前言
HDFS(Hadoop Distributed File System)是基于流数据模式访问和处理超大文件的需求而开发的,它可以运行于廉价的商用服务器上。
- 大数据 基础概念
- 大数据 Centos基础
- 大数据 Shell基础
- 大数据 ZooKeeper
- 大数据 Hadoop介绍、配置与使用
- 大数据 Hadoop之HDFS
- 大数据 MapReduce
- 大数据 Hive
- 大数据 Yarn
- 大数据 MapReduce使用
- 大数据 Hadoop高可用HA
HDFS 架构
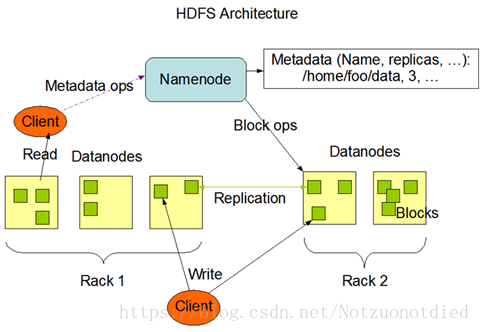
HDFS(Hadoop Distributed File System)采用了主从Master/Slave结构模型,一个HDFS集群是由一个NameNode和若干个DataNode组成的。其中NameNode作为主服务器,管理文件系统的命名空间和客户端对文件的访问操作;集群中的DataNode管理存储的数据。HDFS允许用户以文件的形式存储数据。从内部来看,文件被分成若干个数据块,而且这若干个数据块存放在一组DataNode上。NameNode执行文件系统的命名空间操作,比如打开、关闭、重命名文件或目录等,它也负责数据块到具体DataNode的映射。DataNode负责处理文件系统客户端的文件读写请求,并在NameNode的统一调度下进行数据块的创建、删除和复制工作。
NameNode是所有HDFS元数据的管理者,用户需要保存的数据不会经过NameNode,而是直接流向存储数据的DataNode。
HDFS的设计目标
- 检测和快速恢复硬件故障。【核心目标】
- 流式的数据访问。
重视数据吞吐量 - 简化一致性模型。一个文件一旦经过创建、写入、关闭就不需要修改了。
- 通信协议。所有的通信协议都是在TCP/IP协议之上的。一个客户端和明确配置了端口的名字节点
NameNode建立连接之后,它和名字节点的协议便是客户端协议Client Protocal。数据节点DataNode和名字节点之间则用数据节点协议DataNode Protocal。
HDFS的主要特点
| 特点 | 说明 |
|---|---|
| 处理超大文件 | 数百MB,乃至TB、PB级的数据。 |
| 流式访问数据 | “一次写入、多次读取”,这意味着一个数据集一旦由数据源生成,就会被分发到不同的存储结点,响应各种数据分析要求。 |
| 运行在廉价的商用机器集群上 | 廉价的机器也意味着出现节点故障的概率非常高。这就要求HDFS在设计的时候需要充分考虑数据的可靠性、安全性和高可用性。 |
HDFS的局限性
| 局限性 | 说明 |
|---|---|
| 不适合低延迟的网络访问 | HDFS是为了处理大型数据集分析任务,主要是为达到高的数据吞吐量而设计的,这就要求可能以高延迟作为代价。补充方案HBase。 |
| 无法高效存储大量小文件 | 在Hadoop中需要用NameNode管理文件系统的元数据。每个文件、索引目录以及块大约需要占用100字节,一旦有1千万个文件,每个文件占一个块,那么至少需要消耗2G的内存。如果更多,机器很难满足这些这个要求,而且检索元数据的时间也将难以接受。 |
| 不支持多用户写入及任意修改文件 | 只允许一个写入者,只允许在末尾追加数据。 |
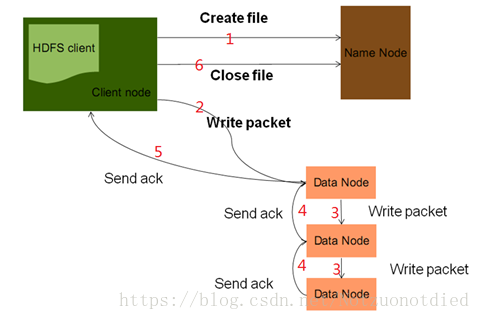
HDFS 文件写入原理
| 序号 | 说明 |
|---|---|
| 1 | Client向NameNode发起文件写入请求。NameNode会检查目标文件是否存在,父目录是否存在,然后会判断此客户端是否有写权限。如果都满足,NameNode会给客户端返回一个输出流。此外,NameNode会为文件分配块存储信息。注意,NameNode也是分配块的存储信息,但不做物理切块工作。 |
| 2 | 客户端拿到输出流以及块存储信息之后,就开始向DataNode写数据。因为一个块数据,有三个副本,所以图里有三个DataNode。Packet初学时可以简单理解为就是一块数据。 |
| 3 | 数据块的发送,先发给第一台DataNode,然后再有第一台DataNode发往第二台DataNode……实际这里,用到了pipeLine数据流管道的思想。 |
| 4 | 通过ack确认机制,向上游节点发送确认,这么做的目的是确保块数据复制的完整性。 |
| 5 | 通过最上游节点,向客户端发送ack,如果块数据没有发送完,就继续发送下一块。如果所有块数据都已发完,就可以关流了。 |
| 6 | 所有块数据都写完后,关流。 |
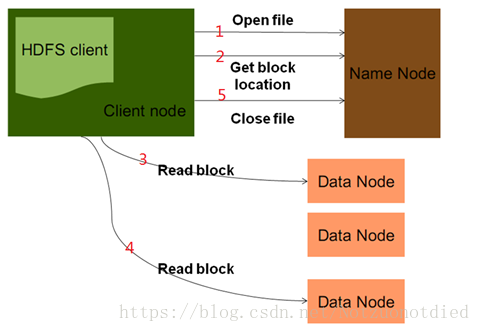
HDFS 文件读取原理
| 序号 | 说明 |
|---|---|
| 1 | 客户端发出读数据请求,Open File指定读取的文件路径,去找NameNode要元数据信息。 |
| 2 | NameNode返回文件存储的DataNode信息给Client。(就近原则、然后随机访问) |
| 3 | Client根据返回的元数据信息,去对应的DataNode去读Block数据。假如一个文件特别大,比如1TB,会分成好多块,此时,NameNode并是不一次性把所有的元数据信息返回给客户端。 |
| 4 | 客户端读完此部分后,再去想NameNode要下一部分的元数据信息,再接着读。 |
| 5 | 读完之后,通知NameNode关闭流。 |
HDFS 三个安全措施
HDFS Block的放置策略
假如有三份数据。
| 编号 | 放置位置 |
|---|---|
| 1 | 第一份Block放在NameNode指定的DataNode上。 |
| 2 | 第二份Block副本放置在与第一个DataNode节点相同的机架中的另一个DataNode中(随机选择)。 |
| 3 | 第三份Block副本放置于另一个随机远端机架的一个随机DataNode中。 | |
| 说明(参见自:HDFS block块的副本存放策略) |
|---|
将第一、二个Block副本放置在同一个机架中,当用户发起数据读取请求时可以较快地读取,从而保证数据具有较好的本地性。 |
第三个及更多的Block副本放置于其他机架,当整个本地结点都失效时,HDFS将自动通过远端机架上的数据副本将数据副本的娄得恢复到标准数据。 |
Hadoop的副本放置策略在可靠性(Block在不同的机架)和带宽(一个管道只需要穿越一个网络节点)中做了一个很好的平衡。 |
HDFS 安全模式
在Hadoop启动NameNode的时候,会启动安全模式(safemode),在该模式下,NameNode会等待DataNode向它发送块报告(block report),只有接收到的DataNode上的块数量(datanodes blocks)和实际的数量(total blocks)接近一致, 超过datanodes blocks / total blocks >= 99.9%这个阀值,就表示 块数量一致,就会推出安全模式。达到99.9%的阀值之后,文件系统不会立即推出安全模式,而是会等待30秒之后才会退出。
- 更多请参见:HDFS安全模式详解
比如在启动Hadoop的HDFS的
内执行一个任务,将会出现Name node is in safe mode.(目前处于安全模式) 的错误:
[root@node0 opt]# hadoop jar hdfs-1.0-SNAPSHOT.jar WordCountDriver /data/input /data/output11
18/09/18 02:18:08 INFO client.RMProxy: Connecting to ResourceManager at node1/192.168.80.9:8032
18/09/18 02:18:09 WARN mapreduce.JobResourceUploader: Hadoop command-line option parsing not performed. Implement the Tool interface and execute your application with ToolRunner to remedy this.
18/09/18 02:18:09 INFO mapreduce.JobSubmitter: Cleaning up the staging area /tmp/hadoop-yarn/staging/root/.staging/job_1537251454694_0001
Exception in thread "main" org.apache.hadoop.ipc.RemoteException(org.apache.hadoop.hdfs.server.namenode.SafeModeException): Cannot delete /tmp/hadoop-yarn/staging/root/.staging/job_1537251454694_0001. Name node is in safe mode.(目前处于安全模式)
The reported blocks 9 has reached the threshold 0.9990 of total blocks 9. The number of live datanodes 3 has reached the minimum number 0. In safe mode extension. Safe mode will be turned off automatically in 14 seconds.(需要等待14s后自动退出安全模式)
……
主要内容是部分的内容:

Name node is in safe mode.(目前处于安全模式)
The reported blocks 9 has reached the threshold 0.9990 of total blocks 9.
The number of live datanodes 3 has reached the minimum number 0.
In safe mode extension.
Safe mode will be turned off automatically in 14 seconds.
(需要等待14s后自动退出安全模式)
异常情况导致进入安全模式
- 原因:当
NameNode发现集群中的Block丢失数量达到一个阀值时,NameNode就进入安全模式状态,不再接受客户端的数据更新请求。 - 措施:可以手动让
NameNode退出安全模式,bin/hdfs dfsadmin -safemode leave,或者:调整safemode门限值:dfs.safemode.threshold.pct=0.999f。
HDFS 文件安全
NameNode的重要性是显而易见的,在实际应用中,常将NameNode上的持久化存储的元数据文件转储到其他文件系统中,这种转储是同步的、原子的操作。
在Hadoop系统中,系统同步运行一个Secondary NameNode。这个结点的主要作用就是周期性地合并编辑日志中的命名空间镜像,以避免编辑日志过大。Secondary NameNode需要占用大量的CPU、内存去做合并操作,因此常常将Secondary NameNode防止在单独一台机器上。在这台机器上定时合并NameNode上的镜像文件和日志,但是由于Secondary NameNode的同步备份总是滞后于NameNode,所以损失是必然的。
HDFS 文件块Block的复制
| 序号 | 说明 |
|---|---|
| 1 | NameNode发现部分文件的Block不符合最小复制数这一要求或者部分DataNode失效。 |
| 2 | 通知DataNode相互复制Block。 |
| 3 | DataNode开始直接相互复制。 |
HDFS 数据管道的写入
当客户端要写入文件到DataNode上时,首先会读取一个Block,然后将其写到第一个DataNode上,接着由第一个DataNode将其传递到备份的DataNode上,直到所有需要写入这个Block的DataNode都成功写入后,客户端才会开始写下一个Block。
HDFS 超时时间设置
DataNode进程死亡或者网络故障造成DataNode无法与NameNode通信,NameNode不会立即把该节点判定为死亡,要经过一段时间,这段时间暂称作超时时长。HDFS默认的超时时长为
。如果定义超时时间为timeout,则超时时长的计算公式为:
而默认的
大小为
,
默认为
。需要注意的是hdfs-site.xml配置文件中的
的单位为毫秒,
的单位为秒。
举个例子,如果 设置为 (毫秒,默认), 设置为 (秒,默认),则总的超时时间为 。
hdfs-site.xml中的参数设置格式:
<property>
<name>heartbeat.recheck.interval</name>
<value>5000</value>
</property>
<property>
<name>dfs.heartbeat.interval</name>
<value>3</value>
</property>
HDFS 冗余数据块的自动删除
在日常维护Hadoop集群的过程中发现这样一种情况:某个节点由于网络故障或者DataNode进程死亡,被NameNode判定为死亡,HDFS马上自动开始数据块的容错拷贝;当该节点重新添加到集群中时,由于该节点上的数据其实并没有损坏,所以造成了HDFS上某些Block的备份数超过了设定的备份数。通过观察发现,这些多余的数据块经过很长的一段时间才会被完全删除掉,那么这个时间取决于什么呢?
该时间的长短跟数据块报告的间隔时间有关。Datanode会定期将当前该结点上所有的Block信息报告给Namenode,参数
就是控制这个报告间隔的参数。
hdfs-site.xml文件中有一个参数:
<property>
<name>dfs.blockreport.intervalMsec</name>
<value>3600000</value>
<description>Determines block reporting interval in milliseconds.</description>
</property>
其中 为默认设置, 毫秒,即 ,也就是说,块报告的时间间隔为 ,所以经过了很长时间这些多余的块才被删除掉。通过实际测试发现,当把该参数调整的稍小一点的时候( ),多余的数据块确实很快就被删除了。
附录
- 《Hadoop实战(第2版)》陆嘉恒著
- Hadoop架构