文章目录
一,简单线性回归实现
1,一元线性回归算法
公式:
y = ax + b
a = Σ[(x.i - x.mean)(y.i - y.mean)] / Σ[(x.i - x.mean)**2]
b = y.mean - a*x.mean
num = 0.0
d = 0.0
for x_i, y_i in zip(x, y):
num += (x_i - np.mean(x)) * (y_i - np.mean(y))
d += (x_i - np.mean(x)) **2
# 得到回归系数和截距
a = num / d
b = y_mean - a*x_mean
# 单一数据预测
y_hat = a*x +b
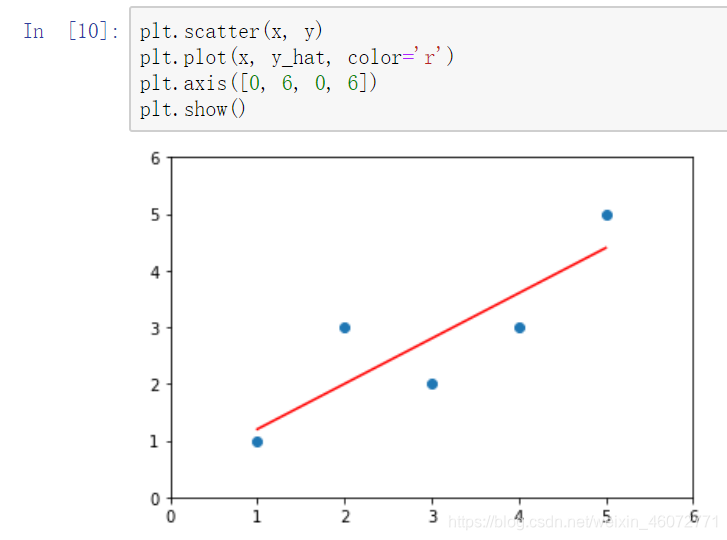
绘制出数据与回归函数
2,封装自己的简单线性回归
class SimpleLinearRegression:
def __init__(self):
self.a_ = None
self.b_ = None
def fit(self, x_train, y_train):
"""
训练参数
:param x_train:属性数据集
:param y_train: 标签数据集
:return: a 回归系数,b 截距
"""
assert x_train.ndim == 1, "一元线性回归只能有一个属性"
assert len(x_train) == len(y_train), "属性——标签一一对应"
x_mean = np.mean(x_train)
y_mean = np.mean(y_train)
num = 0.0
d = 0.0
for x_i, y_i in zip(x_train, y_train):
num += (x_i - x_mean) * (y_i - y_mean)
d += (x_i - x_mean) ** 2
self.a_ = num / d
self.b_ = y_mean - self.a_ * x_mean
return self
def predict(self, x_predict):
"""
预测一组数据
:param x_predict:预测数据集
:return: 预测结果
"""
assert x_predict.ndim == 1, "只能有一个属性"
assert self.a_ is not None and self.b_ is not None, "need use .fit()"
return np.array([self._predict(x) for x in x_predict])
def _predict(self, x_single):
"""
对单一数据进行线性回归
:param x_single: 单一预测数据
:return: 预测结果
"""
return self.a_ * x_single + self.b_
def __repr__(self):
return "一元线性规划"
使用
创建对象,导入训练数据
reg1 = SimpleLinearRegression1()
reg1.fit(x, y)
进行预测
reg1.predict(np.array([x_predict]))
>>>array([5.2])
3,使用向量运算计算回归系数
向量运算的效率更高
只改变 reg.fit()函数其他不变
def fit(self, x_train, y_train):
"""
训练参数---使用矩阵乘法代替循环
:param x_train:属性数据集
:param y_train: 标签数据集
:return: a 回归系数,b 截距
"""
assert x_train.ndim == 1, "一元线性回归只能有一个属性"
assert len(x_train) == len(y_train), "属性——标签一一对应"
"""矩阵乘法代替循环"""
x_mean = np.mean(x_train)
y_mean = np.mean(y_train)
num = (x_train - x_mean).dot(y_train - y_mean)
d = (x_train - x_mean).dot(x_train - x_mean)
self.a_ = num / d
self.b_ = y_mean - self.a_ * x_mean
return self
4,回归算法评估
数据处理
这里使用波士顿房产数据中的【房间个数-RM】
from sklearn import datasets
boston = datasets.load_boston()
boston.feature_names
>>>array(['CRIM', 'ZN', 'INDUS', 'CHAS', 'NOX', 'RM', 'AGE', 'DIS', 'RAD',
'TAX', 'PTRATIO', 'B', 'LSTAT'], dtype='<U7')
x = boston.data[:,5] # 只是用“RM”属性
y = boston.target
绘制出数据分布图
发现有红圈中的部分,可能是调查的时候调查表的range不够大,所以要去掉这些数据

爆表的的数值
np.max(y)
>>>50.0
删除
x = x[y<50.0]
y = y[y<50.0]
再次绘制数据分布图看是不是删除成功

最后把它分成训练集和测试集
(这个方法返回的顺序到底是个啥,我也不太确定QAQ)
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2)
(这样数据就处理好了)
观察数据分布和回归函数
用刚才写的函数计算回归曲线
reg = SimpleLinearRegression()
reg.fit(x_train,y_train)
>>>向量化一元线性回归
plt.scatter(x_train,y_train)
plt.plot(x_train,reg.predict(x_train),color='r')
plt.show()

MSE (均方误差)
mse_test = np.sum((y_predict - y_test)**2)/len(y_test)
RMSE(均方根误差)
from math import sqrt
rmse_test = sqrt(mse_test)
MAE(平均绝对误差)
mae_test = np.sum(np.absolute(y_predict - y_test))/len(y_test)
R Square
这个是sklearn中写入线性回归算法的
(应该这个比较厉害)
rs_test = 1 - mse_test / np.var(self.y_test)
封装自己的算法评估(没啥用)
class metrics:
def __init__(self, y_predict, y_test):
self.y_predict
self.y_test
def MSE(self):
return np.sum((self.y_predict - self.y_test)**2)/len(self.y_test)
def RMSE(self):
return self.MSE(self)**0.5
def MAE(self):
return np.sum(np.absolute(self.y_predict - self.y_test))/len(self.y_test)
def R_Square(self):
"""
线性回归中最常用的评估方法(也是sklearn中线性回归.score所用的)
:return:
"""
return 1 - self.MSE(self) / np.var(self.y_test)
def __repr__(self):
return "简单回归算法评估"
使用sklearn中的上边这些
(总感觉这几个数哪里不对,但又找不出来哪里的问题)
from sklearn.metrics import mean_squared_error
from sklearn.metrics import mean_absolute_error
from sklearn.metrics import r2_score
mean_squared_error(y_test,y_predict)
>>>54.19247280369621
mean_absolute_error(y_test,y_predict)
>>>4.955435666231134
r2_score(y_test,y_predict)
>>>0.27402866563674666
5,封装(使用向量运算)
class SimpleLinearRegression2:
def __init__(self):
self.a_ = None
self.b_ = None
def fit(self, x_train, y_train):
"""
训练参数---使用矩阵乘法代替循环
:param x_train:属性数据集
:param y_train: 标签数据集
:return: a 回归系数,b 截距
"""
assert x_train.ndim == 1, "一元线性回归只能有一个属性"
assert len(x_train) == len(y_train), "属性——标签一一对应"
"""矩阵乘法代替循环"""
x_mean = np.mean(x_train)
y_mean = np.mean(y_train)
num = (x_train - x_mean).dot(y_train - y_mean)
d = (x_train - x_mean).dot(x_train - x_mean)
self.a_ = num / d
self.b_ = y_mean - self.a_ * x_mean
return self
def predict(self, x_predict):
"""
预测一组数据
:param x_predict:预测数据集
:return: 预测结果
"""
assert x_predict.ndim == 1, "只能有一个属性"
assert self.a_ is not None and self.b_ is not None, "need use .fit()"
return np.array([self._predict(x) for x in x_predict])
def _predict(self, x_single):
"""
对单一数据进行线性回归
:param x_single: 单一预测数据
:return: 预测结果
"""
return self.a_ * x_single + self.b_
def score(self,y_test, y_predict):
mse = np.sum((y_predict - y_test) ** 2) / len(y_test)
return 1 - mse / np.var(self.y_test)
def __repr__(self):
return "向量化一元线性规划"
二,多元线性回归算法
1,数据处理(手动星标)
这个很重点!!!
一定要在原数据前边加一个均为 “1” 的数列,对应截距
def _data_arrange(self, data):
one_col = [np.ones((len(data), 1))
return np.hstack(one_col, data])
2,封装好的回归算法
import numpy as np
class LinearRegression:
def __init__(self):
self.coef_ = None # 系数
self.interception_ = None # 截距
self._theta = None # 回归系数矩阵
def fit_normal(self, x_train, y_train):
assert x_train.shape[0] == y_train.shape[0], "数据集有问题"
x_b = self._data_arrange(x_train)
self._theta = np.linalg.inv(x_b.T.dot(x_b)).dot(x_b.T).dot(y_train)
self.interception_ = self._theta[0]
self.coef_ = self._theta[1:]
return self
def _data_arrange(self, data):
return np.hstack([np.ones((len(data), 1)), data])
def predict(self, x_predict):
new_x_predict = self._data_arrange(x_predict)
return new_x_predict.dot(self._theta)
# 跑分函数
def score(self, x_test, y_test):
y_predict = self.predict(x_test)
mse = np.sum((y_predict - y_test) ** 2) / len(y_test)
return 1 - mse / np.var(y_test)
def __repr__(self):
return "多元线性回归"
6,算法使用
依旧波士顿
boston = datasets.load_boston()
x = boston.data
y = boston.target
x = x[y<50]
y = y[y<50]
分隔出训练集和测试集
from sklearn.model_selection import train_test_split
# 比例至默认20%
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2)
数据处理完了,正式开始把~
reg = LinearRegression()
reg.fit_normal(x_train,y_train)
>>>多元线性回归
然后来检查一下算法得出的系数们
reg.coef_
>>>array([-1.05508553e-01, 3.21306705e-02, -2.22057622e-02, 6.65447557e-01,
-1.38799680e+01, 3.33985605e+00, -2.31747290e-02, -1.26679208e+00,
2.31563372e-01, -1.30477958e-02, -8.50823070e-01, 6.00080341e-03,
-3.89336930e-01])
reg.interception_
>>>36.92386748071265
reg.score(reg.predict(x_test),y_test)
>>>0.8156582602978631
三,使用梯度下降法训练线性回归算法
具体实现,详情看这里:[机器学习-P3 梯度下降法]
这里把代码先给出来吧
import numpy as np
class LinearRegression:
def __init__(self):
self.coef_ = None # 系数
self.interception_ = None # 截距
self._theta = None # 回归系数矩阵
def fit_normal(self, x_train, y_train):
"""
普通的方法训练算法
:param x_train:
:param y_train:
:return:
"""
assert x_train.shape[0] == y_train.shape[0], "数据集有问题"
x_b = self._data_arrange(x_train)
self._theta = np.linalg.inv(x_b.T.dot(x_b)).dot(x_b.T).dot(y_train)
self.interception_ = self._theta[0]
self.coef_ = self._theta[1:]
return self
def fit_gd(self, x_train, y_train, eta=0.01, n_iters=1e4):
"""
批量梯度下降法
使用归一化的数据训练线性回归算法
:param x_train:
:param y_train:
:param eta: 步幅
:param n_iters: 最大循环次数
:return:
"""
assert x_train.shape[0] == y_train.shape[0], "error"
def J(theta, x_b, y):
try:
return np.sum((y - x_b.dot(theta)) ** 2) / len(x_b)
except:
return float('inf')
def dJ(theta, x_b, y):
return x_b.T.dot(x_b.dot(theta) - y) * 2 / len(x_b)
def gradinet_descent(x_b, y, initial_theta, eta, n_iters=100, epsilon=1e-8):
theta = initial_theta
i_iters = 0
while i_iters < n_iters:
gradient = dJ(theta, x_b, y)
last_theat = theta
theta = theta - eta * gradient
if abs(J(theta, x_b, y) - J(last_theat, x_b, y)) < epsilon:
break
i_iters += 1
return theta
x_b = self._data_arrange(x_train)
initial_theta = np.zeros(x_b.shape[1])
self._theta = gradinet_descent(x_b, y_train, initial_theta, eta, n_iters)
self.interception_ = self._theta[0]
self.coef_ = self._theta[1:]
return self
def fit_sgd(self, x_train, y_train, eta=0.01, n_iters=5):
"""
随机梯度下降法
:param x_train:
:param y_train:
:param eta: 步幅
:param n_iters: 样本整体看几遍
:return:
"""
assert x_train.shape[0] == y_train.shape[0], "error"
assert n_iters >= 1, "error"
def dJ_sgd(theta, x_b_i, y_i):
return x_b.T.dot(x_b.dot(theta) - y_i) * 2
def sgd(x_b, y, initial_theta, n_iters):
t0 = 5
t1 = 50
def learning_rate(t):
return t0 / (t + t1)
theta = initial_theta
for cur_iter in range(n_iters):
indexes = np.random.permutation(len(x_b))
x_b_new = x_b[indexes]
y_new = y[indexes]
for i in range(len(x_b)):
gradinet = dJ_sgd(theta, x_b_new[i], y_new[i])
theta = theta - learning_rate(cur_iter * len(x_b) + i) * gradinet
return theta
x_b = self._data_arrange(x_train)
initial_theta = np.zeros(x_b.shape[1])
self._theta = sgd(x_b, y_train, initial_theta, eta, n_iters)
self.interception_ = self._theta[0]
self.coef_ = self._theta[1:]
return self
def _data_arrange(self, data):
"""
进行数据整理--在数据矩阵第一列加一列均为 1 得列
:param data:
:return:
"""
return np.hstack([np.ones((len(data), 1)), data])
def predict(self, x_predict):
"""
预测函数
:param x_predict:
:return:
"""
new_x_predict = self._data_arrange(x_predict)
return new_x_predict.dot(self._theta)
def score(self, x_test, y_test):
"""
使用 R Square的方法进行评估
:param x_test:
:param y_test:
:return: 跑分咯
"""
y_predict = self.predict(x_test)
mse = np.sum((y_predict - y_test) ** 2) / len(y_test)
return 1 - mse / np.var(y_test)
def __repr__(self):
return "多元线性回归"
(end~)
