/file/file4.abc
写入文件内容:
a.echo "刘备-10004-物联1704班-物联网工程" | ./bin/hdfs dfs -appendToFile - /user/hadoop/file/file4.abc
查看文件是否成功写入:
./bin/hdfs dfs -cat /user/hadoop/file/file4.abc

4、创建文件Merge.txt,用于合并接收过滤后的文件
1)、在路径为[ /user/hadoop/input/]下创建Merge.txt文件
./bin/hdfs dfs -touchz /user/hadoop/input/Merge.txt
2)、查看文件是否创建成功
./bin/hdfs dfs -ls /user/hadoop/input/
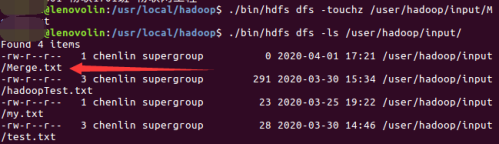
该文件中不用写入内容哦,接收合并文件后,自然会有数据的!
二、编写JAVA程序,实现对HDFS文件的过滤与合并
1、创建class,命名为FilterMergeFile
1)、在项目中右击->New->class
类名大家可以自己命名哦!
2、编写的JAVA程序代码如下:
import java.io.IOException;
import java.io.PrintStream;
import java.net.URI;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.fs.PathFilter;
public class FilterMergeFile {
Path inputPath = null; //待合并的文件所在的目录的路径
Path outputPath = null; //输出文件的路径
public FilterMergeFile(String input, String output){
this.inputPath = new Path(input);
this.outputPath = new Path(output);
}
public void doMerge() throws IOException{
Configuration conf = new Configuration();
conf.set("fs.defaultFS","hdfs://localhost:9000" );
conf.set("fs.hdfs.impl", "org.apache.hadoop.hdfs.DistributedFileSystem");
FileSystem fsSource = FileSystem.get(URI.create(inputPath.toString()),conf);
FileSystem fsDst = FileSystem.get(URI.create(outputPath.toString()),conf);
FileStatus[] sourceStatus = fsSource.listStatus(inputPath, new myPathFilter(".*\\.abc")); //过滤掉目录中后缀为.abc的文件
FSDataOutputStream fsdos = fsDst.create(outputPath);
//下面分别读取过滤之后的每个文件的内容,并输出到同一个文件中
for(int i=0;i<sourceStatus.length-1;i++){
System.out.println("路径: " + sourceStatus[i].getPath()+ " 文件大小: " + sourceStatus[i].getLen() + " 权限: " + sourceStatus[i].getPermission() + " 内容: ");
FSDataInputStream fsdis = fsSource.open(sourceStatus[i].getPath());
byte[] data = new byte[1024];
int read = -1;
PrintStream ps = new PrintStream(System.out);
while((read = fsdis.read(data)) > 0){
ps.write(data, 0, read);
fsdos.write(data, 0, read);
}
}
fsdos.close();
}
public static void main(String args[]) throws IOException{
FilterMergeFile merge = new FilterMergeFile("/user/hadoop/file", "/user/hadoop/input/Merge.txt");
merge.doMerge();
}
}
class myPathFilter implements PathFilter{ //过滤掉文件名满足特定条件的文件
String reg = null;
myPathFilter(String reg){
this.reg = reg;
}
public boolean accept(Path path) {
if(!(path.toString().matches(reg)))
return true;
return false;
}
}
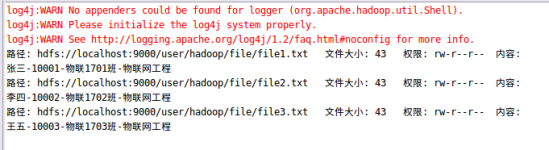
3、程序的运行结果如下所示:
1)、在eclipse的终端结果如下所示:
2)、在终端利用cat命令查看Merge.txt文件内容
./bin/hdfs dfs -cat /user/hadoop/input/Merge.txt

通过上面可以看出,该java程序将==/user/hadoop/file==路径下的格式为.abc的文件过滤掉,然后将剩下的txt格式的学生信息文件在路径[/user/hadoop/input/]下的Merge.txt文件中合并,将三个分开的文件内容,合并到一个文件内容之中,实现成功!
以上就是本次博客的全部内容啦,希望通过对本次博客的阅读,能够帮助你解决HDFS文件系统的文件的过滤和合并哦!遇到问题的小伙伴请在评论区进行留言,林君学长看到会大家解答的,这个学长不太冷!
陈一月的又一天编程岁月^ _ ^
