大数据hadoop学习【13】-----通过JAVA编程实现对MapReduce的数据进行排序目录
上次的博客中,林君学长通过java编程实现了对MapReduce的数据去重;本次博客,我们将深入了解MapReduce,并通过java编程实现对文件数据中数据的排序,一起看步骤吧!
- 本次排序要求: 对输入文件中数据进行排序。输入文件中的每行内容均为一个数字,即一个数据。要求在输出中每行有两个间隔的数字,其中,第一个代表原始数据在原始数据集中的位次,第二个代表原始数据。
一、数据准备
1、ubuntu文件系统中准备对应数据文件
1)、在对应位置创建file3.txt文件,并写入相关数据:文件中的每行都是一个数据
(1)、创建file3.txt文件,并打开
cd ~/lenovo/data
touch file3.txt
gedit file3.txt
其中 ~/lenovo/data为林君自己创建的文件夹
(2)、写入文件内容如下所示:
2
32
654
32
15
756
65223
2)、在相同位置创建file4.txt文件,并写入数据,两个文件中的数据应该要有相同的和不同的,且文件中的每行都是一个数据
(1)、创建file4.txt文件,并打开
touch file4.txt
gedit file4.txt
(2)、写入文件内容如下所示:
5956
22
650
92
3)、在相同位置创建file5.txt文件,并写入数据,两个文件中的数据应该要有相同的和不同的,且文件中的每行都是一个数据
(1)、创建file5.txt文件,并打开
touch file5.txt
gedit file5.txt
(2)、写入文件内容如下所示:
26
54
6
2、运行hadoop
1)、终端输入以下命令运行hadoop
start-dfs.sh
2)、查看hadoop是否成功运行
jps
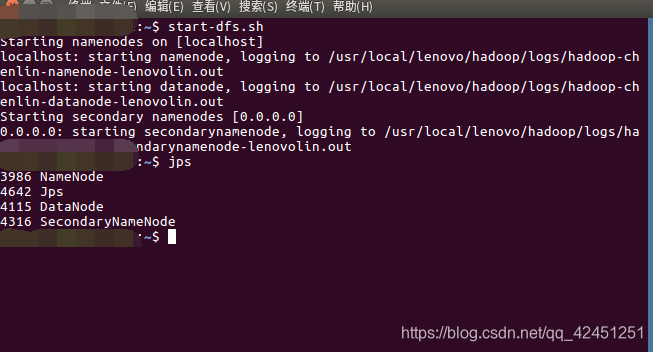
出现以上4个节点则为成功运行!
3、将文件上传至hadoop文件系统
1)、在hdfs文件系统中创建file2目录用来存放我们上传的文件
hdfs dfs -mkdir /user/hadoop/file2
2)、将file3.txt文件上传至hdfs文件系统中的file2目录
hdfs dfs -put ~/lenovo/data/file3.txt /user/hadoop/file2
3)、将file4.txt文件上传至hdfs文件系统中的file2目录
hdfs dfs -put ~/lenovo/data/file4.txt /user/hadoop/file2
4)、将file5.txt文件上传至hdfs文件系统中的file2目录
hdfs dfs -put ~/lenovo/data/file5.txt /user/hadoop/file2

5)、查看文件是否上传成功
hdfs dfs -ls /user/hadoop/file2

6)、查看文件内容是否一致
hdfs dfs -cat /user/hadoop/file2/file3.txt
hdfs dfs -cat /user/hadoop/file2/file4.txt
hdfs dfs -cat /user/hadoop/file2/file5.txt

二、编写java程序
1、打开eclipse,编写数据排序的java代码
1)、新建类Sort ,其中java代码如下所示:
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
import java.io.IOException;
/**
* 数字排序
*/
public class Sort{
/**
* 使用Mapper将数据文件中的数据本身作为Mapper输出的key直接输出
*/
public static class forSortedMapper extends Mapper<Object, Text, IntWritable, IntWritable> {
private IntWritable mapperValue = new IntWritable(); //存放key的值
public void map(Object key, Text value, Context context)
throws IOException, InterruptedException {
String line = value.toString(); //获取读取的值,转化为String
mapperValue.set(Integer.parseInt(line)); //将String转化为Int类型
context.write(mapperValue,new IntWritable(1)); //将每一条记录标记为(key,value) key--数字 value--出现的次数
//每出现一次就标记为(number,1)
}
}
/**
* 使用Reducer将输入的key本身作为key直接输出
*/
public static class forSortedReducer extends Reducer<IntWritable, IntWritable, IntWritable, IntWritable>{
private IntWritable postion = new IntWritable(1); //存放名次
@SuppressWarnings("unused")
@Override
protected void reduce(IntWritable key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
for (IntWritable item :values){ //同一个数字可能出多次,就要多次并列排序
context.write(postion,key); //写入名次和具体数字
System.out.println(postion + "\t"+ key);
postion = new IntWritable(postion.get()+1); //名次加1
}
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration(); //设置MapReduce的配置
String[] otherArgs = new GenericOptionsParser(conf,args).getRemainingArgs();
if(otherArgs.length < 2){
System.out.println("Usage: Sort <in> [<in>...] <out>");
System.exit(2);
}
//设置作业
//Job job = new Job(conf);
Job job = Job.getInstance(conf);
job.setJarByClass(Sort.class);
job.setJobName("SortedData");
//设置处理map,reduce的类
job.setMapperClass(forSortedMapper.class);
job.setReducerClass(forSortedReducer.class);
//设置输入输出格式的处理
job.setOutputKeyClass(IntWritable.class);
job.setOutputValueClass(IntWritable.class);
//设定输入输出路径
for (int i = 0; i < otherArgs.length-1;++i){
FileInputFormat.addInputPath(job,new Path(otherArgs[i]));
}
FileOutputFormat.setOutputPath(job, new Path(otherArgs[otherArgs.length-1]));
System.exit(job.waitForCompletion(true)?0:1);
}
}
在MapReduce流程中,Map的输出<Key,value>经过shuffle过程聚集成<key,value-list>后会被交给Reduce。所以从设计好的Reduce输入可以反推出Map的输出的Key应为数据,而value为任意值。继续反推,Map输出的Key为数据。而在这个实例中每个数据代表输入文件中的一行内容,所以Map阶段要完成的任务就是在采用Haodoop默认的作业输入方式之后,将value设置成Key,并直接输出(输出中的value任意)。Map中的结果经过shuffle过程之后被交给reduce。在Reduce阶段不管每个Key有多少个value,都直接将输入的Key复制为输出的Key,并输出就可以了(输出中的value被设置成空)
2)、运行,测试代码没有问题
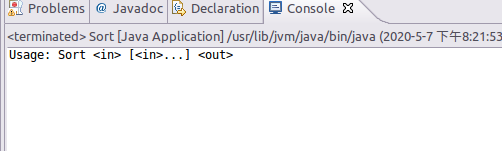
控制台出现如上显示则代码没有问题!
2、将java文件打包成jar
1)、按照如下截图步骤镜像jar打包

2)、选择JAR file

3)、选择导出的类和导出路径

4)、点击ok
5)、导出成功
出现finished则为导出成功!
6)、找到对应路径,查询该包是否成功导出
出现以上箭头的jar包,则导出成功,然后关闭eclipse
三、结果测试
1、终端运行jar包
1)、终端输入如下命令运行我们导出的jar包
hadoop jar ~/lenovo/bigData/myapp/Sort.jar /user/hadoop/file2 /user/hadoop/output3
提示: 路径 /user/hadoop/output3中的output3不用我们创建,该命令会自动帮我们创建的,但我们输入的output3是要保证hdfs中没有与之相同的名称哦,不然会报错的,其中 /user/hadoop/file2是我们创建好的保存测试文件的目录哦!
2)、出现如下界面则为成功运行


2、查看运行结果
1)、终端输入以下命令查看我们排序的结果
hdfs dfs -cat /user/hadoop/output3/*
2)、查看结果如下所示:

3、运行结果分析
1)、最开始的三个文件数据及最后运行结果的数据如下所示:


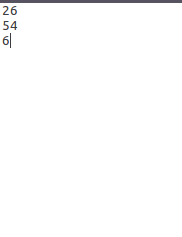
上面的左边为file3.txt,中间为file4.txt,右边为为file5.txt
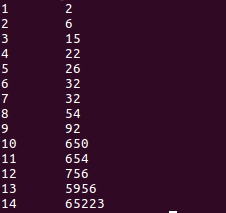
上面为最终的运行结果
2)、在上面的结果中我们可以看出,运行出来的结果将我们上面三个文件的结果相结合为一个文件
3)、除此之外,该代码还实现了对数据的排序从小到大依次排序成功,达到了我们要求的结果展示!
4)、需要注意的是:如果要再次运行Sort.jar,需要首先删除HDFS中的output3目录,否则会报错
4、实验结束,关闭hadoop
stop-dfs.sh
以上就是本次博客的全部内容啦,通过对本次博客的阅读,希望小伙伴理解如何通过java对MapReduce的数据进行操作,进而理解原理,这样以后的编程中,就可以通过原理编程,而不是面向百度编程!
遇到问题的小伙伴记得留言评论哦,林君学长看到会为大家解答的,这个学长不太冷!
陈一月的又一天编程岁月^ _ ^
