1、概念
HDFS是Hadoop Distribute File System 的简称,意为:Hadoop 分布式文件系统。是 Hadoop 核心组件之一,作为最底层的分布式存储服务而存在。它是一个文件系统,用于存储文件,通过目录树来定位文件;其次,它是分布式的,由很多服务器联合起来实现其功能,集群中的服务器有各自的角色。
2、优点
- 适合大数据处理:能够处理百万规模以上的文件数量( GB、TB、PB级数据),能够处理10K节点的规模
- 处理非结构化的数据:可处理结构化、半结构化、非结构化的数据(语音、视频、图片),80% 的数据都是非结构化的数据
- 流式访问数据:一次写入,多次读取。文件一旦写入不能修改,只能追加。它能保证数据的一致性。
- 运行于廉价的商用机器集群上: 它通过多副本机制,提高可靠性。一旦出现故障也不会影响正常的业务处理,可以通过其它副本来恢复。
3、缺点
-
不适合处理低延迟的数据访问: HDFS是为了处理大型数据集分析任务的,主要是为了达到高的数据吞吐量而设计的, HBase适合做低延迟的数据访问BigTable
-
无法高效的存储大量小文件:当文件以block块的形式进行存储时,block块的位置会存储在namenode节点的内存中不论存储大文件还是小文件,每个文件对应的单条block的块信息大小是一致的 而NameNode的内存总是有限的。小文件存储的寻道时间会超过读取时间,违反了HDFS的设计目标。(这里的小文件是指小于HDFS系统的Block大小的文件,默认是128M)
-
不支持并发写入和任意的修改: 一个文件同时只能有一个写,不允许多个线程同时写。 仅支持数据append(追加),不支持文件的随机修改。以追加的形式达到修改的目的
4、功能
- 分布式存储:在HDFS中NameNode负责管理HDFS文件系统的元数据,而实际的数据则是存储于该文件系统的DataNode节点中,具体位置由文件系统的机架感知功能分配,元数据则是记录文件具体内容。
- 命名空间管理:HDFS的命名空间包含目录、文件和块的信息。命名空间支持对HDFS中的目录、文件和块做创建、修改、删除、列表文件和目录等基本操作。
- 块/存储管理: 在块存储服务中包含两部分工作:块管理和物理存储。(这是一个更通用的存储服务。其他的应用可以直接建立在Block Storage上,如HBase,Foreign Namespaces等)
块管理:
A) 处理DataNode向NameNode注册的请求,处理datanode的成员关系。
B) 处理来自DataNode周期性的心跳报告,维护块的位置信息。
C) 处理与块相关的操作:块的创建、删除、修改及获取块信息。
D) 管理副本放置(replica placement)和块的复制及多余块的删除。
物理存储:
Data Node把块存储到本地文件系统中,对本地文件系统的读写。
5、特性
-
高容错:数据自动保存多个副本。它通过增加数据冗余来提高容错性。某一个副本丢失以后,它可以自动恢复
-
可扩展:可以不断的添加新的datanode
-
可配置性强:诸多集群属性可通过增加或者修改配置文件来更改
-
跨平台:Java语言开发的,HDFS支持多个平台Windows
-
shell命令接口:例如
hadoop fs -put 上传,把本地Linux文件系统的文件,上传到HDFS文件系统中
hadoop fs -ls hdfs://master:9000/ 查看HDFS文件系统根目录(/)下的文件
… -
机架感知功能:副本的存放,第一个存到rack1,第二个就会选择不同于rack1的其他的rack上面存储 /etc/hosts
-
负载均衡:理想状态下,集群中每个服务器上面存储数据都是均匀的。但在实际当中,经常会出现数据偏移
-
提供Web界面:
http://master:8088 yarn
http://master:50070 hdfs
6、结构
这种文件系统是由多台节点组合成集群来实现的,由三个角色组成分别为:NameNode、DataNode、SecondaryNameNode。
- NameNode:负责管理整个文件系统的元数据,以及每个文件对应的数据块信息
- DataNode:数据节点,用来存储文件的真实数据块
- SecondaryNameNode:监控HDFS状态的后台程序,每隔一段时间自动获取HDFS元数据的快照
7、名词解释
- 元数据:对于在HDFS上存储的文件都会有其对应的数据,包括文件的存储节点、文件分块状态、块id、等等
- 数据块:对于HDFS上的所有文件在物理层面上都是分块存储的,默认块大小是128m ,默认备份为3份。
对于实际大小不满足128m的文件按照一块存储,对于超过128m的文件进行以128m为单位切分多块存储,默认块大小可以在停了集群之后在hdfs-site.xml中进行配置再重启集群生效
<property>
<name>dfs.blocksize</name>
<value>256m</value>
</property>
<property>
<name>dfs.namenode.fs-limits.min-block-size</name>
<value>256m</value>
</property>
- 默认块大小
在Hadoop1.x版本中,默认块大小为64m,在hadoop.x版本中默认块大小是128m。
block块的大小主要取决于磁盘的传输速率,hdfs的平均寻址时间为10ms,普遍认为巡视时间为传输数据时间的1%时为最佳状态,即传输时间为1s,机械硬盘文件顺序读写的速度为100mb/s,普通固态的速度为500mb/s,pcie固态的最高速度可达2000mb/s,因为文件的大小是由二进制计算的,所以块的大小可计算出得128m,256m以及2048m - 块数据
以上传的大小为176m的jdk为例。按照默认块大小为128m来讲,该文件应该被分为两块,大小分别为128m和48m,点开jdk-8uxxxxxx后就会显示出以下信息


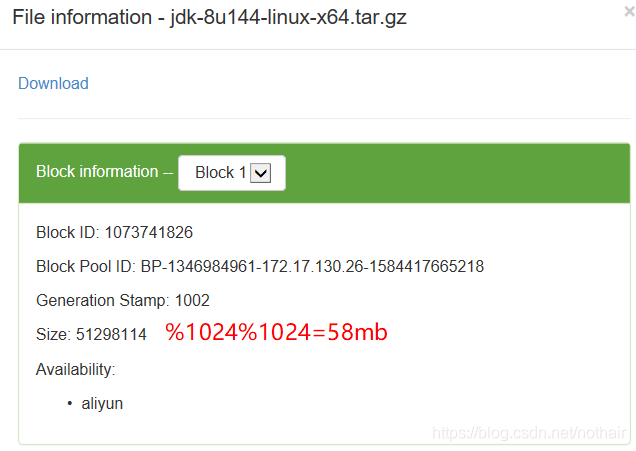

结合dataNode数据存储位置查看实际的数据块信息,可以得出结论
- 通过BlockID:确定具体数据块
- 通过Block Pool ID:每个namenode都会有对应的一个Block Pool ID
- Generation Stamp:文件名+该文件的Generation Stamp即为校验文件,文件格式为xxx.meta
- Size:块大小,单位为byte
- Availability:该数据块所在的节点