自己写一遍比较好,加了一些注释
import torch
from torch.autograd import Variable
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
# http://www.bubuko.com/infodetail-2305871.html
# https://blog.csdn.net/qq_16309049/article/details/73497550
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
# 1 input image channel, 6 output channels, 5x5 square convolution
# kernel
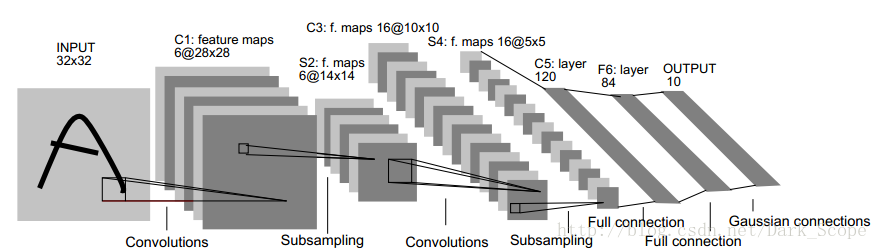
self.conv1 =nn.Conv2d(1,6,5)
self.conv2 =nn.Conv2d(6,16,5)
# an affine operation: y = Wx + b
self.fc1 = nn.Linear(16*5*5,120)
self.fc2 =nn.Linear(120,84)
self.fc3 =nn.Linear(84,10)
def forward(self, x):
# Max pooling over a (2,2) window
# 输入x->conv1->relu->2x2窗口的最大池化->更新到x
x=F.max_pool2d(F.relu(self.conv1(x)),(2,2))
# If the size is a square you can only specify a single number
# 如果大小是一个正方形,可以只指定一个数字
x=F.max_pool2d(F.relu(self.conv2(x)),2)
# view函数将张量x变形成一维向量形式,总特征数不变,为全连接层做准备
x=x.view(-1,self.num_flat_features(x))
# 输入x->fc1->relu,更新到x
x=F.relu(self.fc1(x))
# 输入x->fc2->relu,更新到x
x=F.relu(self.fc2(x))
# 输入x->fc3,更新到x
x=self.fc3(x)
return x
# 计算张量x的总特征量
def num_flat_features(self,x):
# 由于默认批量输入,第零维度的batch剔除
size =x.size()[1:] # all dimensions except the batch dimension
num_features =1
for s in size:
num_features*=s
return num_features
net =Net()
print(net)
#通过net.parameters()可以得到可学习的参数
params = list(net.parameters())
print(len(params))
print(params[0].size()) # all dimensions except the batch dimension
#forward函数的输入是一个autograd.Variable,输出同样也是。
input = Variable(torch.randn(1,1,32,32))
out = net(input)
print(out)
#清空所有参数的梯度的缓存,并且使用随机梯度进行反步操作:
net.zero_grad()
out.backward(torch.randn(1,10))
output =net(input)
target = Variable(torch.arange(1,11)) #假设的target :1,2,3,4,5,6,7,8,9,10
target =target.view(1,-1) # make it the same shape as output
criterion = nn.MSELoss()
loss=criterion(output,target)
print(loss)
print(loss.grad_fn) # MSELoss
print(loss.grad_fn.next_functions[0][0]) # Linear
print(loss.grad_fn.next_functions[0][0].next_functions[0][0])
# 为了将误差进行反向传播,我们只需要运行loss.backward()。
#你需要清空已经存在的梯度信息,否则现存的梯度值会被累加到下一步要计算的梯度当中去。
net.zero_grad() # zeroes the gradient buffers of all parameters
print('conv1.bias.grad before backward')
print(net.conv1.bias.grad)
loss.backward()
print('conv1.bias.grad after backward')
print(net.conv1.bias.grad)
learning_rate = 0.01
for f in net.parameters():
f.data.sub_(f.grad.data*learning_rate)
# PyTorch同样提供了很多的类似函数包括SGD,Nesterov-SGD, Adam, RMSProp等等。
# 所有的这些方法都被封装到包torch.optim中。
import torch.optim as optim
# 创建自己的optimizer
optimizer = optim.SGD(net.parameters(),lr=0.01)
# in your training loop:
optimizer.zero_grad() # zero the gradient buffers
output =net(input)
loss=criterion(output,target)
loss.backward()
optimizer.step() # 更新操作