NameNode
查看edits文件:
hdfs oev -i edits_0000000000000000022-0000000000000000023 -o edits.xml
查看fsimage文件:
hdfs oiv -i fsimage_0000000000000000024 -o fsimage.xml -p XML
fsimage_0000000000000000023.md5 — 用于校验的
VERSION
Namenode:clusterID=CID-e7c4b16d-dc36-4cca-ac67-3d28aac9dfeb
Datanode:clusterID=CID-e7c4b16d-dc36-4cca-ac67-3d28aac9dfeb — 用于进
行标记的。
SecondaryNameNode

合并过程
- 将edits和fsimage文件通过网络拷贝到Secondarynamenode上
- 在namenode产生一个edits.new记录合并期间的操作
- 拷贝完成之后,fsimage就会将其中的数据存到secondarynamenode的内
存中 - 将edits的操作更新到secondarynamenode的内存中
- 更新完成之后,将内存中的数据写到fsimage.ckpt文件中
- 通过网络将fsimage.ckpt拷贝到namenode中
- 将fsimage.ckpt重命名为fsimage,并且将edits.new也重命名为edits
合并过程
SecondaryNameNode只负责进行数据的合并,不是Namenode的热备,但是
也能起到一定的备份作用,会产生数据的丢失
Datanode
存储数据,并且是以数据块的形式来存储。
datanode存储namenode对应的clusterID以确定当前的datanode归哪一个
namenode管理
datanode每隔一段时间(3s)会主动向namenode发送心跳信息(节点状态,节
点数据)
如果namenode超过了10min没有收到datanode的心跳,则认为这个datanode
产生lost,那么namenode就会将这个datanode上的数据copy到其他节点上
HDFS的操作流程
读取数据
- 客户端发起RPC请求访问Namenode
- namenode会查询元数据,找到这个文件的存储位置对应的数据块的信
息。 - namenode将文件对应的数据块的节点地址的全部或者部分放入一个队列
中然后返回 - client收到这个数据块对应的节点地址
- client会从队列中取出第一个数据块对应的节点地址,会从这些节点地址
中选择一个最近的节点进行读取 - 将Block读取之后,对Block进行checksum的验证,如果验证失败,说明数
据块产生损坏,那么client会向namenode发送信息说明该节点上的数据
块损坏,然后从其他节点中再次读取这个数据块 - 验证成功,则从队列中取出下一个Block的地址,然后继续读取
- 当把这一次的文件块全部读完之后,client会向namenode要下一批block
的地址 - 当把文件全部读取完成之后,从client会向namenode发送一个读取完毕
的信号,namenode就会关闭对应的文件

写流程
- client发送RPC请求给namenode
- namenode接收到请求之后,对请求进行验证,例如这个请求中的文件是
否存在,再例如权限验证 - 如果验证通过,namenode确定文件的大小以及分块的数量,确定对应的
节点(会去找磁盘空间相对空闲的节点来使用),将节点地址放入队列
中返回 - 客户端收到地址之后,从队列中依次取出节点地址,然后数据块依次放
入对应的节点地址上 - 客户端在写完之后就会向namenode发送写完数据的信号,namenode会
给客户端返回一个关闭文件的信号 - datanode之间将会通过管道进行自动的备份,保证复本数量

删除流程
- Client发起RPC请求到namenode
- namenode收到请求之后,会将这个操作记录到edits中,然后将数据从内
存中删掉,给客户端返回一个删除成功的信号 - 客户端收到信号之后认为数据已经删除,实际上数据依然存在datanode上
- 当datanode向namenode发送心跳消息(节点状态,节点数据)的时候,
namenode就会检查这个datanode中的节点数据,发现datanode中的节点
数据在namenode中的元数据中没有记录,namenode就会做出响应,就
会命令对应的datanode删除指定的数据
hdfs的操作指令
hadoop fs -put a.txt /a.txt - 上传文件
hadoop fs -mkdir /hadoopnode01 - 创建目录
hadoop fs -rm /hadoop-2.7.1_64bit.tar.gz - 删除文件
hadoop fs -rmdir /hadoopnode01 - 删除目录
hadoop fs -rmr /a - 递归删除
hadoop fs -get /a.txt /home - 下载
hadoop fs -ls / - 查看
hadoop fs -lsr / - 递归查看
hadoop fs -cat /a.txt - 查看内容
hadoop fs -tail /a.txt - 产看文件的最后1000个字节
hadoop fs -mv /a/a.txt /a/b.txt - 移动或者重命名
hadoop fs -touchz /demo.txt - 创建空文件
hadoop fs -getmerge /a demo.txt - 合并下载
Hadoop插件的使用:
-
将hadoopbin_for_hadoop2.7.1.zip解压
-
复制hadoop-eclipse-plugin-2.7.1.jar 2.
-
找到eclipse的安装目录,将插件复制到eclipse安装目录下的子目录plugins
中 -
重启eclipse
-
在eclipse中指定hadoop的安装目录
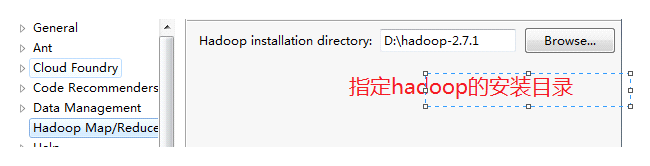
-
Window -show view

-
需要添加环境变量:HADOOP_USER_NAME=用户名
HDFS的API操作
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStream;
import java.io.OutputStream;
import java.net.URI;
import java.net.URISyntaxException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
import org.junit.Test;
public class HDFSDemo {
@Test
public void get() throws IOException, URISyntaxException {
// 创建连接
// uri - 连接地址
// conf - 配置
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(new URI("hdfs://192.168.60.132:9000"), conf);
// 获取读取文件的流
InputStream in = fs.open(new Path("/a/a.txt"));
FileOutputStream out = new FileOutputStream("a.txt");
// 读取数据
byte[] bs = new byte[1024];
int len = -1;
while ((len = in.read(bs)) != -1) {
out.write(bs, 0, len);
}
out.close();
}
@Test
public void put() throws IOException, URISyntaxException, InterruptedException {
// 创建连接
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(new URI("hdfs://192.168.60.132:9000"), conf, "root");
OutputStream out = fs.create(new Path("/a/c.txt"));
FileInputStream in = new FileInputStream("c.txt");
// byte[] bs = new byte[1024];
// int len = -1;
// while ((len = in.read(bs)) != -1) {
// out.write(bs, 0, len);
// }
//
// in.close();
IOUtils.copyBytes(in, out, conf);
}
}
MapReduce
概述:
是hadoop中的分布式的计算框架
MapReduce意味着在计算过程中实际分为两大步:Map过程和Reduce过
程。

案例:统计文件中每一个单词出现的次数
WordCountMapper
import java.io.IOException;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
// 案例:统计每一个单词出现的次数
// KEYIN - 这一行的偏移量 ---
// VALUEIN - 读取到这一行的数据
// KEYOUT - 输出的键的类型 --- 这一行中的每一个单词
// VALUEOUT - 输出的值的类型 --- 表示这一行中这个单词出现的次数
public class WordCountMapper extends Mapper<LongWritable, Text, Text, LongWritable >{
@Override
// key -- 这一行的偏移量
// value --- 这一行的数据
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, LongWritable>.Context context)
throws IOException, InterruptedException {
System.err.println(value);
// 获取到一行数据
String str = value.toString();
// 以空格为单位进行切分
String[] arr = str.split(" ");
for (String s : arr) {
context.write(new Text(s), new LongWritable(1));
}
}
}
WordCountReducer
import java.io.IOException;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
// 案例:统计每一个单词出现的次数
// KEYIN --- 单词
// VALUEIN --- 次数
// KEYOUT --- 单词
// VALUEOUT
public class WordCountReducer extends Reducer<Text, LongWritable, Text, LongWritable > {
@Override
protected void reduce(Text key, Iterable<LongWritable> arg1,
Reducer<Text, LongWritable, Text, LongWritable>.Context context) throws IOException, InterruptedException {
long sum = 0;
// 计算总的次数
for (LongWritable count : arg1) {
sum += count.get();
}
// 将单词以及对应的总次数写出
context.write(key, new LongWritable(sum));
}
}
WorldCountDriver
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WorldCountDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
// 需要给当前的job指定执行的入口类
job.setJarByClass(WorldCountDriver.class);
// 指定要执行的mapper
job.setMapperClass(WordCountMapper.class);
// 指定mapper执行完成之后的结果类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
// 指定要执行的reducer
job.setReducerClass(WordCountReducer.class);
// 指定reducer执行完成之后的结果类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
// 指定读取的文件
FileInputFormat.setInputPaths(job, new Path("hdfs://192.168.60.132:9000/mr/words.txt"));
// 指定写出的路径
FileOutputFormat.setOutputPath(job, new Path("hdfs://192.168.60.132:9000/result"));
job.waitForCompletion(true);
}
}