论文原文链接: https://www.ncbi.nlm.nih.gov/pubmed/26656583
R-CNN作为把深度学习用在目标检测任务上的开篇之作,于2014年被CVPR接收。虽然现在看来R-CNN的精度和速度已经略显不足,但文中提出的很多思想,包括后续提出的Fast R-CNN和Faster R-CNN,一直被目标检测领域的论文沿用。
摘要
目标检测在权威的PASCAL VOC竞赛数据集上的表现在最后几年趋于稳定。其中效果最好的方法是一个复杂的集成系统,它将大量的低层次图像特征和高层次环境组合在一起。我们提出了一种简单可扩展的检测算法,该方法在VOC 2012上取得了62.4%的mAP值(mean average precision),比之前的最好成绩要好超过50%。我们的方法包含了两种思想:(1)使用卷积神经网络生成候选区域来定位和分割目标;(2)当缺乏有标签训练数据时,先在辅助的任务上(这里指分类任务)有监督预训练,再在主要任务上(这里指目标检测和分割)微调,这样做可以显著提升性能。由于我们将卷积神经网络(CNN)和候选区域组合在一起,我们将模型命名为R-CNN或者Region-based Convolutional Network。完整系统的源代码可以在http://www.cs.berkeley.edu/~rbg/rcnn获得。
Introduction和Motivation
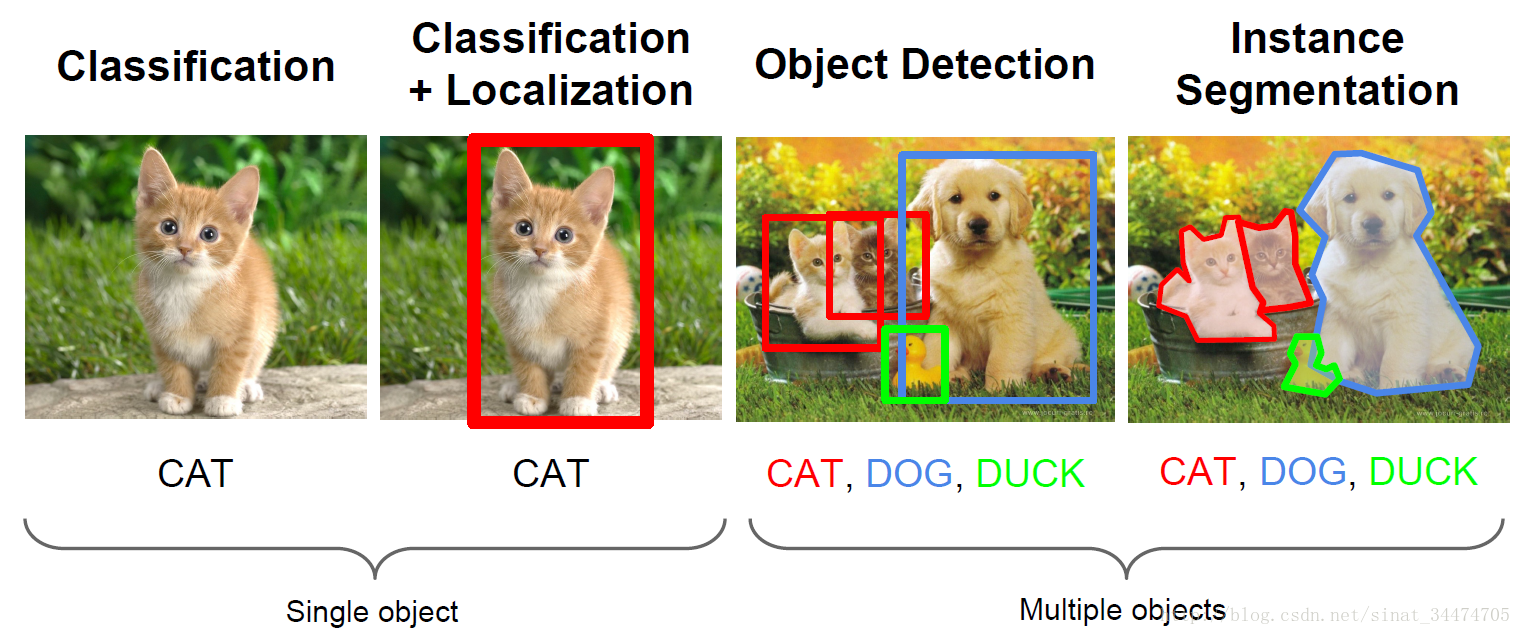
识别、定位、检测和分割
识别和定位:针对单个目标的任务,识别就是给定一张图片,要让计算机告诉你图片中是什么。而定位任务不仅要识别出图像中是什么,还要给出目标在图像中的位置信息。简单的说,就是用一个矩形框把识别的目标框出来
检测和分割:针对一幅图像中有多个目标的情况。检测任务要尽可能多的将图像中的目标用矩形框定位出来,相当于对多个目标的定位。而分割要求更严格,不再是用矩形框框出目标,而是要从像素层面上将目标和背景完全分离出来。分割的结果往往是找出目标的轮廓线。
具体如下图(图片来自斯坦福CS231课程PPT):
视觉识别中多层级特征
传统的的视觉特征提取方法如SIFT和HOG获取的是图像的低层次特征,对于一些特定的目标特征提取(比如人脸)效果很好,但是当用于大型复杂的识别任务时效果差强人意。而人的视觉识别系统是多层次的,这表明多层次的特征提取方法可能对视觉识别更有益。(卷积神经网络就是很好的一个例子)
卷积神经网络:从分类任务到检测任务
在卷积神经网络在2012年的ImageNet分类任务取得巨大成功后,一个问题产生了:能否将CNN在比赛中分类的结果用于提升目标检测任务的性能?这篇文章就很好的回答了这个问题。
文中提及了目标检测任务的两种解决思路:(1)将检测问题看作回归问题,因为检测需要返回目标的位置信息,而位置信息可以通过矩形框表示。这种方法对于单目标检测(也就是定位问题)效果应该很好,但对于多目标检测,需要对每张图片中有多少个目标做出合理的限制(后面的YOLO网络里用的就是回归思想);(2)采用生成候选框+识别的模式,即先针对一张图片生成一系列可能包含目标的候选框(如选择性搜索方法),然后用卷积神经网络提取的特征对每一个候选框做出分类(如SVM分类器)。R-CNN用的就是第二种思路。
由于用于目标检测的数据集相当于目标分类的数据集很少,R-CNN采用预训练分类模型+微调目标检测模型的机制。具体来讲,现在一个大型的分类数据集上(ILSVRC)训练一个分类模型(或者直接采用别人已经训练好的模型),然后将最后的softmax层替换为一个SVM层用于小型检测数据集(PASCAL等)微调,SVM层的作用就是判断一个候选区域框中是否包好待检测的目标。结果发现,这样做可以极大的提升模型目标检测的性能。
R-CNN模型
R-CNN有两个非常关键的地方:一是使用区域候选框(Region Proposal)并用CNN对其做特征提取;二是使用预训练模型。因为相对于目标分类,用于目标检测的标记数据很少,为了提高模型的性能,可以先用一个大型的目标分类数据预训练一个模型,再修改模型的最后一层或几层用于目标检测模型的微调。
模型结构
(1) 产生候选区域
R-CNN采用选择性搜索方法产生候选框。该方法基于区域的颜色,纹理,尺寸和空间交叠来计算区域之间的相似性并逐步合并相似区域,在模型的测试阶段,用该方法最终生成大约2000个候选框。网上关于选择性搜索的文章很多,如Selective Search for Object Detection (C++ / Python)
(2) 卷积神经网络特征提取
在生成候选框后,需要对每一个候选框做分类。文中利用卷积神经网络提取固定长度的特征用于分类。由于大多数卷积神经网络需要固定尺寸的图像输入需要将候选框拉伸成网络需要的尺寸。(一些加入金字塔池化等方法的网络可以是任意尺寸输入,但输出的特征不再是固定长度)
模型训练
使用预训练的权重可以大大提高模型收敛的速度。R-CNN采用了在ILSVRC2012分类任务上训练好的模型作为预训练模型,并将模型最后一层用于分类1000个类别的softmax层替换成替换成了(N+1)分类层,其中N为待检测的目标的类别数,1表示背景。比如对于VOC数据集,一共有20个类别的物体,所以N=20。对于正负样本,规定与grounding truth的IOU值大于0.5的为正样本,其余的为负样本。对于目标分类,每一个类别的目标都训练一个线形支持向量机进行分类。对于候选框的位置信息,采用bounding box回归进行修正以提高定位精度。
模型测试
在测试阶段,先采用选择性搜索方法在一张图片上生成大约2000个区域候选框,然后将不同尺寸的候选框统一拉伸指定大小以使用于卷积神经网络的输入。之后对于每一个类别,将卷积神经网络提取出的特征送入训练好的支持向量机(SVM)分类器来打分同时用bounding box回归来修正区域候选框。最后采用非极大值抑制(Non-maximum Suppress)来移除多余的矩形框。
Limitations
R-CNN虽然在精度上较以往的方法上取得了巨大的突破,但是也有其不足的地方:(1)训练分成多个阶段,深度学习里总是更倾向于端到端的训练,而R-CNN训练过程需要先生成候选框,再用卷积神经网络提取特征,最后训练SVM用于分类。这样一个多阶段的训练过程不仅很费事,而且需要大量的内存来存储中间结果。(2)测试速度慢,对于单张图片,需要先生成大约2000个候选框,然后送到卷积网络中得到结果,也就是说,测试单张图片需要通过同一个卷积神经网咯约2000次!这个过程是非常耗时的。
不过好在,继R-CNN之后的Fast R-CNN和Faster R-CNN优化了候选框的生成过程以及训练测试过程,在总体的性能上有显著的提升。