论文:Honk: A PyTorch Reimplementation of Convolutional Neural Networks for Keyword Spotting
作者:Raphael Tang, Jimmy Lin
ABSTRACT
我们描述了Honk,这是TensorFlow示例中包含的用于关键字识别的卷积神经网络的开源PyTorch重新实现。 这些模型对于识别基于语音的界面(例如“ Hey Siri”)中的“命令触发器”很有用,这些界面可作为发声音频录音的显式提示,这些录音被发送到云中以进行完整的语音识别。 对Google最近发布的语音命令数据集的评估表明,我们的重新实现在准确性方面具有可比性,并为以后的关键字发现任务工作提供了起点。
1 INTRODUCTION
提供基于语音的界面的会话代理已日益成为我们日常生活的一部分,既体现在移动电话中,也体现在家用独立消费类设备中。著名的例子包括Google的助手,苹果的Siri,亚马逊的Alexa和微软的Cortana。由于模型的复杂性和计算要求,通常在云中执行完整的语音识别:记录的音频被传输到数据中心进行处理。出于实际和隐私方面的考虑,设备不会将用户语音连续流式传输到云中,而是依靠命令触发器(例如“ Hey Siri”)提供对设备的明确提示信号输入。这些言语触发器还可以确认用户话语的后续音频记录将发送到后端服务器,因此可以进行记录和分析。最近一次未达到用户隐私期望的事件涉及Google Home Mini智能扬声器,当时一位审阅者发现该设备在未经其知情或同意的情况下秘密记录了他的谈话[3]。此事件证明了设备上命令触发的重要性,这需要准确,低功耗的关键字发现功能。
Sainath和Parada [1]为TensorFlow提供了简单的卷积神经网络模型用于关键字识别和参考实现。 这些模型以及Google的语音命令数据集[2]的发布,为关键字发现任务提供了公共基准。 本文介绍了Honk,这是这些模型的PyTorch重新实现。 我们能够获得与TensorFlow参考实现相当的识别精度。
2 DATA AND TASK
Google在2017年8月发表的博客文章[2]宣布发布了语音命令数据集,以及用于卷积神经网络的训练和推理代码,以用于关键词识别。 根据知识共享许可发布的数据集包含数以千计的人组成的65,000个30秒短的一秒钟长话语。 此外,数据集还包含诸如粉红噪声,白噪声和人造声音之类的背景噪声样本。 博客非常明确地写道:

因此,此资源为我们感兴趣的关键字发现任务提供了很好的基准。在Google演示之后,我们的任务是在30个短词中区分10个,将其余20个未使用的类视为一个单独的“未知”词组。 还有一种由柔和的背景噪音组成的静音等级,以避免对静音进行错误分类。 因此,总共有12个输出标签:十个关键字,一个未知类和一个静默类。
3 IMPLEMENTATION
Honk以当地动物群命名,是公共TensorFlow关键字发现模型的开源PyTorch重新实现,该模型又基于Sainath和Parada的工作[1]。 在某些情况下,如下文所述,两者之间的细节有所不同。 我们着手进行PyTorch重新实现,主要是为了与我们研究小组的其他项目保持一致。 但是,我们认为PyTorch在模型规范的可读性方面比TensorFlow更具优势。
遵循TensorFlow参考,我们的实现包括两个截然不同的组件:输入预处理器和卷积神经网络本身进行建模。 我们所有的代码都可以在GitHub上使用,以供其他人使用。
3.1 Input Preprocessing
我们的PyTorch实现使用与TensorFlow参考相同的预处理管道(请参见图1)。 为了增强数据集并提高鲁棒性,将由白噪声,粉红噪声和人为噪声组成的背景噪声与某些输入音频混合在一起,并对样本进行随机时移。 对于特征提取,首先应用20Hz / 4kHz的带通滤波器以减少不重要的声音的影响。 然后使用30毫秒的窗口大小和10毫秒的帧偏移构造并堆叠40维梅尔频率倒谱系数(MFCC)帧。
对于实际的关键字识别,Sainath和Parada [1]提议在每帧输入的左侧堆叠23帧,在右侧堆叠8帧。 但是,我们遵循TensorFlow实现,并使用整个一秒钟的堆栈作为输入。 也就是说,我们的实现使用10毫秒的帧移位将一秒样本内的所有30毫秒窗口堆叠在一起。
3.2 Model Architecture
如图2所示,用于关键字发现的基本模型架构包括一个或多个卷积层,然后是完全连接的隐藏层,最后是softmax输出。 更具体地说,MFCC的输入: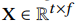 与来自第一卷积层的权重
与来自第一卷积层的权重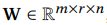 进行卷积,其中t和f是时间和频率的长度,m和r是宽度和高度 卷积滤波器的n,n是特征图的数量。 如果需要,卷积可以跨过s×v和p×q中的最大池,这些参数也影响模型的紧凑性。 每一个非线性层的激活函数是整流线性单元。
进行卷积,其中t和f是时间和频率的长度,m和r是宽度和高度 卷积滤波器的n,n是特征图的数量。 如果需要,卷积可以跨过s×v和p×q中的最大池,这些参数也影响模型的紧凑性。 每一个非线性层的激活函数是整流线性单元。

Sainath和Parada [1]提出了一个模型,该模型由两个卷积层(如上所述)组成,它们的整个模型由线性层,隐藏层和softmax层组成,它们被称为cnn-trad-fpool3。他们还设计了完整模型的紧凑型变体,可减少参数数量并增加乘数(对于低功耗设置)。我们在下面讨论完整模型及其变体的重新实现。
3.2.1 Full Model: 我们的完整模型架构是对完整TensorFlow模型的忠实重新实现,与Sainath和Parada论文中的cnn-trad-fpool3模型略有不同。 TensorFlow模型进行了一些更改,选择p = 2和q = 2并删除原始纸张中的隐藏层和线性层。令人惊讶的是,我们确认这可以提高我们任务的准确性。我们将此变体称为cnn-trad-pool2。对于我们的任务,输入大小为101×40,nlabels = 12,应用此体系结构(请参见表1中的详细信息)将导致乘法运算: 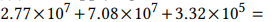
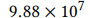
3.2.2 Compact Models: Sainath和Parada [1]提出了其完整模型的一些紧凑变体,它们在池大小和卷积层数方面有所不同。这些变型牺牲了一些精度,具有更少的参数和乘法运算,特别是针对低功耗设备。
我们重新实现了所有变体,但仅检查了TensorFlow的cnn-one-fstride4变体(请参阅表2),因为它在限制执行乘法次数的紧凑变体中获得了最佳的准确性。 对于我们的任务,此体系结构需要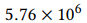 的乘法,比完整模型中的乘法数少一个数量级。 请注意,此模型仅使用一个卷积层,并且TensorFlow变体在频率或时间上没有增加步幅(请参见表2)。
的乘法,比完整模型中的乘法数少一个数量级。 请注意,此模型仅使用一个卷积层,并且TensorFlow变体在频率或时间上没有增加步幅(请参见表2)。

4 EXPERIMENTAL RESULTS
为了获得一致的比较,我们紧密复制与TensorFlow参考实施中相同的设置。 具体来说,任务是将一秒钟的简短语音分为“yes”, “no”, “up”, “down”, “left”, “right”, “on”, “off”, “stop”, “go”, silence, or unknown。
遵循TensorFlow实施后,我们将所有偏差均初始化为零,并将权重均从µ = 0且σ= 0.01的截断正态分布初始化。对于完整模型和紧凑模型,我们使用最小批量为100的随机梯度下降,学习率分别为0.001和0.01。我们还使用五个不同的随机种子运行了整个训练/验证/测试过程,从而获得了模型准确性的分布。对于完整模型,收敛需要大约30个纪元,而紧凑模型大约需要55个纪元。
与TensorFlow实现不同的是,我们还尝试使用动量为0.9的随机梯度下降训练模型。紧凑模型未能以0.01的学习速率收敛,因此该速率降低到0.001。如表3所示,我们发现动量训练可以改善结果,尤其是对于完整模型。
语音命令数据集分为训练,验证和测试集,其中训练占80%,验证占10%,测试占10%。这样就产生了大约22,000个用于训练的示例,每个2,700个用于验证和测试的示例。镜像TensorFlow实现,以确保跨运行的一致性,数据集中音频文件的哈希名称决定了样本属于哪个拆分。具体来说,文件名SHA1哈希的整数值用于将每个示例放入训练,验证或测试集中。
要通过第3.1节中描述的过程生成训练数据,Honk在每个时间段将背景噪声添加到每个样本的概率为0.8,其中从“语音命令数据集”中提供的背景噪声中随机选择噪声。在将音频转换为MFCC之前,我们的实现还执行Y毫秒的随机时移,其中Y〜Uniform [-100,100]。为了加快训练过程,所有经过预处理的输入都被缓存起来,以便在不同的训练时期重复使用。在每个时期,将驱逐30%的缓存。
我们使用由商用硬件构建的工作站来训练所有模型:双GeForce GTX 1080图形卡,i76800K CPU和64 GB RAM。这台机器足以训练本文中的模型,所有这些模型都需要少于2 GB的GPU内存。
我们的评估指标是准确性,可以简单地计算为测试集中示例中正确的强制选择预测的百分比。结果显示在表3中,我们在其中比较了完整模型和紧凑模型的PyTorch和TensorFlow实现。报告的准确度是所有单独运行的平均值,并带有95%的置信区间。我们发现不同实现的准确性是可比较的,并且置信区间重叠。这表明我们忠实地复制了TensorFlow模型。

5 OPEN-SOURCE CODEBASE
除了在我们的GitHub存储库中实现卷积神经网络模型本身之外,我们的代码库还包括许多其他功能:
- 用于记录和构建自定义语音命令,产生适当长度和格式的音频样本的实用程序。
- 测试工具,用于训练和测试TensorFlow中实现的多种模型以及Sainath和Parada提出的模型[1]
- RESTful服务,可部署经过训练的模型。服务器接受基础64编码的音频,并以语音的预测标签进行响应。该服务可用于通过本地环回发现设备上的关键字。
- 一个桌面应用程序,用于演示本文所述的关键字发现模型。客户端使用上面的REST API进行模型推断。
这些功能使任何人都可以复制本文中描述的实验,并提供一个平台,其他人可以在此平台上进行关键字发现任务。
6 CONCLUSIONS AND FUTURE WORK
在本文中,我们描述了如何在TensorFlow中实际实现Sainath和Parada [1]的两个卷积神经网络模型,并且证明了Honk是这些模型的忠实PyTorch重实现。通过Google Speech Commands数据集评估,我们发现实现的准确性是可比的。
未来工作的方向包括探索在计算能力有限的设备上进行部署,将不同的技术应用于输入数据预处理以及开发可轻松添加命令触发器的框架。
REFERENCES
[1] Tara N. Sainath and Carolina Parada. 2015. Convolutional Neural Networks for Small-Footprint Keyword Spotting. In Proceedings of the 16th Annual Conference oftheInternationalSpeechCommunicationAssociation(Interspeech2015). Dresden, Germany, 1478–1482.
[2] Pete Warden. 2017. Launching the Speech Commands Dataset. https://research. googleblog.com/2017/08/launching-speech-commands-dataset.html.
[3] Matt Weinberger. 2017. Google had to disable a feature on its new $50 smart speaker after the gadget listened in on some users. http://www.businessinsider. com/google-home-mini-accidentally-listening-to-users-2017-10.
