文章目录
持续添加哦~
一、CornerNet
目前的单阶段检测因为引入了anchor机制,获得可以和两阶段检测相媲美的精度的同时,有较高的效率。单阶段检测器在输入图像上放置了密集的 anchor ,并通过微调和回归 box 尺寸来得到最终的预测。
使用anchor的方法的缺点:
-
正负样本不均衡:大部分检测算法的anchor数量都成千上万,(DSSD中使用了多于40k个anchor,RetinaNet 中使用了多于100k个anchor)但是一张图中的目标数量并没有那么多,这就导致正样本数量会远远小于负样本,因此有了对负样本做欠采样以及 focal loss等算法来解决这个问题。
-
引入更多的超参数,比如anchor的数量、大小和宽高比等。
CornerNet 的特点:
一种新的、无anchor的单阶段目标检测方法
检测 b-box 的左上和右下角的角点
使用单个卷积神经网络来预测同一目标类别(category)中的所有实例的“左上”角点的和 heatmap、右下角点的 heatmap、每个检测到角点的 embedding vector。嵌入向量用于对属于同一目标的 corner 进行分组,也就是该网络的训练目标是实现对同一目标的“左上”和“右下”角点进行匹配,将两者预测得到相同的嵌入向量。
本文的方法很大程度地简化了网络的输出,并且无需设计相应的 anchor。
本文方法灵感源于Newell等人的文章(2017)中的多人姿态估计上下文中关联嵌入方法,结构如图1所示。

图1 将目标检测为一对b-box的角点
利用卷积网络,对所有的左上角点生成一幅热力图,对所有右下角点生成一幅热力图,并且对所有检测到的角点生成一个嵌入式向量。训练网络将属于同一目标的角点预测成相同的嵌入式向量。
文章认为,检测角点效果比检测b-box中心点或region proposal 方法更好的原因有两个:
-
b-box 的中心确定后也很难确定b-box的位置,因为其基于目标的四个边,而定位角点只基于两个边,更简单。且使用 corner pooling使其更加简单,因为该pooling方法能够对corner的先验知识进行编码。
-
角点能够提供更有效的方法来密集的离散化box空间,只需要 个角点就可以表示 个 anchor boxes。
为了平衡正负样本,在训练中使用了改进的 focal loss:
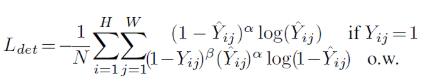
为了提高 corner point 的检测准确性,还添加了一个和类别无关的 offset map,用来弥补下采样过程引起的分辨率损失。 offset map 训练过程使用了平滑的 L1 loss:
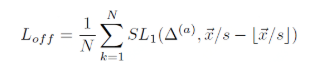
Corner Pooling:

一般情况下,物体的角点不会在物体上,我们在寻找物体的角点时,如左上角,一般会先向左看,找到最靠左的点,然后向上看,找到最靠上的点,那么这两个值组成的点便是左上角点;右下角同理。


二、ExtremeNet
Bottom-up Object Detection by Grouping Extreme and Center Points
论文中说,cornernet检测的左上和右下角点虽然取得了较好的成绩,但是这两个点并不是物体上的特征点,所以论文提出检测物体的“最左”、“最右”、“最上”和“最下”四个点,这四个点在图像特征上,更有意义,网络更好学。
Extremnet检测思路:通过标准的关键点检测网络来检测出四个极值点和1个中心点,通过几何关系对提取到的关键点进行分组,一组极值点(5个)对应一个检测结果。
是的目标检测问题转化成了一个纯粹的基于目标的外观特征的关键点估计问题,巧妙的避开了区域分类和隐含特征的学习。
Extreme and center points
传统标注使用矩形框标注目标,而矩形框一般会用左上角和右下角两个点表示。
而在ExtremeNet中,使用四点标注法,即一个目标用上下左右四个方向上的极值点来表示。额外的,通过这四个点可以计算出该目标的中心坐标。
关键点检测:
使用fully convolutional encoder-decoder network预测一个多通道heatmap,每个通道都对应一个类别的关键点。
使用HourglassNetwork作为backbone,对每张heatmap进行加权逐点逻辑回归,加权的目的是为了减少ground truth周围的虚警惩罚。
三、CenterNet
由于传统的anchor-based方法需要预设大量的 proposal 并且需要类似于 NMS 这样的后处理,大大增加了其处理复杂度。
目前已经出现的 anchor-free 的目标检测方法,比如 cornernet 和 extremenet,都在检测效率上有了一定突破,但其需要将点进行组对儿,cornernet 学习关键点的嵌入式表达,来把距离最近的点组对儿。extremenet 也需要对点进行组对儿。这会严重拉低算法的运行速度。
centernet 只检测目标的中心点,无需后续组对儿操作。
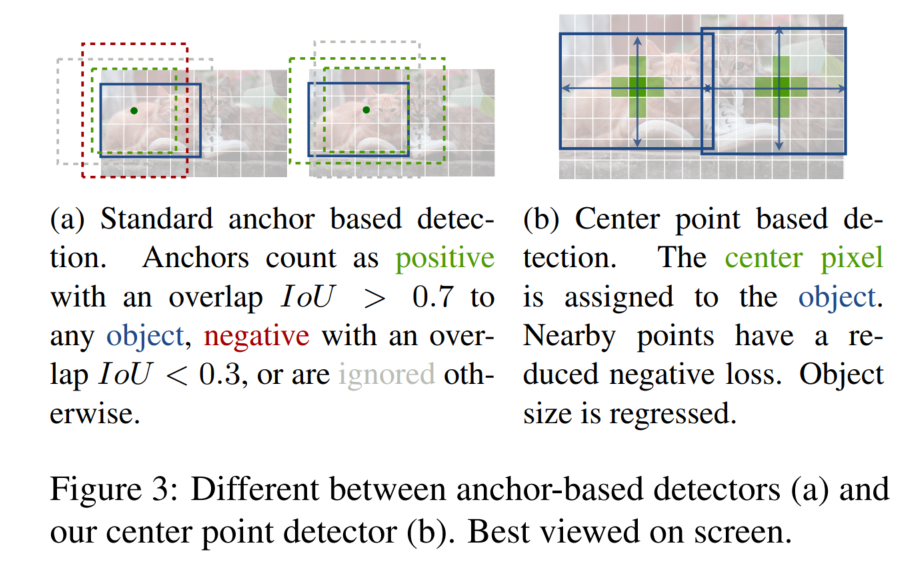
centernet 的方法接近于 anchor-based 的单阶段方法,中心点可以被看成一个形状未知的 anchor(图3所示),但还有一些区别:
- centernet 在每个物体的中心位置分配 “anchor”,而非依据IoU来分配
- 每个目标只有一个 “positive anchor”,不需要 NMS 后处理
- centernet的输出是四倍下采样后的结果,一般的目标检测器输出的是 16 倍下采样的结果,所以 centernet 不需要多个 anchor。
3.1 关键步骤:
输入:
- ,大小为 W 和 H 的三维输入图像
输出:
- ,大小为 的关键点热力图,其中,R 是输出的特征图的步长,C 是关键点类型个数。
- 当预测 时,表示检测到的是关键点
- 当预测 时,表示检测到的是背景
backbone:
- Hourglass
- ResNet
- DLA
3.2 关键点检测网络:
1、真实标签怎么得到:
- 对类别 c 中的每个真实关键点 ,计算一个低分辨率(也就是下采样4倍后的)的对应点 。
- 之后将所有真实关键点使用高斯核 投射到热力图上,其中 为与目标大小相关的标准差。
- 如果同一类别的两个高斯分布重合了,我们使用逐个像素点取最大值的方法来处理。
2、训练目标函数:像素级逻辑回归的 focal loss
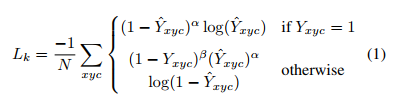

其中:
- 、 分别为focal loss 的超参数,分别设置为2和4。
- 是图像中的关键点个数,使用其进行归一化相当于将所有正例 focal loss 规范化为1。
- otherwise 情况其实表示 为负样本,也就是其值为 (0,1) 之间,左右两边不包含,也就是高斯分布上的值。
该 Focal loss 函数是针对 CenterNet 修正而来的损失函数,和 Focal Loss类似,对于easy example的中心点,适当减少其训练比重也就是loss值.
和 的作用:
-
限制 easy example 导致的梯度更新被易区分的点所主导的问题
-
当 的时候, 假如 接近1的话,说明这个是一个比较容易检测出来的点,那么 就相应比较低了。
-
当 的时候,而 接近0的时候,说明这个中心点还没有学习到,所以要加大其训练的比重,因此 就会很大, 是超参数,这里取2。
-
当 的时候,预测的 理论上也要接近于0,但如果其预测的值 接近于1的话, 的值就会比较大,加大损失,即增加这个未被正确预测的样本的损失。
的作用:
- 该项是为了平衡正负样本(弱化了实际中心点周围的其他负样本的损失比重,加强了远离实际中心点周围的负样本的损失比重,因为实际的物体只有一个中心点,其余都是负样本,但负样本相较于中心点来说显得有很多很多)
- 该项和预测的结果没有关系,只和距离中心点的远近有关系,距离中心点越近,真值 越接近于1,而 会越小,即离中心越近的点的损失会变小,会更加注重离中心较远的点的情况。
- 是高斯核生成的中心点,且中心点上 , 对于中心点周围的点,离中心点越远,则其值会慢慢下降为0。当越接近于中心点时, 会越大,则 的值会越小,反之该值会越大。
- 即对离中心点越近的点,假设 的值为0.9(otherwise情况),但预测得到其为接近于1,那显然是不对的,应该预测为0才对。此时 的值很大,loss会变大,但因为其离中心很近,预测的结果接近于1也情有可原,所以用 来使得loss减小一些。
- 对于离中心点越远的点,假设 的值为0.1(otherwise情况),但预测得到其为接近于1,那显然是不对的,要用 来惩罚,如果预测的接近于0,那么差不多了, 值就会很小。而 的值会较大,也就是使得离中心点较远的点的损失比重较大,越近的点的损失比重越小,相当于弱化了实际中心点周围的其他负样本的损失比重,加强了远离实际中心点周围的负样本的损失比重。
为了弥补输出步长所造成的离散化损失,我们对每个中心点都额外的预测了 local offset 。
所有的类别都共享相同的预测 offset,该offset是用L1 loss训练的:
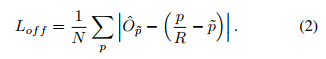
仅仅在关键点位置
上实行有监督行为,其他位置被忽略。
3.3 目标大小的回归
令 表示类别为 个的第 个目标的b-box,其中心点在 。
使用关键点估计 来预测所有中心点,另外,对每个目标 都回归其目标大小 。
为了限制计算量,对所有目标类别都使用单个尺度的预测 。
在中心点上使用和(2)相同的 L1 loss 来优化目标的尺寸:
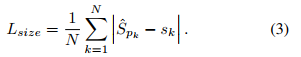
没有对尺度进行规范化,且直接使用原始的像素坐标,直接使用常量
来平衡 loss,所以,最终的整体 loss 如下:
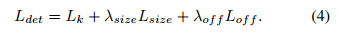
设定:
- ,
- 使用一个整体的网络来预测关键点 、偏移 、尺寸
- 该网络在每个位置一共预测 个输出(C:C个热力图,每个代表一个类别,4:2个 wh,2个 offset)
- 所有的输出共享相同的全卷积backbone网络
- 从backbone输出的特征要分别经过 3x3 卷积、Relu、1x1卷积过程
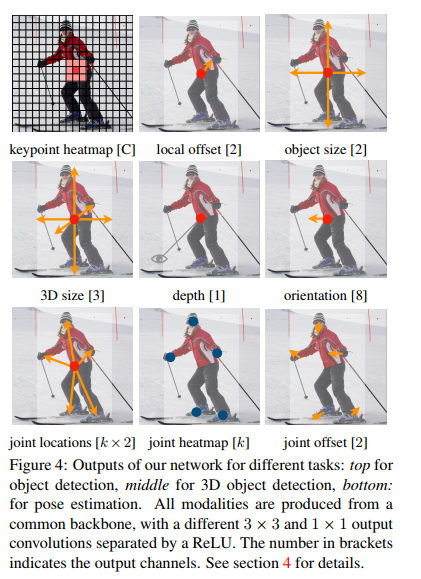
- 图4展示了网络的输出
- 图5是细节补充

3.4 从点到b-box:
推理阶段,首先抽取每个类别热力图的峰值,检测所有值大于或等于其相邻8个邻域的响应,保留前100个峰值。
令 表示类别 中,检测到的 个中心点 。
每个关键点是由整数坐标 给出的,将关键点值 作为检测置信度的衡量,并且在位置上产生一个b-box:
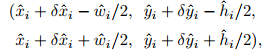
其中:
- 是预测的偏移
- 是预测大小
- 所有的输出都是直接从关键点预测的结果得到的,没有使用 IoU 或 NMS 等后处理
- 峰值关键点提取是一种有效的NMS替代方法,可以在 device 上使用3×3 max pooling 操作高效地实现。
3.5 Centernet 特点总结
优点:
-
设计模型的结构比较简单,不仅对于two-stage,对于one-stage的目标检测算法来说该网络的模型设计也是优雅简单的。
-
该模型的思想不仅可以用于目标检测,还可以用于3D检测和人体姿态识别,虽然论文中没有是深入探讨这个,但是可以说明这个网络的设计还是很好的,我们可以借助这个框架去做一些其他的任务。
-
虽然目前尚未尝试轻量级的模型,但是可以猜到这个模型对于嵌入式端这种算力比较小的平台还是很有优势的。
不足:
-
在实际训练中,如果在图像中,同一个类别中的某些物体的GT中心点,在下采样时会挤到一块,也就是两个物体在GT中的中心点重叠了,CenterNet对于这种情况也是无能为力的,也就是将这两个物体的当成一个物体来训练(因为只有一个中心点)。同理,在预测过程中,如果两个同类的物体在下采样后的中心点也重叠了,那么CenterNet也是只能检测出一个中心点,不过CenterNet对于这种情况的处理要比faster-rcnn强一些的,具体指标可以查看论文相关部分。
-
有一个需要注意的点,CenterNet在训练过程中,如果同一个类的不同物体的高斯分布点互相有重叠,那么则在重叠的范围内选取较大的高斯点。
