概述
现在的CNN网络普遍都是做成通用分类网络,即一个网络要做很多种事物的分类和识别,但是仔细想想这样是不是真的合理,能不能设计一种网络,对一种输入用一种子网络去做,对另外一种输入就用另外一种子网络去做,这样做的好处就很明显,首先可以在显著增大网络规模的情况下,不会明显升高计算量;其次,我感觉这参数稀疏网络的实现方式。而在今年ICLR上,就有人提出这种网络结构OUTRAGEOUSLY LARGE NEURAL NETWORKS,这是Hinton和Jeff Dean提出的一种在语音识别上的网络结构。
核心网络结构MoE layer
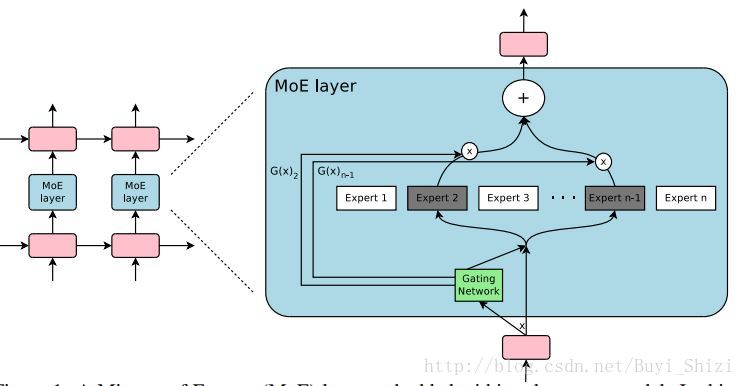
从图中我们可以看出,网络是由很多子网络组成的,每个子网络负责不同类型的输入信号,当其中几种网络做计算的时候,其他网络是完全不参与计算的,这就实现了大规模网络,小计算量的要求。
首先,Gating Network会根据输入选择不同的Export*网络,这里不只选择一种,选择的根据是由Gating Network的输出值取概率最高的前k的值,以此来选择n个Export网络中的k的网络,然后分别为每个网络分配不同的权重值,最后的输出就是:
上面就是网络的核心思想。
问题
如论文所述,上述网络存在一下的问题:
Gating Network的输出网络权重值如果在不加额外限定条件的情况下,网络效果不理想。
我们希望的是对于不同的输入,Gating Network的输出权值在对应的Export网络上大,在另外一些网络上小,但是,训练的过程中发现,事实却不是这样,网络只在一些Export网络上权值较大,在另一些网络上权值较小。为了解决这个问题,就需要在loss函数中加入额外的regularization项:
L(X)=wimportance∗CV(Importance(X))2+wload∗CV(Load(X))2
这里定义了两个额外的函数Importance: 用来衡量每个网络的重要性,在一个Batch里面,每一个输入在每个网络上都会对应一个权值
G(x) ,取一个Batch所有输入对应的权值的和,作为这个网络的Importance的值,
Importance(X)=∑x∈XG(x)
要想是所有的网络都被均匀的利用,那么每个网络的Importance的值应该差不多,即Importance(x) 的CV方差最小。Load: 在保证Importance均匀的情况下,我们要保证每个网络的在数据集中基本都会被利用到,而且利用的次数应该也是相差不大的,这里定义网络被利用的次数函数,即
G(x)i 不为0的概率P(x,i) 。在一个Batch中,Load函数计算如下:
Load(x)i=∑x∈XP(x,i)
类似,所有的网络都应该被均匀的利用,每个网络的Load值应该也是差不多的,即Load(X)i 的方差最小。
思考
上述的方法其实反应了当前CNN网络存在的问题,就是想用一个通用的模型对所有的对象进行预测分类,这就带来一定的矛盾,一边想突出网络的通用性,一边又想提高准确率。所以,合适的做法应该项上述的论文说的那样,对于某一种对象设计专门的一个子网络,最终把所有网络合并成一个大网络,在部署的过程中,对应的输入用对应的子网络计算,其他网络不参与计算,这即符合了大规模网络的要求,有自带稀疏性的特点。