HDFS源自于Google在2003年10月发表的GFS论文,它是一个分布式文件系统,具有高容错,易扩展,存储量大,能够运行在廉价机上等特点,已经被很多企业广泛引用于基础等存储服务。
组件
HDFS中等核心组件主要有两个,一个是NameNode,一个是DataNode。
NmeNode负责管理集群等元数据信息,以及数据分布,DataNode负责存储具体等数据。HDFS存储数据的基本单位是数据块block,默认大小为128M,一个大文件会被拆分成多个数据块,存储在DataNode上。
另外还有一个辅助组件SecondayNameNode,它的主要作用是合并NameNode上的编辑日志和镜像文件,确保编辑日志不会过大,另外在Hadoop早起版本中,SecondayNamenode还作为NameNode的冷备。
架构
HDFS采用主从这种经典的分布式系统架构,如下图所示:
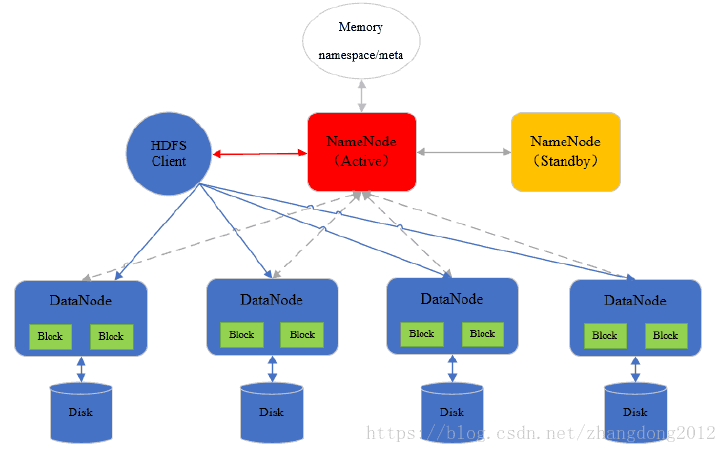
在Hadoop2.2以后,NameNode的高可用依赖于zookeeper来实现动态的这备切换,集群元数据信息通过QJM等高可用的共享存储系统在主备NameNode之间共享。
读流程
HDFS的数据读取流程如下图所示
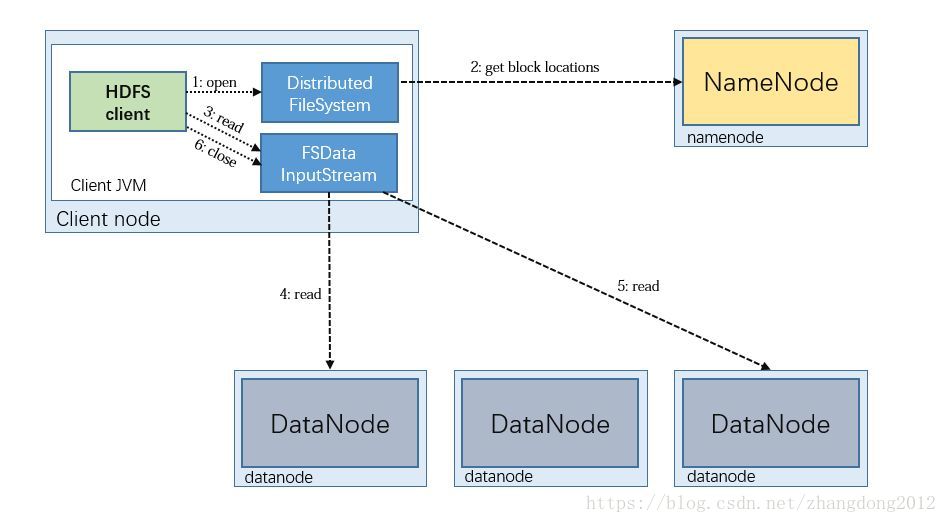
1)客户端请求NameNode读取数据,NameNode进行权限及文件是否存在等校验
2)NameNode定位到组成该文件的block列表,并按照就近原则返回给客户端存储了第一个block的datanode
3)客户端与dataNode通信,读取第一个bock块,然后在向namenode请求第二个block块的datanode,并进行读取,知道数据读取完成。
由于数据是以数据包的形式传送的,客户端在读取到一个数据包后,会验证当前数据包的校验和,检查数据是否损毁。
写流程
HDFS数据写入流程如下图所示:
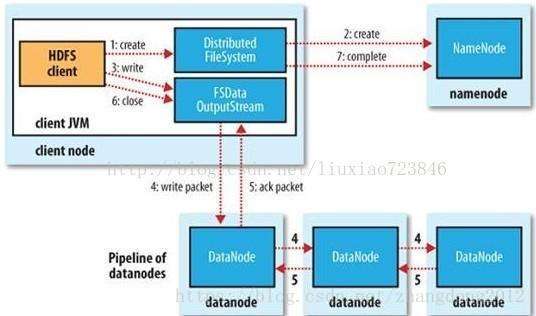
1)客户端与NameNode请求写入数据,NameNode校验用户权限以及文件是否存在等
2)验证通过后,NameNode为本次写入建立一条元数据,此时还不对外可见
3)客户端接收到允许上传后,会再次请求NameNode用于存储数据块的DataNode列表
4)客户端与NameNode返回的DataNode建立一个管道流,然后开始发送数据
5)数据以数据包的形式发送,当第一个datanode接收到数据包后,会把它传递给下一个datanode,并反向返回写入完成确认信息
6)一个block写入完成后,客户端会再次请求namenode返回一个datanode列表,再以上面的形式发送数据到datanode
7)当所有数据写入成功后,客户端通知namenode写入完成,namenode将本地写入的数据对外可见
元数据管理
元数据以三种形式存在
1. 在namenode内存中有一份完整的愿数据
2. 在磁盘上存储一份编辑日志(即以日志的形式写入记录写入请求)
3. 在磁盘上存储一份内存中的元数据快照镜像文件
镜像文件是内存中在某个检查点的数据快照,镜像文件中的数据通常会落后与内存中的数据,编辑日志是以日志的形式记录每次写入,为了放置编辑日志过大,SecondaryNameNode会定期从NameNode上下载编辑日志和镜像文件,通过加载镜像文件以及回放编辑日志生成新的镜像文件,并发送给 NameNode,这样NameNode就可以把旧的编辑日志删除。
容错
HDFS的容错可以从两个方面来看,一是数据容错,二是集群容错。
数据容错
hdfs采用副本冗余存储策略来实现数据的容错性,一个数据块默认情况下会存在三个副本,一个数据块存储在客户端所在机器上,另外两个分别存储在与第一个不同机架的不同机器上,这样在写入效率和数据容错上达到来一个比较好的平衡。
集群容错
早期版本的hadoop中,namenode存在严重的单点问题,在比较新的版本中,hadoop引入zookeeper来实现主备切换即隔离机制来保证namenode的高可用行,同时,还引入HDFS联邦来增加集群可用性和横向的扩展性。
下面看一下Hadoop高可用架构:
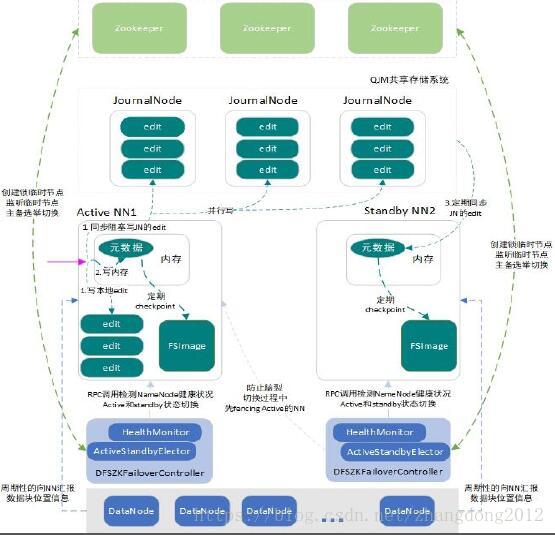
可以看到,对于元数据,引入来QJM资源共享集群,实现元数据信息的高可用。对于NameNode,采用ZKFC+Zookeeper的形式实现来自动的主被切换。同时还引入了远程接口调用+shell的方式实现NameNode的隔离,防止在主备切换的过程中发生脑裂问题。