Probability Theory focus on computing the probability of data arising from a parametric model with known parameters. Statistical Inference flips this on its head: we will estimate the probability of parameters given a parametric model and observed data drawn from it.
比如我得到了一些样本数据,并已知这些数据底层的分布是指数分布,但是并不知道具体是哪个指数分布!因为指数分布不是一个确定的分布,而是 one-parameter family of distributions. 不同的参数
在这篇文章中,我将介绍一些方法,用给定的数据和参数模型,来估算出这些未知的 population parameters:
- a population mean
μ - the difference in two population means
μ1−μ2 - a population variance
σ2 - the ratio of two population variances
σ21/σ22
Point Estimation VS Interval Estimation
下面是维基百科中关于 Point Estimation 的定义:
In statistics, point estimation involves the use of sample data to calculate a single value which is to serve as a “best guess” or “best estimate” of an unknown population parameter. More formally, it is the application of a point estimator to the data.
下面是维基百科中关于 Interval Estimation 的定义:
In statistics, interval estimation is the use of sample data to calculate an interval of plausible values of an unknown population parameter; this is in contrast to point estimation, which gives a single value.
下面是维基百科中关于 Confidence interval 的定义:
In statistics, a confidence interval is a type of interval estimate (of a population parameter) that is computed from the observed data. The confidence level is the frequency (i.e., the proportion) of possible confidence intervals that contain the true value of their corresponding parameter. In other words, if confidence intervals are constructed using a given confidence level in an infinite number of independent experiments, the proportion of those intervals that contain the true value of the parameter will match the confidence level.
如果你对上面关于 Confidence interval 的定义有些不太理解,没有关系。当我介绍到如何解释一个 Confidence interval 的含义时,你会对这个定义理解的更加深刻。实际上,Interval Estimation 包含很多种方法,但是在这篇文章中我只介绍 confidence intervals.
Point Estimation
假设我们想知道中国人每天读书的平均时间,
我们有2种方法可以做这样的估算,它们分别是 maximum likelihood estimation 和 method of moments. 在这个小节中,我也会介绍一种方法来评估某个点估计是否为一个 “好” 的点估计。
在介绍这个点估计的方法之前,我先来介绍一下 point estimator(点估计量) 与 point estimate(点估计值) 的含义。
point estimator VS point estimate
We denote the
The corresponding observed values of a specific random sample are then denoted as subscripted lowercase letters:
比如上面那个读书时间的例子,我们一共寻问了100个中国人,那么我们就得到了100个随机变量,
下面是 point estimator 的定义:
The function of
X1,X2,⋯,Xn used to estimateθ is called a point estimator ofθ . For example, the function:X¯=1n∑i=1nXi is a point estimator of the population meanμ ; The function:S2=1n−1∑i=1n(Xi−X¯)2 is a point estimator of the population varianceσ2 .
下面是 point estimate 的定义:
The function computed from a set of data is an observed point estimate of
θ . For example, ifxi are the observed grade point averages of a sample of 88 students, then:x¯=188∑i=188xi=3.12 is a point estimate ofμ .
Maximum Likelihood Estimates
有很多方法可以从已知的数据中估算出未知的 population parameters,在这个小节中我会介绍最大似然估计,它属于点估计,它回答的是这样一个问题:
For which parameter value does the observed data have the biggest probability?
接下来,我会用最大似然估计分别求解一个离散的和连续的例子,让大家可以更好的理解它。假设我投掷100次硬币,出现了55个正面,很明显这是一个二项分布,它的参数是 n 和 p,由于 n = 100,现在就只剩下一个未知参数 p 了。那么现在我们很自然的会问这样一个问题:哪个 p 值会最大化观察到的数据的概率。因此我们可以写成一个关于参数 p 的函数:
上面的函数叫做 likelihood function,它可以解释成:the probability of 55 heads given p? 毋庸置疑,接下来的任务就是找出 p 值,最大化这个概率,剩下的任务找微积分搞定吧,这里我就不多说了。通过这个例子,我们可以给出最大似然估计的定义:
Given data the maximum likelihood estimate (MLE) for the parameter p is the value of p that maximizes the likelihood P(data | p). That is, the MLE is the value of p for which the data is most likely.
有时我们会把 likelihood function 取对数,这样会简化计算过程。由于 log 函数是单调递增的,likelihood function 和 取对数之后的 likelihood function 它们最终得到的结果是一致的!
接下来,我再介绍一个关于连续型的例子。假设一种品牌的燎灯泡的寿命服从指数分布,当然我们不知道这个指数分布的参数
令
我们把数据代入到上面的 likelihood function 中, 就可以得到一个关于未知参数
接下来你就可以用微积分的知识去找到上面函数取到最大值时,
如果你想看更多的例子,请参考:Maximum Likelihood Estimates
Method of Moments
如果用一句话总结矩估计就是:让 sample moments 等于 theoretical moments. 在给出矩估计的步骤之前,我们首先应该知道什么是 sample moment 和 theoretical moment.
Theoretical moment 的定义:
-
E(Xk) is thekth theoretical moment of the distribution about the origin.k=1,2,⋯ -
E[(X−μ)k] is thekth theoretical moment of the distribution about the mean.k=1,2,⋯
Sample moment 的定义:
-
Mk=1n∑i=1nXki is thekth sample moment about the origin.k=1,2,⋯ -
M∗k=1n∑i=1n(Xi−X¯)k is thekth sample moment about the mean.k=1,2,⋯
上面的定义很好理解,没什么多说的了!有了这些定义,矩估计的步骤就很好描述了。Theoretical moment 和 Sample moment 都有2种不同的形式,分别是 about the origin 和 about the mean. 与定义一致,矩估计的步骤也有2种形式。
About the origin 的矩估计步骤:
- 让 k=1下的 Sample moment = Theoretical moment. 即让
M1=1n∑i=1nXi=X¯ 等于E[X] - 让 k=2下的 Sample moment = Theoretical moment. 即让
M2=1n∑i=1nX2i 等于E[X2] - 让k不断增加,按照这种形式提到等式,直到你有足够多的等式可以求出未知参数; 比如你只有一个未知参数,那一个等式就足够了,就完全不需要在k=2,3,4… 情况下的等式了!
About the mean 的矩估计步骤:
这里我就不描述了,步骤完全与上面一样,你只需要把 about the origin 的定义替换成 about the mean 就可以了。
Confidence Intervals
在上面点估计的小节中,我介绍了一些方法估算 population parameters ,比如用 sample mean
显然点估计不能回答这样的问题!Rather than using just a point estimate, we could find an interval of values that we can be really confident contains the actual unknown population parameter. For example, we could find lower
An interval of such values is called a confidence interval. Each interval has a confidence coefficient:
or a confidence level
Typical confidence coefficients are 0.90, 0.95, and 0.99, with corresponding confidence levels 90%, 95%, and 99%. For example, upon calculating a confidence interval for a mean with a confidence level of, say 95%, we can say:
“We can be 95% confident that the population mean falls between L and U.”
这个小节的主要目的就是估算出 population mean
| population parameter | 假设 |
|
查表 |
|---|---|---|---|
|
|
population variance 已知 |
|
Z-Table |
|
|
population variance 未知 |
|
T-Table |
|
|
population variance 未知,但是
|
|
T-Table |
|
|
population variance 未知,并且
|
(
|
T-Table |
|
|
无 |
|
Chi-squared Table |
|
|
无 |
|
F Distribution Tables |
上表中的每一行对应下面的每个小节,各个小节中都会对相应的置信区间做出详细的解释!
A Z-Interval for a Mean
上面表格中已经给出了关于
-
x¯ 为样本均值 -
σ 为 population standard deviation -
n 为样本数量 -
zα/2 是面积为α/2 时的 Z-score
文章中交警吸汽车尾气的例子很好,我用这个例子教大家如何查询 Z-Table 得到 Z-score. 例子具体内容我就不说了,大家直接去网站看。这个例子的答案要求得到一个 95% 的置信区间,即
-
−zα/2 所对应的面积为α/2=0.025 ,通过查询 Z-Table, 面积为 0.025 对应的 Z-score 为 -1.96 -
zα/2 所对应的面积为α/2+(1−α)=0.975 ,通过查询 Z-Table, 面积为 0.975 对应的 Z-score 为 1.96
下图为 standard normal curve:
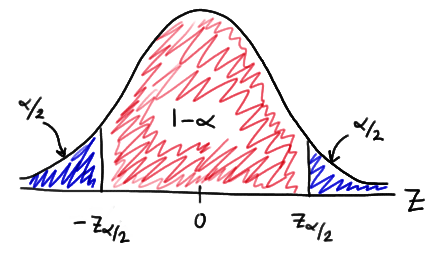
想更多的了解 Z-Score,请参考我先前写的这篇文章:统计学知识; 关于如何解释这个例子中得到的置信区间,这篇文章中已经给出了非常好的解释:Interpretation.
A t-Interval for a Mean
Z-Interval 假设 population variance 是已知的,而 t-Interval 并没有这样的假设。因此我们只能用已知的数据来估算出一个样本方差:
上面表格中已经给出了关于
-
x¯ 为样本均值 -
s 为样本标准差 -
n 为样本数量 -
tα/2,n−1 是面积为α/2 , 自由度为n−1 时的 t-score
查表过程也很简单,你只需要确定自由度和相应的面积就能得到 t-score 了。下图是一个自由度为
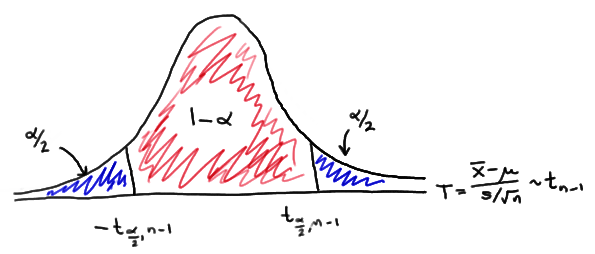
Two-Sample Pooled t-Interval
上面表格中已经给出了关于
下面是公式中各项所表示的含义:
-
x¯ 为随机变量 X 的样本均值 -
y¯ 为随机变量 Y 的样本均值 -
n 为随机变量 X 的样本数量 -
m 为随机变量 Y 的样本数量 -
S2p 为 pooled sample variance
-
S2X 为随机变量 X 的样本方差 -
S2Y 为随机变量 Y 的样本方差
-
-
tα/2,n+m−2 是面积为α/2 , 自由度为n+m−2 时的 t-score
不难发现,The pooled sample variance
Welch’s t-Interval
除了自由度的计算与 Two-Sample Pooled t-Interval 不一样之外,置信区间其余各项表示的含义全部一样。计算自由度的公式如下:
如果求出的 r 是小数,你可以直接取整数部分!
One Variance
下面是置信区间中各项所表示的含义:
-
a=χ21−α/2,n−1 -
b=χ2α/2,n−1 -
n 为样本数量 -
s2 为样本方差
要想得到a与b的值,去查 Chi-squared distribution 的表格就可以了。下图就是一个 Chi-squared distribution:
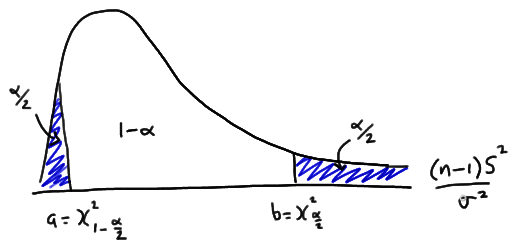
Two Variances
下面是公式中各项所表示的含义:
-
S2X 为随机变量 X 的样本方差 -
S2Y 为随机变量 Y 的样本方差 -
n 为随机变量 X 的样本数量 -
m 为随机变量 Y 的样本数量 -
Fα/2(n−1,m−1) 是面积为α/2 , 自由度为n−1 和m−1 时的 F-score
下图中蓝色区域就是
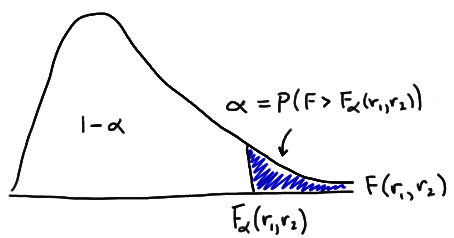
Hypothesis Testing
点估计和区间估计都是用已知的数据去估算出未知的 population parameter. 而 hypothesis testing 要学习的是:population parameter 是否等于某个值,比如成人的平均体温是否为37. hypothesis test 的步骤为:
- We’ll make an initial assumption about the population parameter.
- We’ll collect evidence or use somebody else’s evidence (in either case, our evidence will come in the form of data).
- Based on the available evidence (data), we’ll decide whether to “reject” or “not reject” our initial assumption.
接下来举个例子,大家一下子就能明白了!在举例子之前,我有必要先提一下 中心极限定理,它得到的结论是:可以把 i.i.d 随机变量的 sum 或者 average 看作是正态分布。
例子 大致题意:某个年龄段的孩子的平均体重是 85 pounds,但是一些人认为某些地区的孩子由于营养不良,体重并没有达到平均标准,于是他们去调查了这个地区的25个男孩,具体数据请参考原文!
解答:根据我上文中给出的假设检验步骤,我们首先应该给出一个 initial assumption,即
通过这次调查的25个男孩你会得到一个
由于是 Z-test,我们需要得到Z-score(其它的 t-test 同理,应该得到 t-score). 因此需要转化成标准正态分布。由于题目中已经给出了
当我们把 significance level 设为
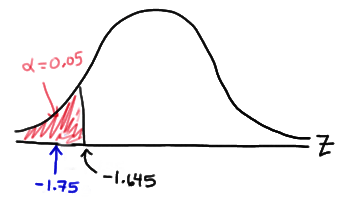
文章中有更多这样的例子:Hypothesis Testing
Possible Errors
Every time we conduct a hypothesis test, we have a chance of making an error. There are two kinds of errors:
1、If we reject the null hypothesis
2、If we fail to reject the null hypothesis when the null hypothesis is false, we say we’ve committed a Type II error.